cocosplit
 cocosplit copied to clipboard
cocosplit copied to clipboard
--multi-class not splitting images with multiple boxes correctly
I would like to use the --multi-class option, but I noticed that it would only split the image and the first bounding box declaration into the validation set. If the image had more boxes, those would be left orphaned on the training set file. Removing the flag allows that same image to have all it's box definitions in the validation set. I checked that this same bug is in the ahmad-ra repository so it's not something that came up due to the merge
I don't know if this is the best way of fixing it, but I took the working code as an example and modified the multi-class specific one to filter_annotations in hopes of getting all the annotations for the image. That did work
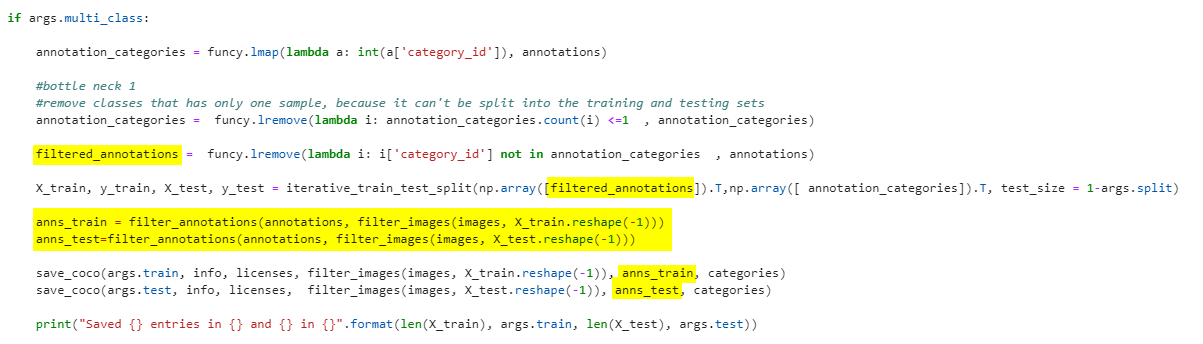
Looks like that was an incomplete fix. With that, any images that have multiple boxes in the validation set are created correctly there, but they will also be created in the training set. The problem seems to be that it's splitting the annotations properly by class, but doesn't take into account that some of those split annotations are in the same file.
I'm sure there's a better way actually using iterative_train_test_split, but here is my quick and dirty fix. It gets all the files which were set as validation and removes them from the training set before grabbing all their annotations. This does mean the split won't be as requested and will actually be very different between the two modes. This gives priority to the test set
if args.multi_class:
annotation_categories = funcy.lmap(lambda a: int(a['category_id']), annotations)
#bottle neck 1
#remove classes that has only one sample, because it can't be split into the training and testing sets
annotation_categories = funcy.lremove(lambda i: annotation_categories.count(i) <=1 , annotation_categories)
filtered_annotations = funcy.lremove(lambda i: i['category_id'] not in annotation_categories , annotations)
X_train, y_train, X_test, y_test = iterative_train_test_split(np.array([filtered_annotations]).T,np.array([ annotation_categories]).T, test_size = 1-args.split)
img_train = filter_images(images, X_train.reshape(-1))
img_test = filter_images(images, X_test.reshape(-1))
image_test_ids = funcy.lmap(lambda i: int(i['id']), img_test)
img_train = funcy.lremove(lambda a: int(a['id']) in image_test_ids, img_train)
anns_train = filter_annotations(annotations, img_train)
anns_test = filter_annotations(annotations, img_test)
save_coco(args.train, info, licenses, img_train, anns_train, categories)
save_coco(args.test, info, licenses, img_test, anns_test, categories)
print("Saved {} entries in {} and {} in {}".format(len(anns_train), args.train, len(anns_test), args.test))