abbshr.github.io
 abbshr.github.io copied to clipboard
abbshr.github.io copied to clipboard
分布式应用服务中的流控技术 (第一部分)
好一段时间没整理笔记了, 一是整个10月份基本上都在陪爸妈在上海和苏杭玩, 二是离开阿里之后有不少事要忙, 除了搞毕业设计就是参与新团队新项目, 也就没写什么东西. 好在有机会在又拍云做一次技术分享, 让我介绍一下以前做过的流控方案啥的, 就算做一个阶段性总结了.
Chapter 1: 为毛要做流控?
如果世界上每台服务器都可以瞬间轻松应付海量TCP连接(HTTP请求), 或者路由器效率和网络带宽高的离谱, 谁还费那心思做流控?
所以答案很简单, 资源有限. 为了让有限的资源尽量为多数人服务提供更稳定的服务, 流控技术出现了.
我们可以把流控的重要性细分为如下三点:
- Protection: 保护上游服务器, 减轻(D)DoS, TCP SYN flood等攻击带来的负面效果.
- QoS: 降低延迟, 维持系统的稳定性. 根据排队论, 延迟随附在量提升而呈指数增长.
- Controll: 按某种模式计费, 是服务调用产生商业价值.
Chapter2: 给单体架构做流控
单机单进程的传统应用优势很明显, 环境简单, 容易开发测试部署, 整合度高, 内部结构组织方便, 也非常容易理解.
为了阐明流控的核心技术, 我们首先从单进程这种最简单的场景开始.
一种最直接的思路
这种思路很直观, 就是限制在指定时间范围内的访问次数/流入流量. 每次成功访问计数器增一, 超过了重置周期(时间范围)就清零计数器, 并重置清零后的首次成功访问时间为当前.
在这里我们提前定义几个量, 后面也都会用到:
# 常量
T或interval: 限流策略中出现的时间间隔(周期).
N或threshold: 限流策略中的T时间内最大访问量(阈值).
# 变量
counter: 计数器.
fstAckTime = null # 记录counter为0时首次成功访问的时间戳
counter = 0
throttle = () ->
now = Date.now()
fstAckTime ?= now
if now - fst_ack_time > interval
counter = 0
fstAckTime = now
if counter < threshold
counter++
# granted access
else
# denied
如果以前没了解过流控, 那么基本上都是以这种做法开始. 这里面有什么问题么?
临界问题
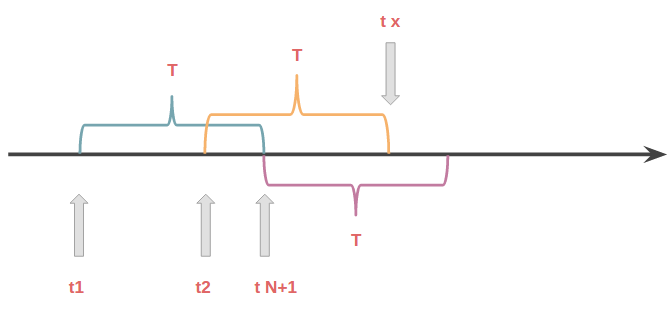
根据上图, 假如t1时刻首次访问, 然后在T时间间隔内的某一时间点t2发生了第二次访问, 紧接着从t2到t1 + T的时间内发生了N - 1次访问, 显然第N + 1次访问由于重置周期没到而被deny. 然后在t1 + N到t2 + N的时间段t2 - t1内, 由于在t N+1时刻经历了一个重置周期, 从t N + 1到t N + 1 + T的时间内可以再次发生N次访问, 同样从t N + 1到t2 + T的时间内允许至多N次的访问. 这种情况下就出现了临界问题: 从t2开始的T时间内访问了dN (d > 1)次! 破坏了我们的最大限制N.
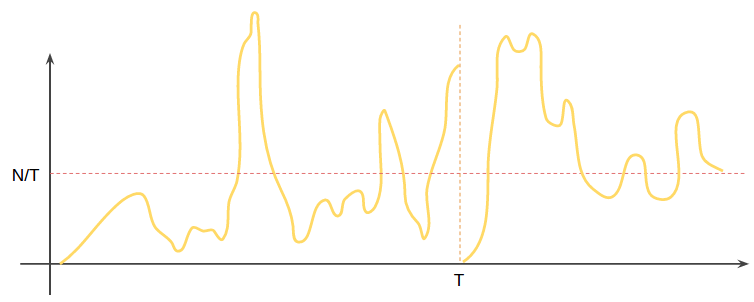
用这个方法进行流控, 可能会产生这样的速率/时间图像. 我们无法控制任意T时间内的访问量恒不大于N. 除此之外, 访问速率经常会有异常波动.
How to fix it?
