awesome-speech-emotion-recognition
 awesome-speech-emotion-recognition copied to clipboard
awesome-speech-emotion-recognition copied to clipboard
Published
20 hours ago •
 abikaki
abikaki
😎 Awesome lists about Speech Emotion Recognition
Awesome Speech Emotion Recognition
![]()
![]()
![]()

Topics
- What's New
- Reviews
- Databases
- Developing
- Training
- Publishing
- Learning
- Maybe Useful
What's New
| Year | Month | Database | Title | Topics |
|---|---|---|---|---|
| 2024 | February | EURASIP Journal on Audio, Speech, and Music Processing | Deep learning-based expressive speech synthesis: a systematic review of approaches, challenges, and resources | A systematic review of the literature on expressive speech synthesis models published within the last 5 years, with a particular emphasis on approaches based on deep learning |
| 2024 | February | Information Fusion | Emotion recognition and artificial intelligence: A systematic review (2014–2023) and research recommendations | A systematic review of emotion recognition from different input signals (e.g, physical, physiological) |
Reviews
| Year | Database | Title | Topics |
|---|---|---|---|
| 2023 | Neurocomputing | An ongoing review of speech emotion recognition | A comprehensive review of most popular datasets, and current machine learning and neural networks models for SER |
| 2023 | Information Fusion | Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions | A review on multimodal fusion architectures |
| 2022 | Neural Computing and Applications | Human emotion recognition from EEG-based brain-computer interface using machine learning: a comprehensive review | Human emotion recognition using EEG-based brain signals and machine learning |
| 2022 | Wireless Personal Communications | Survey of Deep Learning Paradigms for Speech Processing | Machine learning techniques for speech processing |
| 2022 | Electronics | Bringing Emotion Recognition Out of the Lab into Real Life: Recent Advances in Sensors and Machine Learning | This work reviews progress in sensors and machine learning methods and techniques |
| 2021 | IEEE Access | A Comprehensive Review of Speech Emotion Recognition Systems | SER systems' varied design components/methodologies, databases |
| 2021 | Electronics | A Review on Speech Emotion Recognition Using Deep Learning and Attention Mechanism | Extensive comparison of Deep Learning architectures, mainly on the IEMOCAP benchmark database |
| 2021 | Digital Signal Processing | A survey of speech emotion recognition in natural environment | A comprehensive survey of SER in the natural environment, various issues of SER in the natural environment, databases, feature extraction, and models |
| 2021 | Archives of Computational Methods in Engineering | Survey on Machine Learning in Speech Emotion Recognition and Vision Systems Using a Recurrent Neural Network (RNN) | A survey of deep learning algorithms in speech and vision applications and restrictions |
| 2021 | Applied Sciences | Deep Multimodal Emotion Recognition on Human Speech: A Review | An extensive review of the state-of-the-art in multimodal speech emotion recognition methodologies |
Databases
