QLearning-NAO_plays_Agario
 QLearning-NAO_plays_Agario copied to clipboard
QLearning-NAO_plays_Agario copied to clipboard
ROS compatible reinforcement learning algorithm based on Q-Learning that enables a NAO robot play the Agar.io game
QLearning-NAO_plays_Agario
ROS compatible reinforcement learning algorithm based on Q-Learning that enables a NAO robot play the Agar.io game. The game state acquisition (cell's positions, radius, etc) is done with computer vision because the only allowed data input is the robot camera.
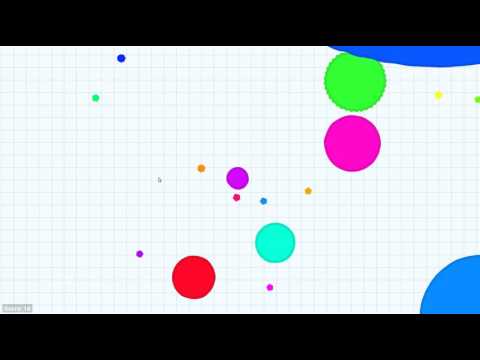
Video
Video of the developed algorithm playing with the learned model
Q-Learning
State Representation
One of the most restrictive properties of QLearning is the need to discretize the state, it can not work in continuous state. This supposes a critical problem when applying QLearning to this game because the possible number of states are infinite. The discretization strategy chosen was inspired by a robot. The idea was to equip the player's cell with a set of simulated laser sensors which determine if they collide with a dangerous agent or not (boolean value). This would give us information about where are the dangerous agents located. Then, to have information about the pellets, divide the board in 9 sections and give to the QLearning the region with maximum number of pellets (9 possible values). The number of states is (2^16)*9.

Actions
Five possible actions have been implemented: eat closest pellet (green), chase the closest smaller enemy (blue), evade enemies (red) or go to one of the other 8 possible regions (black).

Q Matrix
Q(x(t-1), u(t-1)) = random(beta, exploitation, exploration)
- exploitation: Q(x(t-1), u(t-1)) = IR + gamma * Max[Q((x(t), U(t))]
- exploration: Q(x(t-1), u(t-1)) = IR + gamma * Q(x(t), random(u(t) | u(t) in U(t))
- instantaneous reward: IR = R[x(t-1), u(t-1)] + R_still_alive + R_eat_pellet + R_eat_enemy
Execute
roslaunch agario_sele agario_sele.launch
TODO
- Improve game state acquisition:
- Improve segmentation for occlusions and overlaps.
- Improve Ray Trace algorithm.
- Decrease memory usage.
Metadata
Owner
Metadata
ROS compatible reinforcement learning algorithm based on Q-Learning that enables a NAO robot play the Agar.io game