FE_You_dont_know
 FE_You_dont_know copied to clipboard
FE_You_dont_know copied to clipboard
如何正确判断一个字符串是数值?
在网页中,我们从用户输入的内容中获取的值通常是字符串,但是有时候我们希望用户输入的内容一定要能转成数值:
<input id="userInput">
userInput.addEventListener('change', (e) => {
const value = e.target.value;
console.log(typeof value); // string
console.assert(isNumeric(value), `Not a numeric value: ${value}`);
});
即我们要实现一个isNumeric方法,判断用户输入的值是能转为数值的字符串。
我们讨论isNumeric实现前,先说一下限制用户输入的方式。
👉🏻 如果我们设置input的type为number,并不能保证输入的内容一定是数值,因为如果input的type是number,它依然可以输入多个“+“、”-”、“.”、“e”。
<input type="number" step="0.0000001" id="userInput">
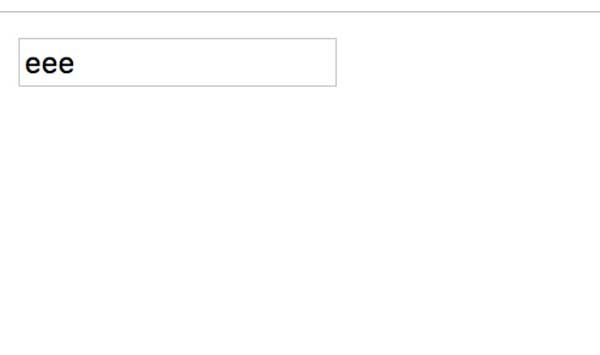 input[type=number]并不阻止输入多个e
input[type=number]并不阻止输入多个e
这是因为“+/-”(正负符号),“.”(小数点)和“e”(科学记数法)都是Number允许输入的字符。
不过如果在form提交的时候,浏览器会对input[type=number]内容再做一次检查:
<form id="myForm">
<input type="number">
<input type="submit">
</form>
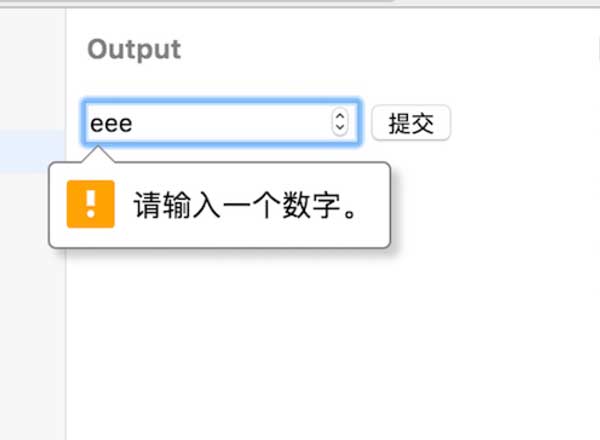
但是,不管怎样,用户还是可以通过修改页面上的元素,绕过这些检查,所以我们还是要用到isNumeric来判断用户输入的合法性。
我们先看一下isNumeric应该返回什么。
如果参考input[type=number]的规则,那么它应该支持所有合法的有穷数值写法:
function isNumeric(str) {
...
}
console.assert(isNumeric('1000'));
console.assert(isNumeric('-100.'));
console.assert(isNumeric('.1'));
console.assert(isNumeric('-3.2'));
console.assert(isNumeric('001'));
console.assert(isNumeric('+4.5'));
console.assert(isNumeric('1e3'));
console.assert(isNumeric('1e-3'));
console.assert(isNumeric('-100e-3'));
console.assert(!isNumeric('++3'));
console.assert(!isNumeric('-100..'));
console.assert(!isNumeric('3abc'));
console.assert(!isNumeric('abc'));
console.assert(!isNumeric('-3e3.2'));
console.assert(!isNumeric('Infinity'));
console.assert(!isNumeric('-Infinity'));
console.assert(!isNumeric(''));
那么具体要怎么实现呢?
parseFloat?