这个问题该从哪里入手呢?
通过第一幅图我们可以很容易的看出问题出在"重置"时间点那里, 本来t2之后到t2 + T的时间里访问量应该控制在N以内的, 可是重置操作完全无视了这个规则, 直接全部清零了.
进一步抽象这个问题, 在流控过程中, 频繁发生变化的是counter, 来访问量时增加, 时间到了就减少, 也就是说counter减小的平均速率是N / T.
假设平均访问速率为v, 那么我们要限制的就是: v * T ≤ N, 即平均访问速率v ≤ N / T, 这是流控的核心.
而突发的重置恰恰破坏了v ≤ N / T原则. 如果此时意识到减小counter的操作或许是一个连续的过程, 那么我们就来换一种思路: 从水池注水/放水的模型重新考虑这个问题.
Leaky Bucket Algorithm
漏桶算法常见于网络流量整型中, 入口/出口网关将任意速率的流量转换为一个恒定的速率.
这里面我们不妨尝试用漏桶模型来解决我们的问题.
经过前面的猜想, 建立一个放水注水的模型比较合适. 想象counter是桶里的存水, 每次的访问操作都会往桶里加一体积的水, 而桶漏水的速度根据我们对流控的配置: N(桶的容量?)和T(一桶水漏完的时间?)计算.
刚开始桶是空的counter = 0, 当我们以小于N/T的实际速度注水(增加访问量)时, 水永远不会溢出(可以连续不断的访问, 即counter恒等于0). 一旦实际注水速度超过漏水速度时, 桶里就会产生越来越多的积水(counter开始增加), 如果不控制任意T时间的平均访问速率的话, 水最终会溢出(counter达到N, 表示访问会失败).
用编程语言描述这一过程:
# capacity为桶的容量
# duration为一桶水漏完的时间
# bucket为桶里剩余的水
# lstAckTime为上次成功访问的时间戳
bucket = 0
lstAckTime = 0
rate = capacity / duration
throttle = () ->
now = Date.now()
bucket = Math.max 0, (bucket - (now - lstAckTime) * rate)
if bucket + 1 > capacity
# deny
else
# granted access
lstAckTime = now
bucket++
这一思路可以绘制出这样的速率时间图像:
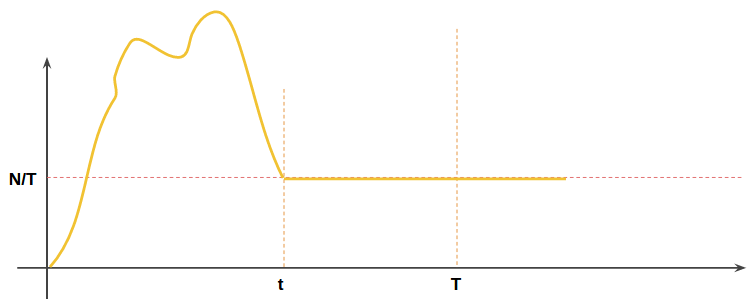
如果桶的容量设为N, 一桶水漏完的时间设为T, 那么这种曲线图也是允许出现的.
其中t时刻桶中水满, 然后以N/T的速度继续加水. 但很遗憾, 这种做法仍然无法控制任意T时间内的访问量恒不大于N.
如何设置桶的容量?
换句话说, 如何能让v ≤N / T ?
假如桶的大小为C, 设△t时间内注水d * C未溢出, (△t ≤T; d ≤ 2).
而后的T - △t时间里再次以速度C / T注水. 则T时间内的平均注水速度v = [(d + 1) * T - △t] * C / T^2.
如果要使v 达到最大, 那么△t最小, d最大. 即d = 2, △t → 0, 这时v → 3C / T.
也就是说要限制桶的容量C = N / 3, 才满足任意T时间访问量恒小于N.
但这种做法仍有一个缺陷, 如下图所示:
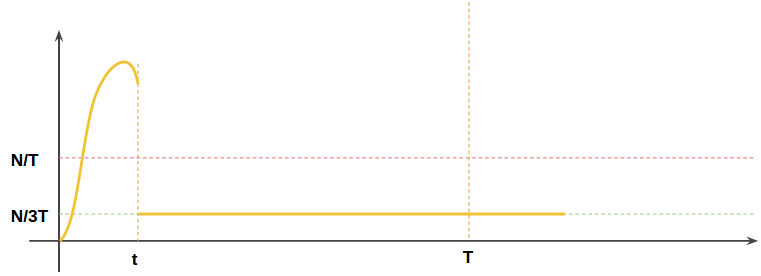
如果桶的容量设为N/3, 一桶水漏完的时间设为T. 这样的设置满足了T时间内不超过N的条件, 但是产生了副作用: 突发流量尚未在允许时间内达到限制条件就被禁止, 即未达到限制条件时请求就可能被拒绝.