Russell's circumplex model of affect [1] is a model of human emotion that posits that all emotions can be represented as points on a two-dimensional space, with one dimension representing valence (pleasantness vs. unpleasantness) and the other dimension representing arousal (activation vs. deactivation). Valence refers to the positive and negative degree of emotion and arousal refers to the intensity of emotion. Most categorical emotions used in SER databases are based on this model
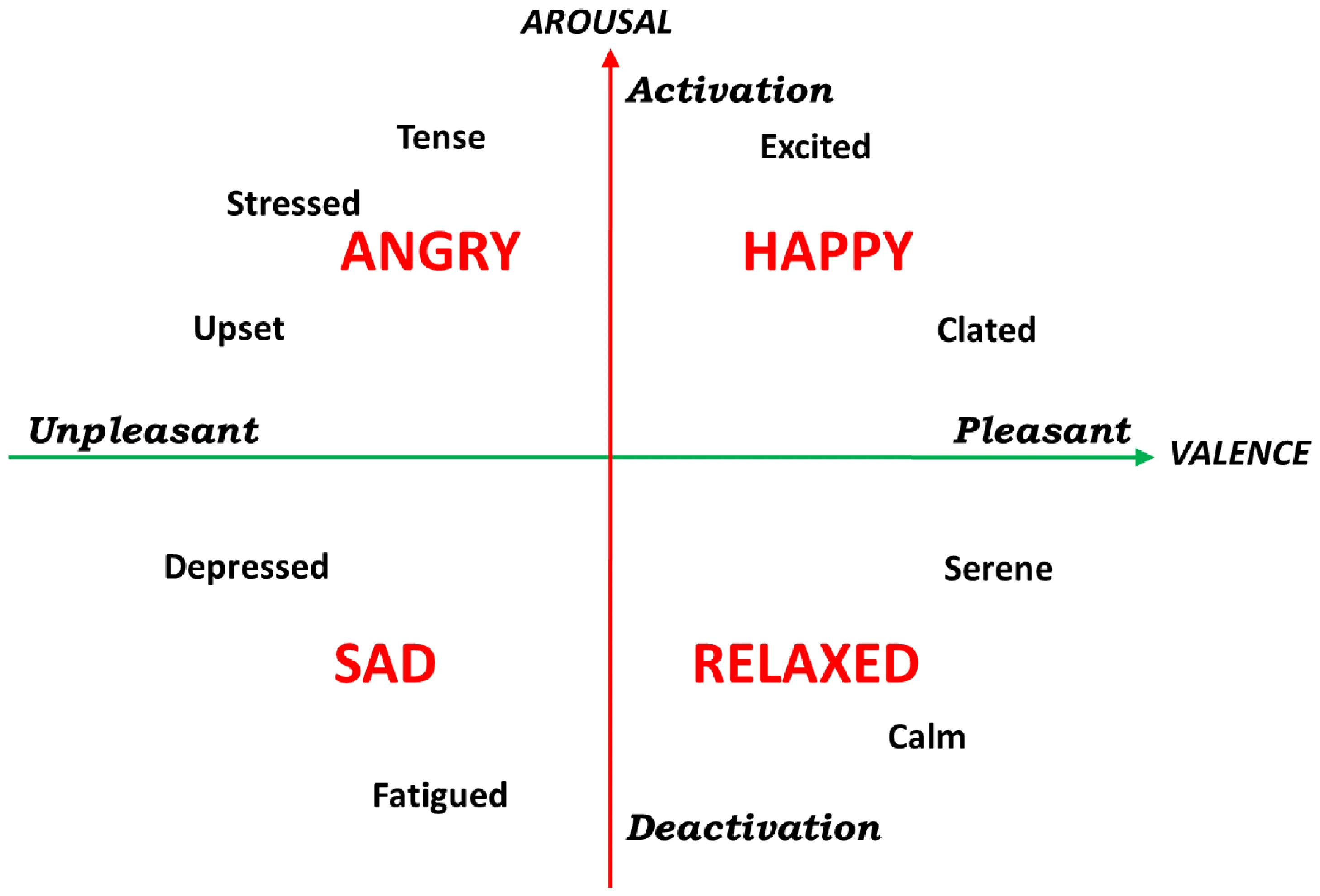
[1] Russell, J. A. (1980). A circumplex model of affect. Journal of Personality and Social Psychology, 39(6), 1161–1178. https://doi.org/10.1037/h0077714
[2] Valenza, G., Citi, L., Lanatá, A. et al. Revealing Real-Time Emotional Responses: a Personalized Assessment based on Heartbeat Dynamics. Sci Rep 4, 4998 (2014). https://doi.org/10.1038/srep04998
Datasets for Emotion Recognition
| Dataset | Lang | Size | Type | Emotions | Modalities | Resolution |
|---|---|---|---|---|---|---|
| AffectNet | N/A | ~450.000 subjects | Natural | Continuous valence/arousal values and categorical emotions: anger, contempt, disgust, fear, happiness, neutral, sadness, surprise | Visual | 425x425 |
| Belfast Naturalistic Database | Spanish | 127 multi-cultural speakers of 298 emotional clips | Natural | Amusement, anger, disgust, fear, frustration, sadness, surprise | Audio Visual |
N/A |
| Berlin Database of Emotional Speech (Emo-DB) | German | 5 male and 5 female speakers, with more than 500 utterances | Acted | Anger, boredom, disgust, fear/anxiety, happiness, neutral, sadness | Audio | Audio: 48kHz, downsampled to 16kHz Formats:.wav |
| CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) | English | 1000 gender-balanced YouTube speakers, 23500 sentences | Natural | Sentiment: Negative, weakly negative, neutral, weakly positive, positive Emotions: Anger, disgust, fear, happiness, sadness, surprise | Audio Visual Text |
N/A |
| CaFE |
French (Canadian) | 12 actors, 6 males, and 6 females, 6 sentences | Acted | Anger, disgust, fear, happiness, neutral, sadness, surprise in two different intensities | Audio | Audio: 192kHz and 48kHz Formats:.aiff |
CREMA-D  |
English | 91 actors,48 males, and 43 females, 12 sentences | Acted | Anger, disgust, fear, happy, neutral and sad / Emotional Intensity | Audio Visual |
Audio: 16kHz Formats:.wav,.mp3,.flv |
ESD  |
English (North American), Chinese (Mandarin) | 10 English (5 males, 5 females) and 10 Chinese (5 males, 5 females) speakers, 700 utterances | Acted | Anger, happiness, neutral, sadness, surprise | Audio Text |
Audio: 16kHz Formats: wav |
| Interactive Emotional Motion Capture (USC-IEMOCAP) |
English | A 12h multimodal and multispeaker (5 males and 5 females) database | Acted Elicited |
Anger, frustration, happiness, neutral, sadness as well as dimensional labels such as valence, activation and dominance | Audio Visual |
Audio: 48kHz Video: 120 fps |
| MELD: Multimodal EmotionLines Dataset | English | More than 13000 utterances from multiple speakers | Natural | Anger, disgust, fear, joy, neutral, non-neutral, sadness, surprise | Audio Visual Text |
Audio: 16bit PCM Formats: .wav |
| OMG-Emotion | English | 10 hours of YouTube videos around 1min long | Natural | Continuous valence/arousal values and categorical emotions: anger, disgust, fear, happiness, neutral, sadness, surprise | Audio Visual Text |
N/A |
| Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) |