有同学想到用parseFloat,这个行不行呢?
function isNumeric(str) {
return !Number.isNaN(parseFloat(str));
}
这个显然是不行的,因为parseFloat('123abc')结果是123,因为parseFloat会尝试转部分数值,而忽略掉不能转数值的部分。
所以:
console.assert(!isNumeric('-100..'));
console.assert(!isNumeric('3abc'));
console.assert(!isNumeric('-3e3.2'));
这三个case是过不去的,另外这里用了Number.isNaN处理parseFloat之后的结果,由于±Infinity是数值,Number.isNaN会返回false,所以:
console.assert(!isNumeric('Infinity'));
console.assert(!isNumeric('-Infinity'));
也pass不了。
isNaN
有同学说,那我们直接使用isNaN如何?
function isNumeric(str) {
return !isNaN(str);
}
这次结果好得多,但是最后三条规则过不了:
console.assert(!isNumeric('Infinity'));
console.assert(!isNumeric('-Infinity'));
console.assert(!isNumeric(''));
±Infinity和上面的原因一样,但是为什么''也pass不了呢?这是因为isNaN会先尝试将参数转为Number,而空字符串被转为了数值0。
console.log(Number('')); // 0
这里面就不得不提一下ECMA-262规范里面[[ToNumber]]的转换规则了:
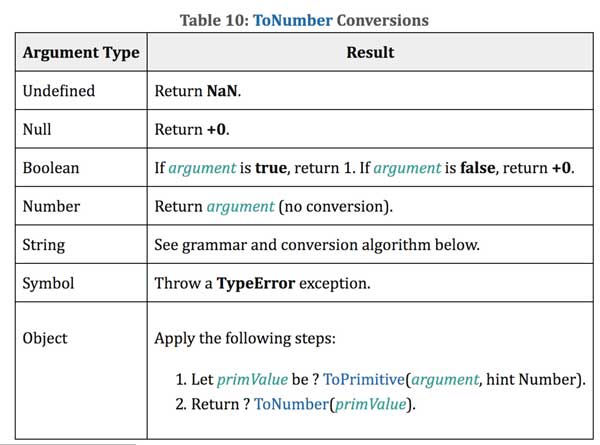
根据规则,Null、Boolean都会转成Number,Undefined被转成NaN,Undefined会被转成NaN,而Symbol直接抛TypeError...
加上空字符串''被转成0,isNaN就会有些怪异的行为了:
console.log(isNaN(undefined)); // true
console.log(isNaN(null)); // false
console.log(isNaN(true)); // false
console.log(isNaN(false)); // false
console.log(isNaN('')); // false
其实字符串除了''还有一些:
console.log(isNaN(' ')); // false
console.log(isNaN(' ')); // false
console.log(isNaN('\t')); // false
console.log(isNaN('\r')); // false
console.log(isNaN('\n')); // false
这就是为什么ES2015之后,又增加了Number.isNaN方法。
👉🏻 冷知识:isNaN方法对参数做[[ToNumber]]转换,会导致一些比较怪异的结果,所以ES2015增加了Number.isNaN,该方法不会对参数做类型转换,只要参数不是NaN,不管是什么类型,Number.isNaN一律返回false。
console.log(isNaN('abc')); // true
console.log(Number.isNaN('abc')); // false
console.log(isNaN('')); // false
console.log(Number.isNaN('')); // false
isFinite
我们把isNaN换成isFinite看看:
function isNumeric(str) {
return isFinite(str);
}
这下'±Infinity'的问题解决了,因为Number中的±Infinite和NaN的isFinite结果都返回false。
不过与isNaN一样,isFinite也一样会对参数进行类型转换,所以,这几个case问题还是存在:
console.assert(!isNumeric(''));
console.assert(!isNumeric(' '));
console.assert(!isNumeric(' '));
console.assert(!isNumeric('\t'));
console.assert(!isNumeric('\r'));
console.assert(!isNumeric('\n'));
👉🏻 冷知识:isFinite与isNaN一样,会对参数做[[ToNumber]]转换,因此对应的,ES2015也提供了一个Number.isFinite,这是不转换参数类型的版本。如果参数不是Number类型,Number.isFinite一律返回false。
console.log(isFinite('123')); // true
console.log(Number.isFinite('123')); // false
console.log(isFinite('')); // true
console.log(Number.isFinite('')); // false
好了,那么讨论到这里,最后的解决方法已经呼之欲出了。
因为对于isNumeric用法,我们只需要处理字符串,非字符串的case我们可以不管;那么我们剩下的就是处理这一堆字符串case:
console.assert(!isNumeric(''));
console.assert(!isNumeric(' '));
console.assert(!isNumeric(' '));
console.assert(!isNumeric('\t'));
console.assert(!isNumeric('\r'));
console.assert(!isNumeric('\n'));
这个有很多方式可以处理了,比如它们都匹配正则/^\s*$/,所以:
function isNumeric(str) {
return !/^\s*$/.test(str) && isFinite(str);
}
这个版本就可以通过所有的case了。
另外,这些字符串的parseFloat都是NaN,所以,也可以这样:
function isNumeric(obj) {
