[FEATURE] Optimize order of shard tiles communication in cross mesh resharding
Background
Mentioned in issue 416, one cross mesh resharding task is composed of many "N-to-M data send task" and each "N-to-M data send task" could be handled by NCCL send/recv or NCCL broadcast. In current implementation, one ray actor executes these send/recv/broadcast NCCL instructions one by one without concurrency for one cross mesh resharding task. That means we have to wait for the first NCCL instruction to finish before launching the second NCCL instruction. When the first instruction is blocked, all the following instructions will be blocked. Therefore the order of these NCCL instructions to be executed should be carefully decided. Here is an example showing how order will affect speed.
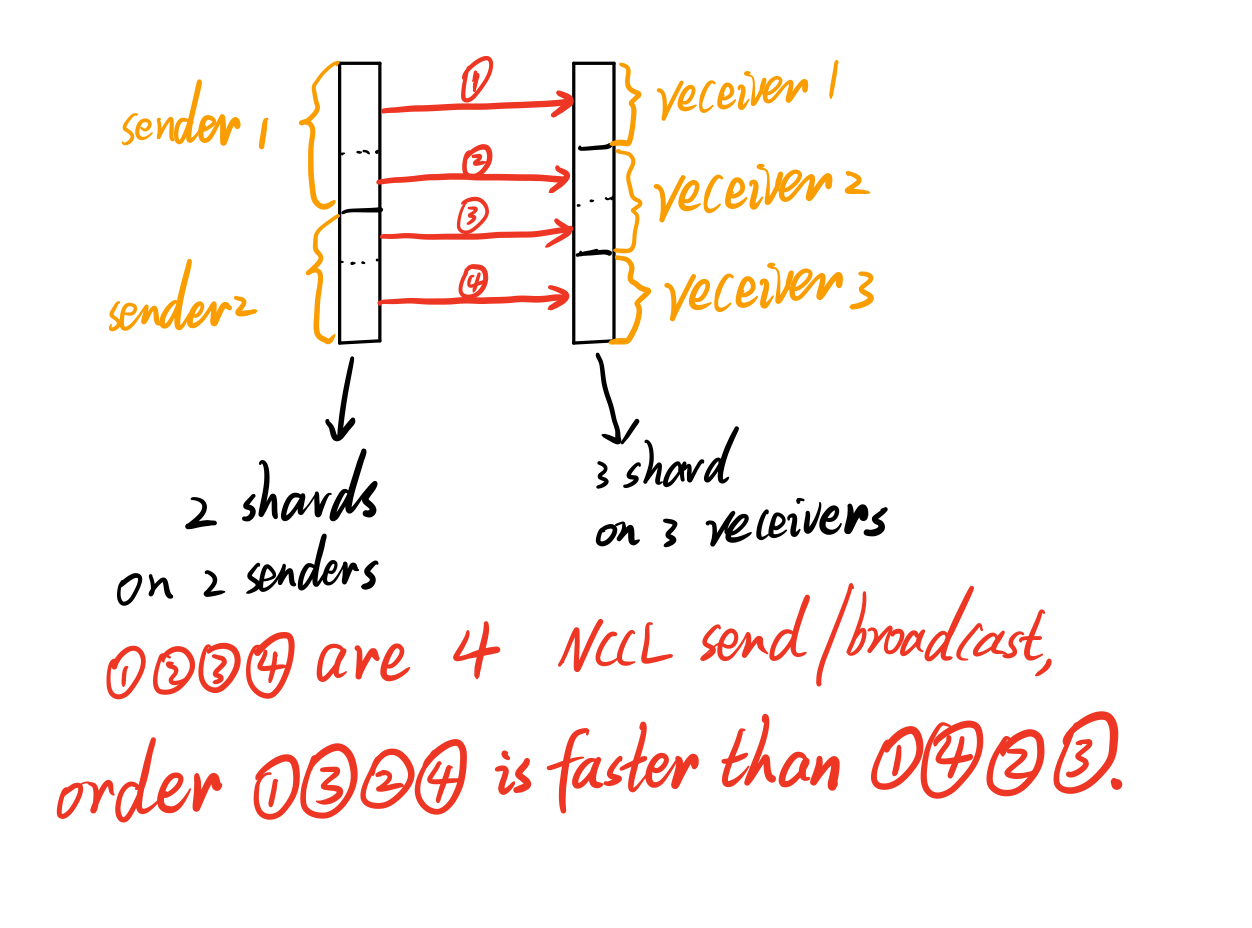
I test this resharding example and my optimization of order indeed could speed up the overall performance.
Here is the test code: src_mesh involves 2 hosts and dst_mesh involves 3 hosts.
