TrWebOCR
 TrWebOCR copied to clipboard
TrWebOCR copied to clipboard
Published
20 hours ago •
 alisen39
alisen39
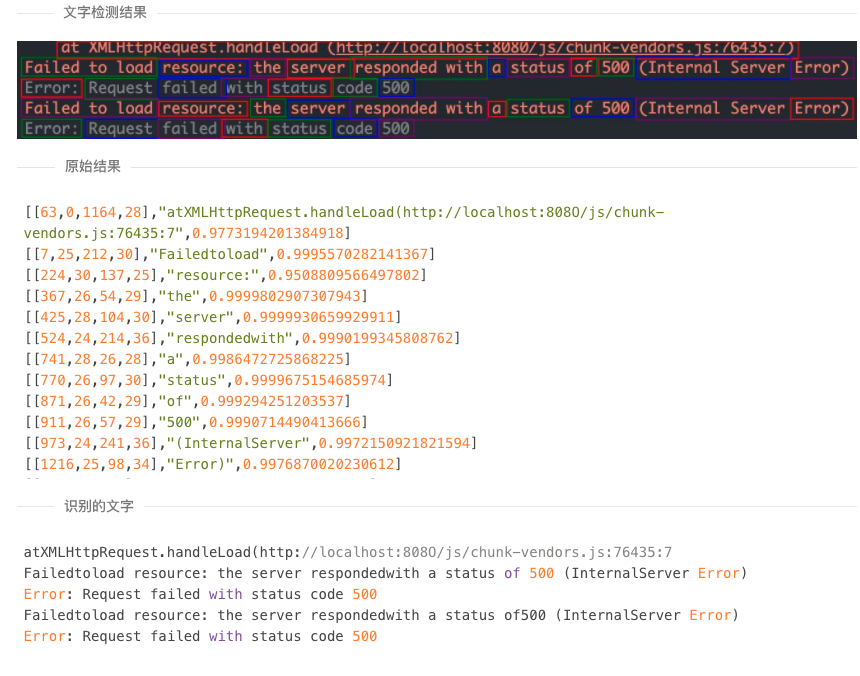
英文识别不好?
- 目前识别到同一个块里面的英文是会被去掉空格,不过大部分单词会被单独检测到一个块。可以手动在返回结果那里处理一下。上一个commit在前端做了合并同一行的文字的操作,目前识别英文的效果是这样子的:
-
识别速度主要取决于CPU跟图片大小,尝试提高CPU核心或降低图片大小
-
大写I跟小写L的问题常见于无衬线的字体,字型上太相似了,所以暂时还没有太好的解决方案
谢谢两位的帮助。有机会请你们coffee。其实昨天测试Trweb OCR不能输出英文空格后,我随即测试了tr 1.5.0,发现能正常输出英文空格。 请问如何更新呢?要全部下载,重新安装吗?下载160M的文件,还挺慢的:(
谢谢两位的帮助。有机会请你们coffee。其实昨天测试Trweb OCR不能输出英文空格后,我随即测试了tr 1.5.0,发现能正常输出英文空格。 请问如何更新呢?要全部下载,重新安装吗?下载160M的文件,还挺慢的:(
不用客气,你可以我的从码云仓库下载更新:https://gitee.com/alisen39/TrWebOCR ,速度应该不会太慢