English | A database of emotional speech and song of 12 males and 12 females | Acted | Anger, disgust, calmness, fear, happiness, neutral, sadness, surprise | Audio Visual |
Audio: 48kHz - 16bit Video: 720p Formats: .wav,.mp4 |
| SEMAINE | English | 95 sessions of human-agent interactions | Natural | 4D Emotional space | Audio Visual Text |
N/A |
| Surrey Audio-Visual Expressed Emotion (SAVEE) |
English | 4 male speakers x 480 utterances | Acted | Anger, disgust, fear, happiness, neutral, sadness, surprise | Audio Visual |
Audio: 44.1kHz - mono - 16bit Video: 256p - 60fps Formats: .wav, .avi |
| SUSAS | English | Speech under stress corpus with more than 16000 utterances from 32 speakers (13 females, 19 males) | Acted | Ten stress styles such as speaking style, single tracking task, and Lombard effect domain | Audio | 8kHz, 8bit PCM |
Datasets for Sound Classification
| Database | Year | Type | Resolution |
|---|---|---|---|
VGGSound  |
2020 | more than 210k videos for 310 audio classes | N/A, 10sec long |
AudioSet  |
2017 | 2.1 million sound clips from YouTube videos, 632 audio event classes | N/A, 10sec long |
| UrbanSound8K |
2014 | Urban sound excerpts | sampling rate may vary from file to file, duration<=4sec |
ESC-50  |
2000 | Environmental audio recordings | 44.1kHz, mono, 5sec long |
Developing
Software
- C++
- MATLAB
- Audio Toolbox | Provides tools for audio processing, speech analysis, and acoustic measurement
-
Covarep |
| A Cooperative Voice Analysis Repository for Speech Technologies
- Python Libraries
-
Aubio |
| Free, open source library for audio and music analysis
-
Librosa |
| A Python package for music and audio analysis
-
OpenSoundscape |
| A Python utility library for analyzing bioacoustic data
-
Parselmouth |
| A Pythonic interface to the Praat software
-
PyAudioAnalysis |
| A Python library that provides a wide range of audio-related functionalities focusing on feature extraction, classification, segmentation, and visualization issues
-
Pydub |
| Manipulate audio with a simple and easy high-level interface
-
SoundFile |
| A python library for audio IO processing
-
Aubio |


Tools
-
Audacity |
| Free, open source, cross-platform audio software
-
AudioGPT |
| Solve AI tasks with speech, music, sound, and talking head understanding and generation in multi-round dialogues, which empower humans to create rich and diverse audio content with unprecedented ease (paper)
-
ESPNet |
| ESPnet is an end-to-end speech processing toolkit covering end-to-end speech recognition, text-to-speech, speech translation, speech enhancement, speaker diarization, and spoken language understanding
-
Kaldi |
| Kaldi is an automatic speech recognition toolkit
-
S3PRL |
| A toolkit targeting for Self-Supervised Learning for speech processing. It supports three major features: i) Pre-training, ii) Pre-trained models (Upstream) collection, and iii) Downstream Evaluation
-
SpeechBrain |
| A PyTorch speech and all-in-one conversational AI toolkit
Training
Embeddings
- Audio/Speech
Audio/Speech Data Augmentation
- Audiomentations - A Python library for audio data augmentation
- torch-audiomentations - Fast audio data augmentation in PyTorch
Publishing
Journals
| Name | Impact Factor | Review Method | First-decision |
|---|---|---|---|