return !isNaN(parseFloat(obj)) && isFinite(obj);
}
实际上这个比上面那个正则的版本更好,因为这个还同时处理了非字符串的case,因为:
parseFloat(null);
parseFloat(true);
parseFloat(false);
上面这些的结果都是NaN。
实际上,上面这个版本就是著名的jQuery框架中的jQuery.isNumeric的实现方式。
因为现在不建议用isNaN和isFinite,而推荐使用Number.isNaN和Number.isFinite替代,所以一些linter的规则可能会禁止使用这两个函数,但是没有关系,因为我们可以这么写:
function isNumeric(obj) {
return !Number.isNaN(parseFloat(obj))
&& Number.isFinite(Number(obj));
}
所以,这个就是最终的版本。
原来,实现一个小小的函数isNumeric,有那么多需要注意的地方。
关于判断字符串是数值,你还有什么想法,欢迎在issue中讨论。
关于 jQuery.isNumeric:
jQuery.isNumeric() 已经被 deprecated,在未来的jQuery 4.0里会被删除。
历史上的实现变迁:
2011-11-03 jQuery 1.7.0
rdigit = /\d/,
isNumeric: function( obj ) {
return obj != null && rdigit.test( obj ) && !isNaN( obj );
},
2011-11-21 jQuery 1.7.1 2013-04-18 jQuery 2.0.0
isNumeric: function( obj ) {
return !isNaN( parseFloat(obj) ) && isFinite( obj );
},
2014-01-23 jQuery 1.11.0, 2.1.0
isNumeric: function( obj ) {
// parseFloat NaNs numeric-cast false positives (null|true|false|"")
// ...but misinterprets leading-number strings, particularly hex literals ("0x...")
// subtraction forces infinities to NaN
return obj - parseFloat( obj ) >= 0;
},
2014-05-01 jQuery 1.11.1, 2.1.1
isNumeric: function( obj ) {
// parseFloat NaNs numeric-cast false positives (null|true|false|"")
// ...but misinterprets leading-number strings, particularly hex literals ("0x...")
// subtraction forces infinities to NaN
return !jQuery.isArray( obj ) && obj - parseFloat( obj ) >= 0;
},
2014-12-17 jQuery 1.11.2, 2.1.2
isNumeric: function( obj ) {
// parseFloat NaNs numeric-cast false positives (null|true|false|"")
// ...but misinterprets leading-number strings, particularly hex literals ("0x...")
// subtraction forces infinities to NaN
// adding 1 corrects loss of precision from parseFloat (#15100)
return !jQuery.isArray( obj ) && (obj - parseFloat( obj ) + 1) >= 0;
},
2016-01-08 jQuery 1.12.0, 2.2.0
isNumeric: function( obj ) {
// parseFloat NaNs numeric-cast false positives (null|true|false|"")
// ...but misinterprets leading-number strings, particularly hex literals ("0x...")
// subtraction forces infinities to NaN
// adding 1 corrects loss of precision from parseFloat (#15100)
var realStringObj = obj && obj.toString();
return !jQuery.isArray( obj ) && ( realStringObj - parseFloat( realStringObj ) + 1 ) >= 0;
},
2016-06-09 jQuery 3.0.0
isNumeric: function( obj ) {
// As of jQuery 3.0, isNumeric is limited to
// strings and numbers (primitives or objects)
// that can be coerced to finite numbers (gh-2662)
var type = jQuery.type( obj );
return ( type === "number" || type === "string" ) &&
// parseFloat NaNs numeric-cast false positives ("")
// ...but misinterprets leading-number strings, particularly hex literals ("0x...")
// subtraction forces infinities to NaN
!isNaN( obj - parseFloat( obj ) );
},
吐槽:看完这一堆,我觉得删得好!早该删了!
