Better behavior with Cluster Autoscaler
Is your feature request related to a problem? Please describe.
I'm testing ARC with cluster autoscaler (on GKE). I add the annotation safe-to-evict:true for the runners.
Occasionally cluster autoscaler reschedules the pod that is running a workflow so the workflow remains in limbo til it fails.
This happens very rarely but enough to warrant not using it.
Describe the solution you'd like
I wonder if we can toggle the safe-to-evict:true annotation when the runner is processing a job. Set it to false when it's busy, and true when it's not.
Describe alternatives you've considered
I consider not setting safe-to-evict:true annotation at all. This will not reschedule the pods but it's less than accurate node autoscaling.
@GoldenMouse Thanks for raising this up!
Occasionally cluster autoscaler reschedules the pod that is running a workflow
This is the most interesting part to me. With today's ARC, a runner pod and its runner container should terminate gracefully as long as there's enough time to do so.
How long did your GitHub Actions workflow job get stuck due to this issue running? 1min, 20min, or hours?
apiVersion: actions.summerwind.dev/v1alpha1
kind: RunnerDeployment
metadata:
name: sweetspot-runner
spec:
template:
metadata:
annotations:
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"
spec:
organization: sweetspot
# repository: sweetspot/helm-harness-poc
#dockerdWithinRunnerContainer: true
#dockerEnabled: false
group: Default
labels:
- arc
- sweetspot
resources:
requests:
cpu: 1
memory: "4Gi"
# ephemeral-storage: 10Gi
---
---
apiVersion: actions.summerwind.dev/v1alpha1
kind: HorizontalRunnerAutoscaler
metadata:
name: sweetspot-runner-autoscaler
spec:
scaleDownDelaySecondsAfterScaleOut: 300
minReplicas: 1
maxReplicas: 100
scaleTargetRef:
name: sweetspot-runner
# Uncomment the below in case the target is not RunnerDeployment but RunnerSet
#kind: RunnerSet
scaleUpTriggers:
- githubEvent:
workflowJob: {}
duration: "5m"
amount: 2
I'm running with a 0 pdb to avoid unnecessary evitcs. i.e.:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: runner-16-ramdisk
spec:
maxUnavailable: 0
selector:
matchLabels:
runner-deployment-name: runner-16-ramdisk
The runners surely wait to finish handling the job, but they will be given only so much time.
That however is configurable in kubernetes (terminationGracePeriodSeconds), one can configure how much time the pod gets to terminate by itself before kubernetes will force kill it.
I've ran workloads with terminationGracePeriodSeconds up to half an hour, with no issues.
So if that was configurable (maybe it already is?) it would be a good extension to help OPs issue.
Only concern I'd have is if moving pods around doesn't introduce possible new race condition (scenarios). That would be the risk :)
it looks like terminationGracePeriodSeconds can already be configured.
@GoldenMouse can you try setting this to about the longest running job that you have?
then the pod should get the chance to finish the job and terminate gracefully
This issue is stale because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days.
Possibly related: https://github.com/actions-runner-controller/actions-runner-controller/issues/1535
So the possible cause of this might be that our runner pod finalizer doesn't prevent SIGTERM on actions/runner and dind running within respective containers of a runner pod.
If CA or any other operator tried to terminated the pod before the node shutdown/cluster scale-in, it will terminate the important processes anyway before the runner finishes it's job.
To address it, we might need another entrypoint that handles SIGTERM gracefully.
Hey everyone! I have some progress to share.
@GoldenMouse Once #1759 lands, I think you can safely use safe-to-evict when you only run short jobs (up to approx 1 minute) on your runners.
