project-m36
 project-m36 copied to clipboard
project-m36 copied to clipboard
Use more optimal structure for `Relation`
Right now Relation seems to have a naive implementation that will certainly hog lots of memory.
- It stores tuples in a list
- It keeps the name and type of every attribute for every row
With a few lens tricks you could make the API just as nice (or nicer) but with a more optimal storage profile.
I see now that the only thing kept in a list is the contents of RelationTupleSet, which is usually going be to short. So this may not be as big of a deal as I thought.
Believe it or not, the implementation used to be even more naïve! The original implementation (still available in the git history, by the way) implemented tuples using Data.Map and tuple sets using Data.Set. Some basic heap profiling revealed that I would be unlikely to ever be able to generate and store 10s of millions of even arity-1 tuples! The current layout has the least amount of overhead compared to the other implementations I tested (see bigrel), but that certainly doesn't mean there isn't room for improvement.
When a relation is created, the tuple attributes should be shared amongst all the tuples, so the only memory cost should be an additional pointer. Having the attributes within the tuple context is handy because otherwise I would need to pass the attributes around with the tuple anyway to validate and operate on tuples, for example, when processing them one-by-one (such as with a join). When constructing a new set of tuples, we do go through some gymnastics in order to ensure that the tuples' vector and attributes are all in the same order (see reorderTuple)- otherwise we would not be able to share the attributes vector.
In summary, there is certainly room for improvement here, but heap profiling has shown the current layout to be pretty good. I think we could benefit from some better data structures and strictness analysis, but I don't see off-hand how lenses would help because, if I understand the suggestion correctly, we would need to pass around the Relation to almost every function, even when relations are not strictly relevant.
Do you know if switching to pipes or conduits for tuples would reduce or increase memory usage when compared to a standard list?
Very cool! I guess you did your homework on this one. pipes and conduit don't provide any containers so you'd still have to choose between a list, vector, map, etc.
Are your benchmarks posted anywhere? They may be helpful in getting people on board with the project.
Hm, I hadn't thought of posting the results because they just compared specific internal structures. Do you think that would be of general interest? I think there is still room for internals improvements- I merely chose the best option from a pool of naïve options.
Of course, ideally, Project:M36 would be comparable to other RDBMSs. But even for now having some metrics would be helpful. For example, if someone is wondering, "Can I use this on my 500-user web app with a few thousands rows?" the metrics could help answer that question.
I see- great point. Right now, there are no documented performance characteristics. That would certainly be useful to see how Project:M36 holds up.
Right now, there are no documented performance characteristics
I got an app: 8 fields x 80000 tuples 21MB database in disk memory usage is about 200~240MB. It runs fine locally but gets killed by OOM killer in my 500MB-memory droplet. It seems that readFileDeserialise uses the memory most.
Indeed, I think that this is one area where the streaming tuples should make a big difference. Currently, we read tuple expressions from disk all-at-once, so I can see how that could blow out the memory usage.
Maybe there is some low-hanging fruit we can address on the master branch. Previously, we used zlib compression for on-disk storage, but the on-disk storage here is low, so it probably won't help.
I'll create a memory-focused benchmark which we can use going forward.
Are you willing to share a heap profile here?

Ah, I found some low-hanging fruit. While Project-M36 creates tuples with shared attributes, when reading them, it ends up with loads of duplicate attributes (one for each tuple), wasting the majority of memory. I'm working on a fix.
@YuMingLiao , could you take the 105 branch for a spin? In my example testing using "OnDiskClient", the branch reduces memory usage by an order-of-magnitude by sharing a single Attributes vector for all tuples instead of one per tuple. Still not amazing, but certainly an improvement. The memory profile shows that the actual data in the atoms now consumes the most memory.
To be clear, you will need to recreate the db from scratch since this changes the layout on-disk.