似乎两个版本在非10进制数上的结果其实是一样的……所以到底动机是什么我还是不太清楚。
另外似乎所有实现都有个bug一直没发现,就是虽然可以支持 0x100,但是不支持 -0x100(当然 +'0x100' 可以返回 256,而+'-0x100'返回NaN 本身就是个坑)
文中有一个问题:
实际上这个比上面那个正则的版本更好,因为这个还同时处理了非字符串的case
~~这一点是不成立的~~,因为
function isNumeric(str) {
return !/^\s*$/.test(str) && isFinite(str);
}
这个版本其实也处理了非字符串的case。【脑子不清楚,虽然处理了,但是处理结果不是我们预期的😂】
所以我认为这个版本~~其实更好~~,代码意图很清晰。而用 isNaN 和 parseFloat 需要程序员理解额外两个函数的行为(尤其是parseFloat的行为),心智负担更大。
唯一的问题是非10进制数的坑。(就是额外允许了 0x100但是不允许-0x100,虽然感觉这个是edge case,直接忽略也不是不可以。)
所以可以改成这样:
function isNumeric(n) {
return /^[0-9.eE+-]+$/.test(n) && isFinite(n)
}
// 非常严谨的显式转型版本:
function isNumeric(n) {
const s = String(n)
if (!/^[0-9.eE+-]+$/.test(s)) return false
const v = Number(s)
return Number.isFinite(v)
}
我有些可能不太相干的想法,不知道适合不适合在这里说。

其实问题含义并不明晰,你测试的「数值」其实只是JS Number Literal 子集。开头的例子也不合适,哪种应用这么巧恰好允许用户输入JS格式的数字?那个最终版支持非十进制,这在常见的应用场景中并不合适,应该提示错误。
我觉得很多场景下这是个伪需求,即使排除了其它进制,通常面向非工程师的界面中,也很少需要支持科学计数法,可能有部分比如Parser类的工具需要这种功能。我建议明确适用场景,以免误导新手,从架构设计的角度来讲,你所说的「用户还是可以通过修改页面上的元素绕过这些检查」这种情况,前端不需要考虑,而后端正确的做法应该是如果请求的JSON Payload反序列化后得到的不是(合法范围的)Number应该直接抛出400错误,这种防御式编程并不可取。
如果把这些功能拆分成职责明确的子函数或正则表达式再组合使用可能更实用一点。
所以说到底,问题本身很简单,就只是判断 Float isNaN 和 isFinite,其它情形都应该先按具体场景需要转换成 Number 再作判断。
@CJex 文章对于 isNumeric 的含义确实在一开始写得不够明确,不过如果仔细读,可以看到这句:
如果参考input[type=number]的规则
所以实际上文章中 isNumeric 的需求是『实现与 input[type=number] 规则一致的逻辑』。为什么是这样的需求呢?看下面:
你所说的「用户还是可以通过修改页面上的元素绕过这些检查」这种情况,前端不需要考虑
这里的「用户还是可以通过修改页面上的元素绕过这些检查」其实是暗含后端进行检查的需求。而联系上文可推导出,『实现与 input[type=number] 规则一致的逻辑』『用于后端检查』。
为什么后端检查要用与前端一致的规则?