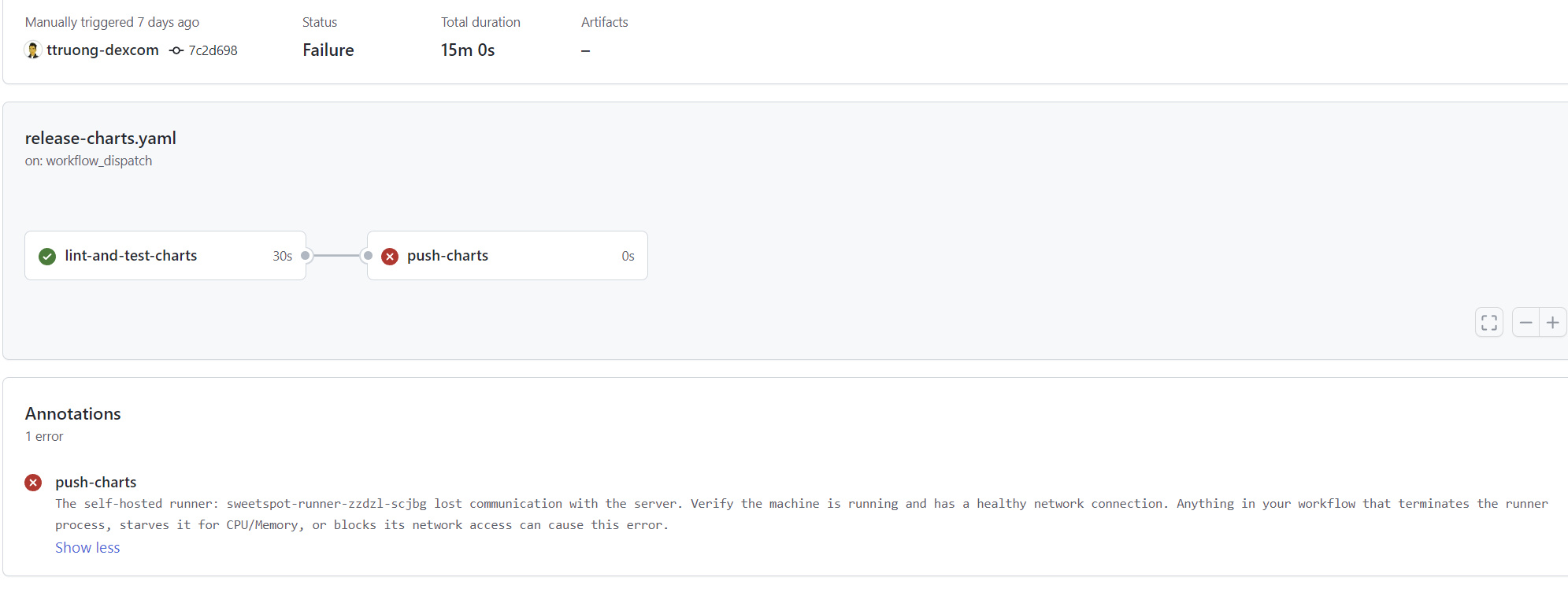
@ttruong-dexcom #1759 makes the workflow job not timeout in 10~10minutes when the node/pod terminated by cluster-autoscaler.
@genisd It turned out that we needed to do two things right. First, we need to send SIGTERM actions/runner anyway to let it gracefully shutdown. Otherwise the job will hang for 10~15 minutes in the UI (2) Second, we can let the runner wait until the job completes(but only until the node's termination time approaches) with some scripting. #1759 addresses both so with proper runner labeling and proper settings on RUNNER_GRACEFUL_STOP_TIMEOUT and terminationGracePeriodSeconds, ARC should just work great with cluster-autoscaler!
@mumoshu That's awesome. Sorry for the late response. I've handed our Runners project off to another team. I'll relay it to them so they can try it out.
This issue is stale because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days.
We're still working on https://github.com/actions-runner-controller/actions-runner-controller/pull/1759. It would be great if you could give it a try by building your own ARC runner image from the branch, and leave any feedback!
we currently have the reverse problem. We don't have safe to evict set and node won't scale down because it claims pods aren't owned by a controller.
Is there a way to "certify" the controller or is there a reason a RunnerDeployment doesn't create a Deployment as it's resulting object?
if this is too off topic should I create an issue for this or is it just a known problem and safe-to-evict is the way to go?
This issue is stale because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days.
is there a reason a RunnerDeployment doesn't create a Deployment as it's resulting object?
That's because we wanted full control over when to create/delete the pod, which is only possible via validatingwebhook or very complex via validatingwebhook when we controlled runner pods "indirectly" via deployments.
We don't have safe to evict set and node won't scale down because it claims pods aren't owned by a controller.
@snuggie12 I thought we already set an owner reference on every runner pod.. didn't we? If that's not about owner referencing, could you clarify what's needed to mark it as owned by a controller?
We don't have safe to evict set and node won't scale down because it claims pods aren't owned by a controller.
@snuggie12 I thought we already set an owner reference on every runner pod.. didn't we? If that's not about owner referencing, could you clarify what's needed to mark it as owned by a controller?
@mumoshu I presume the message either means there is something that needs done for your controller to be considered a controller (some form of registration or some piece of metadata which makes it more "official",) or when the log says "controller" it only means core kubernetes ones like a replica set controller and no custom controllers count.
@snuggie12 I've read CA code for you. Apparently you only need to add the safe-to-evict annotation on the pod to evictable according to https://github.com/kubernetes/autoscaler/blob/b5e2dcade06bcbf01f2b2b11c79deb0ab81bd1fa/cluster-autoscaler/utils/drain/drain.go#L209. Would you mind trying it?
Ah, we've already documented it https://github.com/actions-runner-controller/actions-runner-controller/blob/40eec3c7834d17fa7a76c66d82453941d577dca3/docs/detailed-docs.md?plain=1#L1079
@mumoshu Yeah, I know we can add that but then you're back to the problem of this ticket where things are turning off mid run.
BTW, I also read drain.go and I feel like it's confirmed that when they say "controller" they mean it has to be a core controller like a replicaset controller. I don't think there's a way to say your controller is a "known good" controller.
you're back to the problem of this ticket where things are turning off mid run
Why? It looks like any pod with the safe-to-evcit annotation can be terminated by CA like other pods that are managed by a controller that is known to CA.
I don't think there's a way to say your controller is a "known good" controller.
Yeah, sounds true!
This issue is stale because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days.