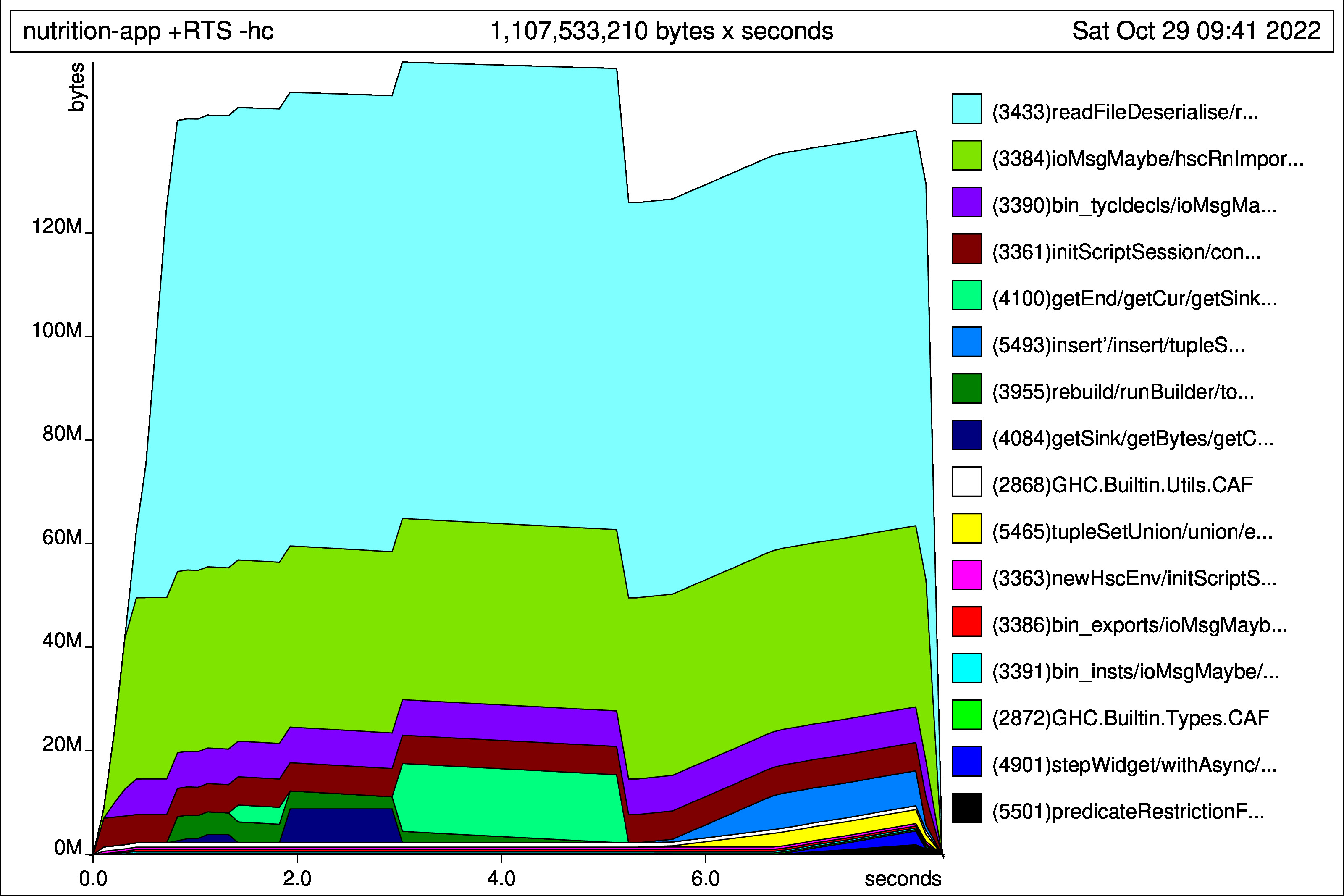
I don't understand how on-disk representation would reduce memory usage. But it's working. The memory usage is down from ~240M to ~160M. Nice punch!
I couldn't find benchmark/OnDiskClient.hs for reproducing. I guess it's in your .gitignore or what.
Oops, sorry. OnDiskClient is now pushed to the branch.
Before the patch, when we create tuple sets, each tuple references one shared Attributes blob. However, during deserialization, the attributes would be copies, one per tuple. After the patch, we deserialise the tupleset with one, shared Attributes value.
I'm doing some more profiling- there is likely more low-hanging fruit like this.
I have further reduced the memory and CPU cost of Merkle hash validation. Could you take this branch for another spin?
Using OnDiskClient, with 100,000 tuples, the on disk storage is 3.8 MB and uses 30 MB of RAM. Is this acceptable for your use-case?
At the first version in that branch, my server already started to be able to work! Thank you! I'll try the second one and report back.