重新思考最初的做法 ...
最初的想法是只设定了固定的充值周期, 导致临界点附近的T时间内可能破坏严格的限流规则, 而漏桶虽然没有了counter突变, 但仍未解决问题.
在两次尝试失败后, 我发现是我的分析太偏感性上的认识, 而没抓住关键点. 我们要限制任意T的访问量不超过某个值.
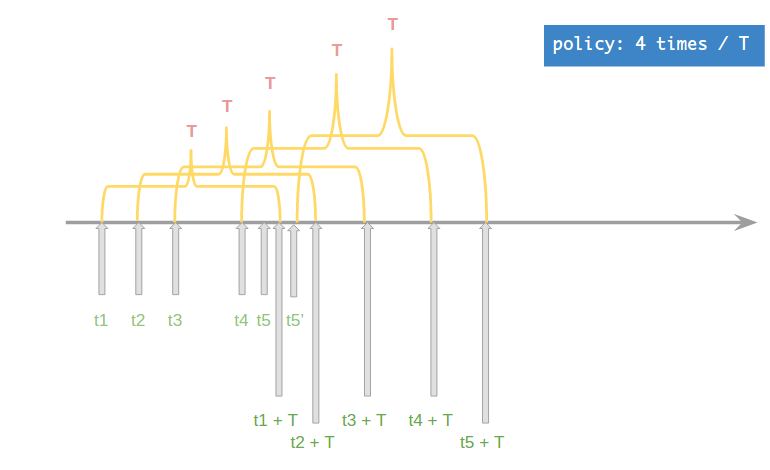
看来固定的T重置点是不可行的, 重置点是动态不可预知的, counter的变化也是. 所以这个新算法的核心是弹性变化counter.
q = []
counter = 0
throttle = () ->
now = Date.now()
head = detectHead q, now
# cut the queue
q = q[head..]
counter -= head
if counter < threshold
q.push now + interval
counter++
# granted access
else
# deny
算法维护一个队列q, 每次成功的访问都会记录从当前开始到T时间间隔后的时间戳, 并依次入队, 同时为计数器增一.
detectHead = (q, ts, i = 0) ->
if q.length > 1
mid = parseInt q.length / 2
if ts > q[mid]
detectHead q[mid + 1..], ts, i + mid + 1
else
detectHead q[...mid], ts, i
else if q[0]? and ts > q[0]
i + 1
else
i
算法在开始时调用detectHead函数, 用二分搜索定位head, 取得合法的头时间戳, 即队列中不小于当前时间戳的最小元素, 目的是更新队列和counter.
当然, detectHead函数定位head的算法有待优化, 当初使用二分搜索的是考虑到一种极端情况:
比如设定的流控策略是10w/1min. 当在1分钟内成功访问了十万次后, 过了很长时间又来一次访问, 如果遍历队列去寻找合法时间戳, 那么将花费O(n)的时间.
但是在没有那么多访问次数的情况下, 或者普通的连续访问情况下, 每次都要二分查找, 原本应该就是常数级O(1)的操作就降级为O(log2N)了. 这显然也是不合理的.
所以什么时候用什么方法就很重要了.
除此之外, 这个算法也要维护一个可能会很长的队列(最大为N, 当然变长后一般会cut掉), 空间复杂度最坏为O(N).
但detectHead只是用于进程内内存维护状态时所用, 如果放到Redis里, 进程吃内存问题应该不大.
在列举了新算法的缺点之后, 我们来看看它实际解决的问题.
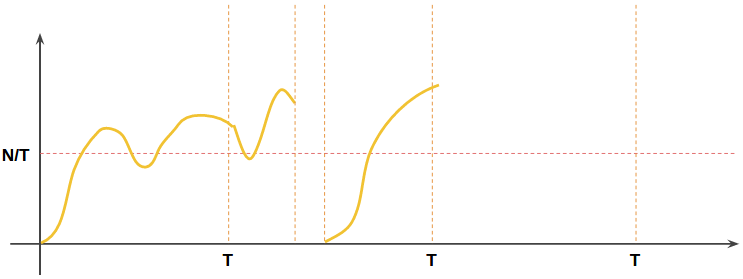
使用新算法后, 保证了任取一个T时间段, 总访问量不高于N, 并且T时间内允许有超过N/T速度的流量出现.
这一次我们讨论的主要是核心的限流算法, 由于篇幅问题, 分布式环境做流控放到一下篇笔记里说.
漏桶算法可以保证T时间内,访问量不超过N呀,bucket+1>N就限制了流量的进入了,本质上说,由于bucket不会手动/定时重置(固定时间窗口算法会定时重置所以有边界问题),而是跟随着流量的进出动态变化