RuntimeError: CUDA out of memory. Tried to allocate 3.06 GiB (GPU 0; 6.00 GiB total capacity; 3.58 GiB already allocated; 1024.00 MiB free; 3.59 GiB reserved in total by PyTorch)
Anyone has or know how to solve this CUDA CPU memory allocation issue? I encountered this error when I try to perform execution for images/videos for YOLO.
Did you try to restart your PC and execute the code after? This often increases the available GPU memory.
Thanks for the reply and yes sir, I tried that. I even tried to execute the program with smaller batch size but still got the same error message.

P.S. I'm using GeForce GTX 1660 SUPER 6GB which I think should be sufficient to execute but not quite sure as this is my first time doing computer vision and machine learning.
I am not sure how much memory you actually need. I used a GPU server with 32GB for training and testing.. Maybe you should try to execute it in Google Colab, which has 13 GB of free RAM. That should work for sure.
Thanks again for the guidance. I have now managed to execute the YOLO_to_video.py using Google Colab. However, it seems like there is a problem with the model precision when I execute the script to detect for test video that I have downloaded from BDD100k dataset as the model doesn't detect or misclassified majority of the objects. Any idea what's wrong?

Also, just wondering is the output video set to be rotated as this is what I got from the code after I execute the code with test video from BDD100k dataset? The following image is a screenshot of what I got.
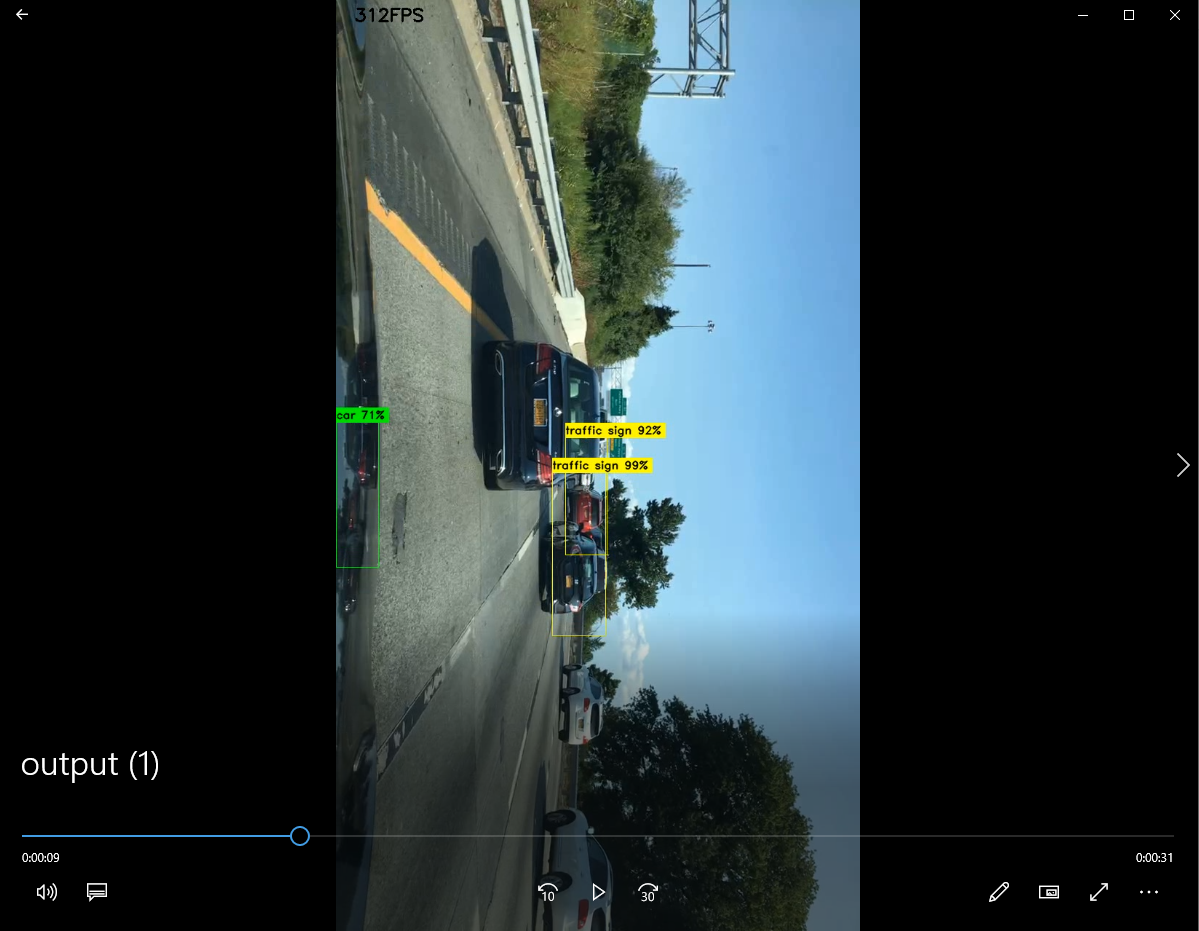
Hi regarding the model precision of YOLO. We have not achieved a good precision, since we implemented everything manually and there was a huge class imbalance for certain classes. Nevertheless our model learned to recognize some common objects, which I can also confirm on the first image you posted, although the bounding boxes are not perfectly aligned it still found the object in the image. I am sure if you use more videos to test it, it will perform well (like shown on the YouTube video https://www.youtube.com/watch?v=ANQczqZwaY4&t=5s). In general, the YOLO model is more focused on real-time performance and speed, while the Faster R-CNN model is focused on precision and accuracy.
Regarding your second problem, this is something that my teammate also encountered but for the Faster R-CNN script. I guess it has something to do with the function we are using to read in the videos from the systems, which makes the image sometimes rotated. We encountered this problem only on one out of 10 videos so I hope that it works in most cases.