诚然,我们的确可以用并不完全一致的规则,即前端并不接受的(比如包含头尾空白),后端也可以接受,前端接受的(比如科学计数法),后端也可以不接受。但这比较容易导致用户体验的不一致。
另外一种可能的 use case 也是从用户输入中提取数字,但是不能直接用 input type=number 的情况,比如需要允许用户输入非数字的其他值。
后端正确的做法应该是如果请求的JSON Payload反序列化后得到的不是(合法范围的)Number应该直接抛出400错误
当你提到 json payload,也就是请求数据已经是合法的数字了(否则json parse就已经扔错误了),没有后续的事情了。但传数据并不一定是json,也可能传统的表单提交。抛错也和isNumeric并不矛盾。这里(后端采取和前端一致的验证逻辑)并不是防御式编程。
其它情形都应该先按具体场景需要转换成 Number 再作判断
然而这问题就是你怎样把字符串转成 Number。比如你直接 Number(x) 时,x为空白字符串会返回0。
@hax 不好意思我光看实现代码没注意到是「参考input[type=number]的规则」,我说的需求是从产品从用户角度考虑了,如果是UI框架要实现一个替代原生Number Input 功能的组件这种需求那就另说,后面的最终版仍然支持非十进制,可能作者也没想清楚真正的需求,或者也反映出了这种依赖隐蔽内置特性的实现不如正则显式判断格式靠谱。如果问后端,比如Python程序员或者DBA,就isNumeric会是什么功能,可能他们会给出不同的理解。后端是应该跟前端保持一致,但实现方式并非必须如此,你说的前端接受后端不接受也只是生造出来的场景 。至于这种情形:
比如你直接 Number(x) 时,x为空白字符串会返回0。
在现实的应用场景中,必填项可能会先判断空白,给出必填的提示,如果选填就使用默认值,这样代码职责更明确 。
然而这问题就是你怎样把字符串转成 Number
所以后面我说分成职责明确的子函数或正则表达式再组合使用可能更好一点。如果事先用正则式判断了格式,后面随便怎么转都可以,不需要依赖这些隐蔽的隐式转换,容易翻车(原帖本身就是个翻车的例子)。后面你补充的实现也用了正则,这就是我赞同的,用正则的代码意图更明确。
当然确实有些地方是需要用到这样的isNumeric,比如Web框架在反序列化参数Parsing时本身需要最大化处理,这就另说了。总之明确职责更好。
我说的「这种防御式编程不可取」也是被后面的「实际上这个比上面那个正则的版本更好,因为这个还同时处理了非字符串的case」误导了,不管前端后端,即使需要处理原始数据,isNumeric也只需要判断字符串格式,不应接受true, [0],null这些乱七八糟的情况。
其实我说这些,就是因为看到这种过于宽松的isOdd、isInteger常常被当成好的例子,变相传播了一种Bad Practice,会误导新手。
@hax 我第一个正则版本判断非字符串不行的,因为
function isNumeric(str) {
return !/^\s*$/.test(str) && isFinite(str);
}
isNumeric(false);
这个会返回true
你后面改的这两个版本比较好:
function isNumeric(n) {
return /^[0-9.eE+-]+$/.test(n) && isFinite(n)
}
// 非常严谨的显式转型版本:
function isNumeric(n) {
const s = String(n)
if (!/^[0-9.eE+-]+$/.test(s)) return false
const v = Number(s)
return Number.isFinite(v)
}
@CJex 我写这个repo的文章,定位是【前端冷知识】,用isNumeric这个例子,是为了引出后续关于isNaN、isFinite、[[ToNumber]]的规范、jQuery实现版本这些讨论。至于产品需求这些并不作为这系列文章的主要讨论范畴。
当然不是说产品需求这些不重要,而是如果既追求这又追求那,未免重点不明,也不能突出系列的主旨。而且例子是来自实际项目的提取抽象,并不等于实际项目本身,实际上很你难找到一个十全十美的例子,既符合“项目需求”,又能突出你想让读者get到的点。
所以这篇文章主要就是讨论和input[type=number]一致的isNumeric的实现,在这里我不认为说分成子函数或组合正则就一定好,我们用编程语言写的程序,是用于人与人交流的,语义和逻辑表达一致、清晰,便于阅读和理解的代码,往往是好的代码。
我说的「这种防御式编程不可取」也是被后面的「实际上这个比上面那个正则的版本更好,因为这个还同时处理了非字符串的case」误导了,不管前端后端,即使需要处理原始数据,isNumeric也只需要判断字符串格式,不应接受true, [0],null这些乱七八糟的情况。
这个你好像说反了,第一版的正则才是过于宽松,因为输入为非字符串时会得到不可预期的结果,后面用isNaN+parseFloat会严谨一些。但是 @hax 实现的后面两个版本,在严谨的基础上加上更符合语义便于人理解的正则,当然是更好的版本。
在这里我不认为说分成子函数或组合正则就一定好,我们用编程语言写的程序,是用于人与人交流的,语义和逻辑表达一致、清晰,便于阅读和理解的代码,往往是好的代码。
@akira-cn 你的这个最终版支持非十进制,input[type=number] 并不支持,不知道这是 Feature 还是 Bug,反正我觉得这代码不如 @hax 用正则表达式的代码更易读。
function isNumeric(obj) {
return !Number.isNaN(parseFloat(obj))
&& Number.isFinite(Number(obj));
}