Hopefully, the improvements to the hashing should reduce the memory ceiling by another order-of-magnitude.
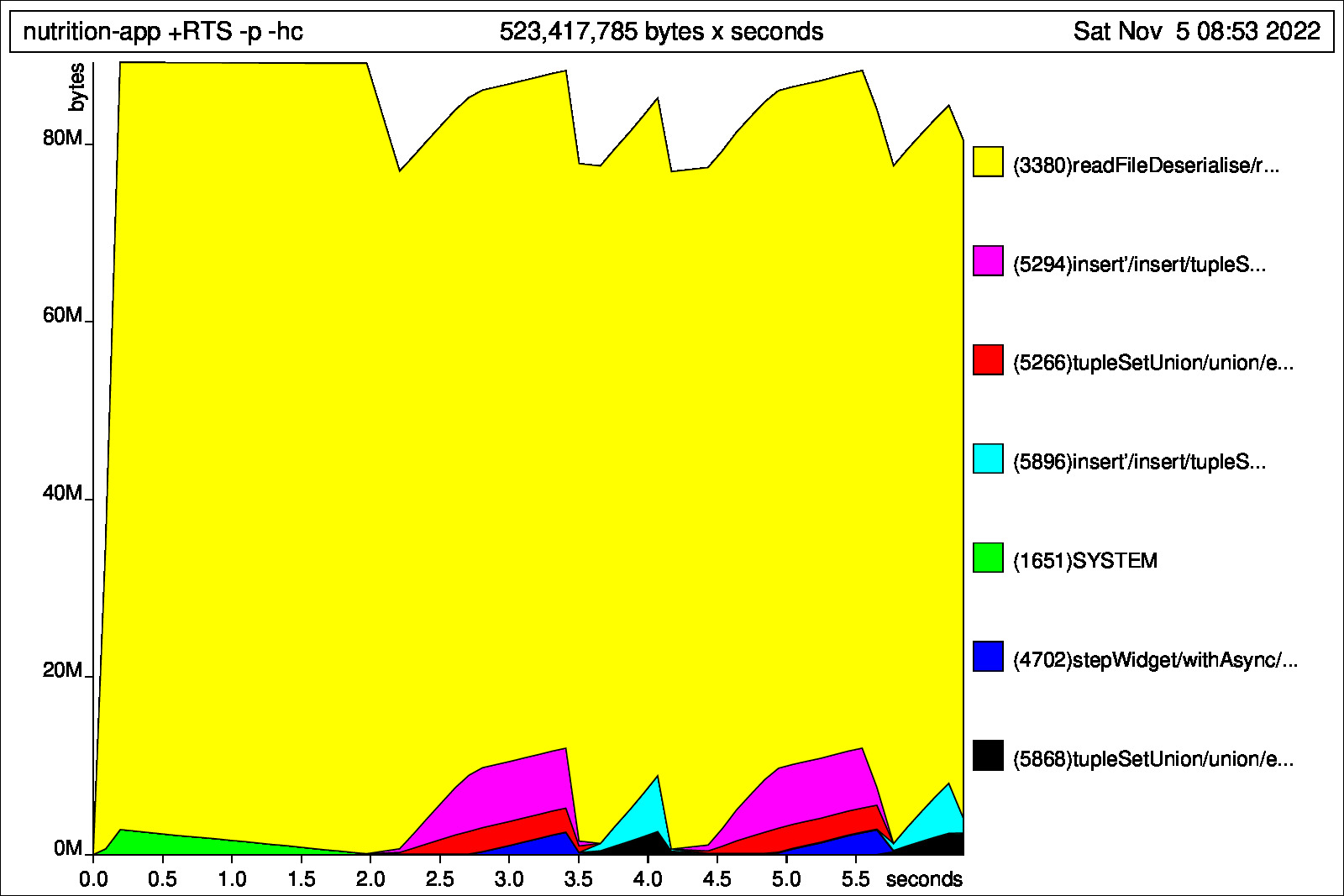
8 fields x 80000 tuples Now it's 13MB on disk. 90MB on mem.
It's pretty amazing. Thanks!
Great! I'll merge this in. There is more low-hanging fruit here, but these ratios are pretty good for now. Expect further improvements to performance and memory usage once the streamly work is complete.