Solutions STT actuellement utilisables
Bonjour à tous et encore merci pour tout le travail réalisé (alex, contributeurs et créateurs de plugins...).
Je reviens sur les solutions disponibles pour effectuer le STT avec openjarvis. Si l'on veut une solution où les plugins peuvent ajouter leur propres commandes, et si en plus on veut rendre ces commandes dynamiques (je pense au plugin rivescript), nous n'avons pas le choix que d'adopter une solution 'en ligne', soit BING (recommandée mais limitée à 1 mois d'utilisation gratuite), GoogleSpeach ou WIT... Hors, ces solutions deviennent toutes payantes (après un mois d'essais par exemple pour BING). Il faudrait mettre à jour la page des comparatif des reconnaissances vocales pour informer les utilisateurs de openjarvis au niveau du site openjarvis.com/content/stt
Ma question est alors: quelles sont les solutions que vous utilisez actuellement pour utiliser la reco vocale au niveau des serveurs (ou multi-room) jarvis ? Est-on destinés à n'utiliser que les applications smartphones ?? Ce qui est dommage car ce qui plaisait avec jarvis, c'était le mode de conversation 'à la volée' que l'on était capable de déclencher dans toutes les pièces ayant une instance de jarvis..
Ce n'est donc pas réellement une issue, mais c'est pour centraliser les retours d'expériences de chacun avec les nouvelles politiques des APIs de reco ... Merci par avance pour l'aide fournie, car pour ma part, je suis dans l’impasse... A+
Hello, perso je suis avec WIT mais c'est vraiment lent donc je n'utilise presque que mon appli mobile :(
Salut,
Google Speech a 60 minutes gratuites tous les mois. J'ai mis à jour l'API pour mais c'est lent car on envoie toute la requête et après seulement il fait la reconnaissance. Il faudrait que je modifie pour envoyer en streaming... Bing, selon leur page il y a 5000/requêtes par mois gratuites, y'a de la marge :p Malheureusement les "gros" du secteur avaient une API totalement gratuite le temps de la tester, rien n'est gratuit, il y a aussi des gens à payer chez eux ;-)
Si vous voulez une solution gratuite je vous invite à contribuer au projet Mozilla Common voice en Anglais pour l'instant.
Pour le multi room il y a déjà pas mal de discutions sur les issue, je vous laisse regarder
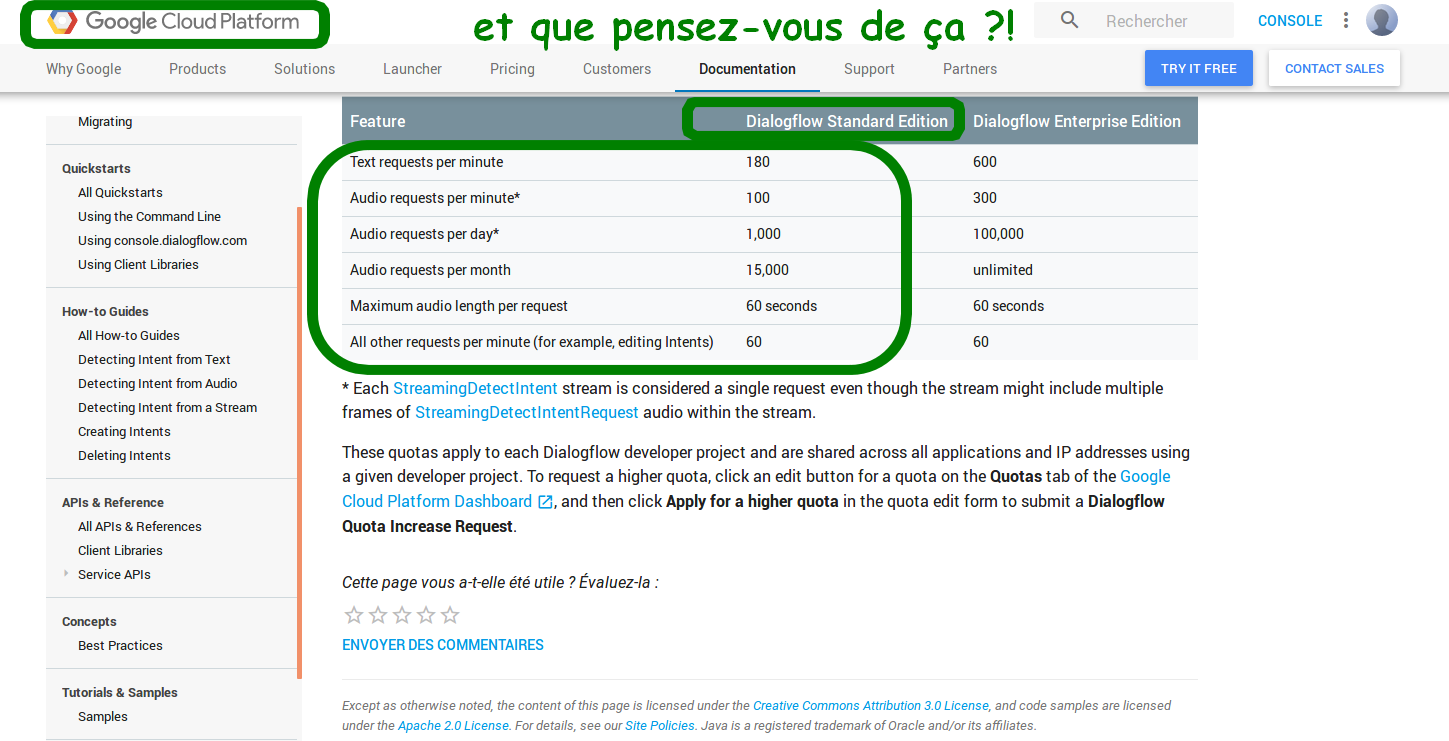
Dialogflow va traiter les phrases suivant des modèles, donc ce n'est pas vraiment un service STT au sens propre du terme.
Je viens de publier un modèle Kaldi pour le français en licence CC BY-NC-SA. https://github.com/pguyot/zamia-speech/releases/tag/20190930
Il est possible de l'utiliser avec le script de demo publié par @gooofy https://github.com/gooofy/zamia-speech https://github.com/pguyot/zamia-speech
Pour info, j'arrive à le faire fonctionner avec une grammaire réduite sur un Pi Zero dans un contexte similaire à celui de Jarvis (mais sans détection de hotword).