glass-text-spotting
 glass-text-spotting copied to clipboard
glass-text-spotting copied to clipboard
Some questions about the evaluation index of the model
Hi,I used your tools/eval_glass.py code and the fine-tuned models you provided to evaluate Glass, but the results I got are quite different from those in your paper. The results are as follows:
 The data I used comes from MaskTextSpotterV3. According to your code, the lexicons I used also comes from MaskTextSpotterV3.
The data I used comes from MaskTextSpotterV3. According to your code, the lexicons I used also comes from MaskTextSpotterV3.
 I want to know whether there are other operations in the evaluation process, or my evaluation method is wrong?
I want to know whether there are other operations in the evaluation process, or my evaluation method is wrong?
Hi, the evaluation can shift by about 0-2 points due to threshold calibration. For instance, for TotalText None you should add to the command line the following:
INFERENCE_TH_TEST 0.5
INFERENCE_DETECTION_TH_TEST 0.7
For now, please let me know if these thresholds allow you to achieve the same results we got in the paper.
We plan to publish all thresholds and test configurations in a dedicated evaluation readme by end of next week.
Thanks!
hi, thank you for your reply,I used your threshold to re-test on totaltext, and the indicator has improved a little, but it has not reached the value in the paper.
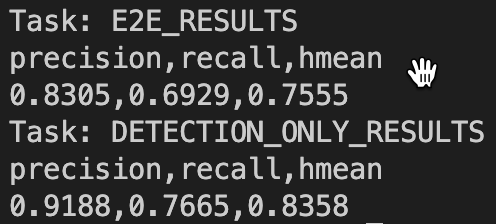 I think it may be because our GT data is inconsistent, can you provide your data or your data processing script?thanks
I think it may be because our GT data is inconsistent, can you provide your data or your data processing script?thanks