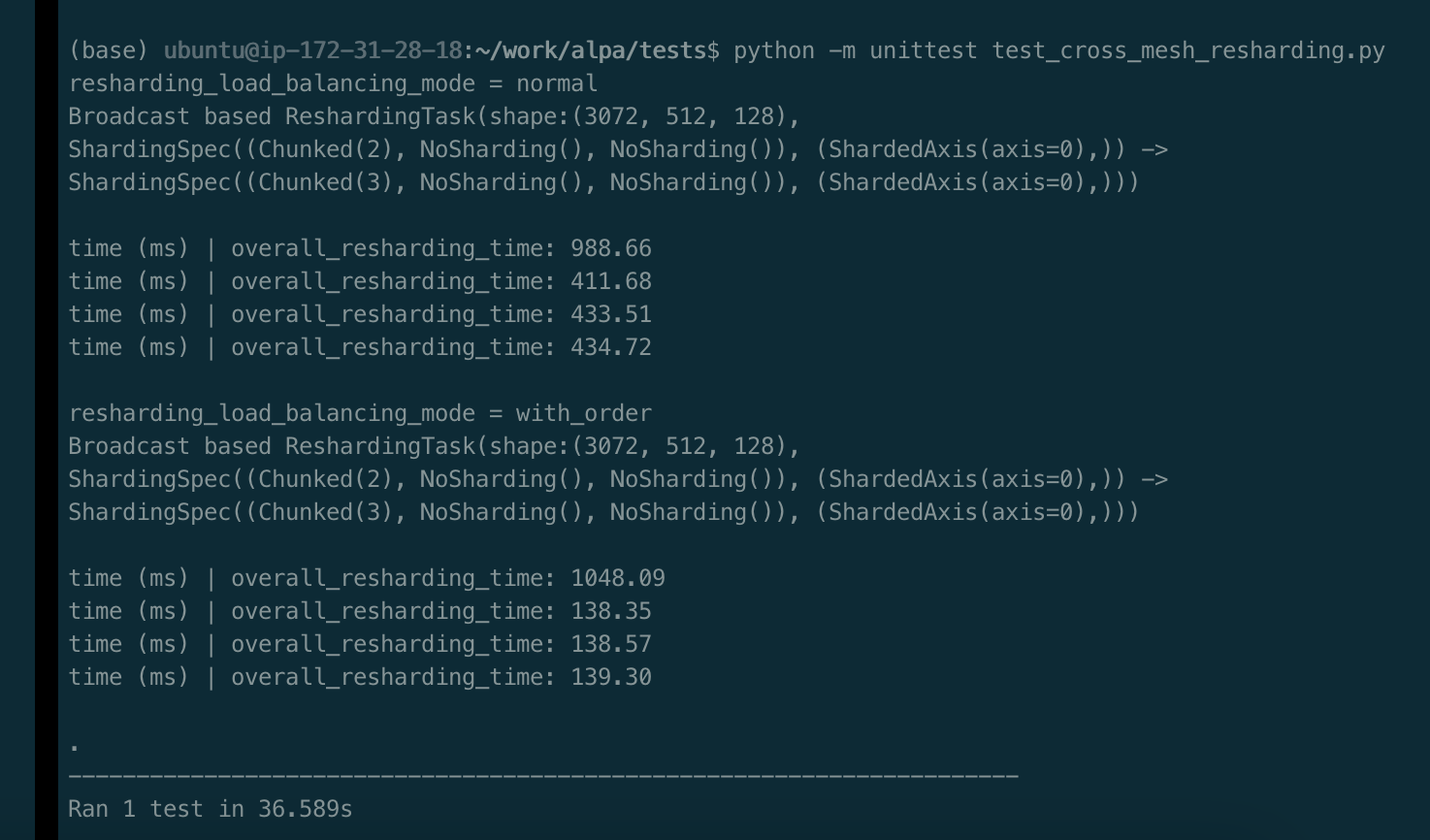
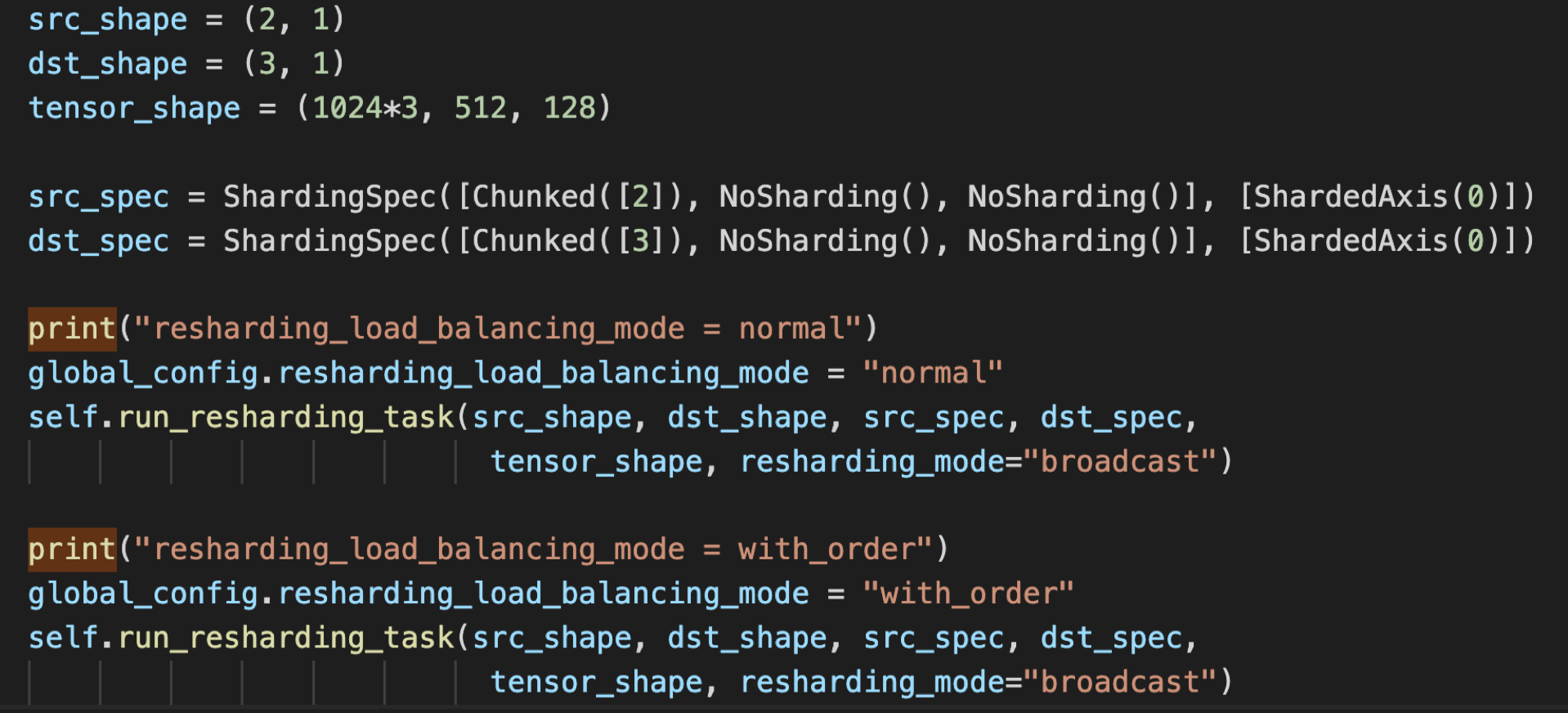 The experiment log clearly shows effectiveness of optimizing order.
The experiment log clearly shows effectiveness of optimizing order.
On top of order, we should also decide which device should be used as sender for every task. Sender selection is about load balancing among different devices/hosts and order is about load balancing along time axis.
My implementation
I define the above problem in ReshardingLoadBalancingTaskSolver and abstract it into a mathematically decent form by AbstractedLoadBalancingTaskSolver. I implement a search algorithm AbstractedLoadBalancingTaskSolverSearchAlgo for small-scale cases and a greedy algorithm AbstractedLoadBalancingTaskSolverGreedyAlgo for large-scale cases. The DFS based search algorithm is slow and could be improved by designing better pruning strategies. The greedy algorithm is not optimal and could be further improved.
Current Limitations to apply the features
- Because the bottleneck of cross mesh resharding is usually at NIC which is host level. Thus we need at least 4 hosts in one resharding task(2 in src_mesh and 2 in dst_mesh) to possibly have concurrency. Current Alpa example only involves one host as src_mesh and one host as dst_mesh. The above example involves 5 hosts. Such resharding cases never occur in current end-to-end training example of Alpa. That means this Feature could not give us immediately improvements now. Maybe if we have multiple NICs in one hosts, the features could play a more important role.
- Since the problem has been abstracted out and it is NP-hard, algorithmic solutions to it could be continuously designed and improved. Current DFS is slow (when we have 20 more hosts in one resharding) and Greedy algorithm could be hacked.
We could add this feather in main branch when we need it later. I create this PR to keep Alpa collaborators updated and gather suggestions and requirements.