| Frontiers in Computer Science | 1.039 | Peer-review | 13w |
| International Journal of Speech Technology | 1.803 | Peer-review | 61d |
| Machine Vision and Applications | 2.012 | Peer-review | 44d |
| Applied Accoustics | 2.639 | Peer-review | 7.5w |
| Applied Sciences | 2.679 | Peer-review | 17.7d |
| Multimedia Tools and Applications | 2.757 | Peer-review | 99d |
| IEEE Sensors | 3.301 | Peer-review | 60d |
| IEEE Access | 3.367 | Binary Peer-review | 4-6w |
| Computational Intelligence and Neuroscience | 3.633 | Peer-review | 40d |
| IEEE/ACM Transactions on Audio, Speech and Language Processing | 3.919 | Peer-review | N/A |
| Neurocomputing | 5.719 | Peer-review | 74d |
| IEEE Transactions on Affective Computing | 10.506 | Peer-review | N/A |
Conferences
2023
| Name | Date | Location | More |
|---|---|---|---|
| IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) | June 2023 | Canada | |
| International Conference on Acoustics, Speech, & Signal Processing (ICASSP) | June 2023 | Greece | |
| International Speech Communication Association - Interspeech (ISCA) | August 2023 | Ireland | |
| European Signal Processing Conference (EUSIPCO) | September 2023 | Finland | :heavy_minus_sign: |
| Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE) | September 2023 | Finland | |
| International Society for Music Information Retrieval Conference (ISMIR) | November 2023 | Italy |
2024
| Name | Date | Location | More |
|---|---|---|---|
| International Conference on Acoustics, Speech, & Signal Processing (ICASSP) | April 2024 | Seoul, Korea | |
| IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) | June 2024 | Seattle, WA, USA | :heavy_minus_sign: |
| International Conference on Machine Learning (ICML) | July 2024 | Vienna, Austria | :heavy_minus_sign: |
| European Signal Processing Conference (EUSIPCO) | August 2024 | Lyon, France | :heavy_minus_sign: |
| International Speech Communication Association - Interspeech (ISCA) | September 2024 | Kos, Greece | :heavy_minus_sign: |
| Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE) | October 2024 | Tokyo, Japan | |
| International Society for Music Information Retrieval Conference (ISMIR) | November 2024 | San Fransisco, CA, USA | :heavy_minus_sign: |
| Conference and Workshop on Neural Information Processing Systems (NeurIPS) | December 2024 | Vancouver, Canada | :heavy_minus_sign: |
Learning
- Introduction to Speech Processing, 2nd Edition, Aalto University
- Mastering Audio - The Art and the Science, Robert A. Katz
- Spectral Audio Signal Processing, Julius O. Smith III
- The Scientist and Engineer's Guide to Digital Signal Processing, Steven W. Smith
Maybe Useful
Other Awesome Material
- Awesome Speaker Diarization
- Awesome-SOTA-FER a curated list of facial expression recognition in both 7-emotion classification and affect estimation
- Casual Conversations Dataset
- Music Emotion Recognition Datasets
- Room Impulse Responses Datasets
- SER Datasets
- Voice Datasets
- Project TaRSila speech datasets for Brazilian Portuguese language
- ✨❔
Perspectives
|
A picture(s) is worth a thousand words! A 2-min visual example of how we communicate emotions, our perceptions, the role of subjectivity and what is effective listening. Are emotions consistent? What about the dynamics of the context to our decisions and emotional wellness? |

|