bees
 bees copied to clipboard
bees copied to clipboard
Documentation of hash table stats
An interpretation of what the hash table page occupancy histogram shows may be useful. One filesystem has an occupancy of 42% and a large heap around 40% on the x axis, another filesystem has an occupancy of 98%+, and a smaller heap around 40% and a large heap around 95%.
What does it mean, and what should I do?
The bees hash table consists of Cells, Buckets, and Extents. A Cell is a single {hash, address} entry which points to a location in the filesystem where data with a particular hash is stored. A Bucket is a 4K page containing 256 Cells. An Extent is 4096 contiguous Buckets which are read or written to disk contiguously to take advantage of compression and keep fragmentation of beeshash.dat low.
Each Cell is stored in the Bucket with the index [hash % number_of_buckets]. When a new Cell is inserted, the insertion position in the Bucket is random. If a Cell is used as a dedup src, the Cell is moved to the head (zero index) of the Bucket, pushing all other Cells in the Bucket toward the tail (high index) of the Bucket. If the insertion of a new Cell causes the Bucket to have more than 256 entries, the tail of the Bucket is dropped. This is how bees determines which hash table entries are relevant without using extra bits in memory to store access order or frequency.
Aside: I tried a number of algorithms for selecting where to insert a new Cell in a Bucket (e.g. insert all data short extents before long extents, insert data at a position relative to the block's position within the extent, insert all data at the head) but found that while these targeted insertion locations worked well for specific kinds of data, they were very bad with other kinds of data (e.g. kernel modules and digital camera images work best if their extent blocks are inserted into the Bucket in opposite block order). Random insertion position performs at the average of the best and the worst, neither good nor bad, and provides a nice aging curve that I was looking for.
The histogram shows how many Buckets are filled in the hash table. The X axis is the fullness of the Bucket (100% = all 256 entries occupied). The Y axis is the number of Buckets with that fullness. The Y scale is logarithmic--each row above the zero line doubles the number of Buckets.
At the end of the first pass over the filesystem (i.e. the first time bees reports "out of data, waiting for more", or the first time that all entries in beescrawl.dat have a non-zero transid_min), the peak of the histogram should be between 25% and 75%.
If the peak is below 25% at the end of the first pass, the hash table is unnecessarily large because there was unused space in the hash table after all unique data in the filesystem had been scanned. At 24%, the hash table size should be reduced by half; at 12%, the hash table size should be quartered, etc.
If the peak is above 75% at the end of the first pass, the hash table is too small for the filesystem. Either the hash table size must be increased, or the user must accept a lower dedup hit rate roughly proportional to the percentage of the filesystem that had been scanned when the histogram peak crossed the 76% column.
These numbers are all approximate and are based on typical user data sets. An atypical data set (e.g. one where most of the data falls in a few Buckets, or where extreme filesystem fragmentation has occurred) will affect the shape of the histogram curve and make the effects described in these guidelines larger or smaller than normal.
Cost of implementation must also be considered when changing the hash table size. If the hash table is filled to 80% at the end of pass one it's typically not worthwhile to restart bees with a larger hash table as the space gained will be only a fraction of a percent while the cost is re-reading 100% of the filesystem. Gains and losses of dedup efficiency do not scale linearly with undersizing of the hash table, and a hash table that is less than 10% of its ideal size can still be 90% effective.
After the first pass, the hash table will continue to fill. Bees does delete hash table entries if it discovers that they no longer exist on disk, but it is expensive to determine if a hash table entry is out of date, so bees will only do such erasures during the validation of duplicate block entries. Duplicate data tends to appear again and again, so the duplicate hash table entries will remain at the head of their Buckets as each appearance relocates the duplicate Cell to the head of its Bucket. Old unique data tends to be referenced only once (e.g. log files with timestamps, where old timestamps never reappear in future logs), and old Cells will be pushed out of the hash table by new data which is inserted before the old data with higher and higher probability as the data ages. In practice, unused hash table data is simply pushed out by new data, and the hash table remains close to 100% occupancy.
In some cases bees' heuristics are wrong, e.g. if a user suddenly starts making copies of two-year-old data. If this occurs, delete beescrawl.dat (forcing bees to start over), or defrag the oldest files every year or so (forcing bees to reinsert them into the hash table).
Here's a graph for hash table sizes vs dedupe rates:
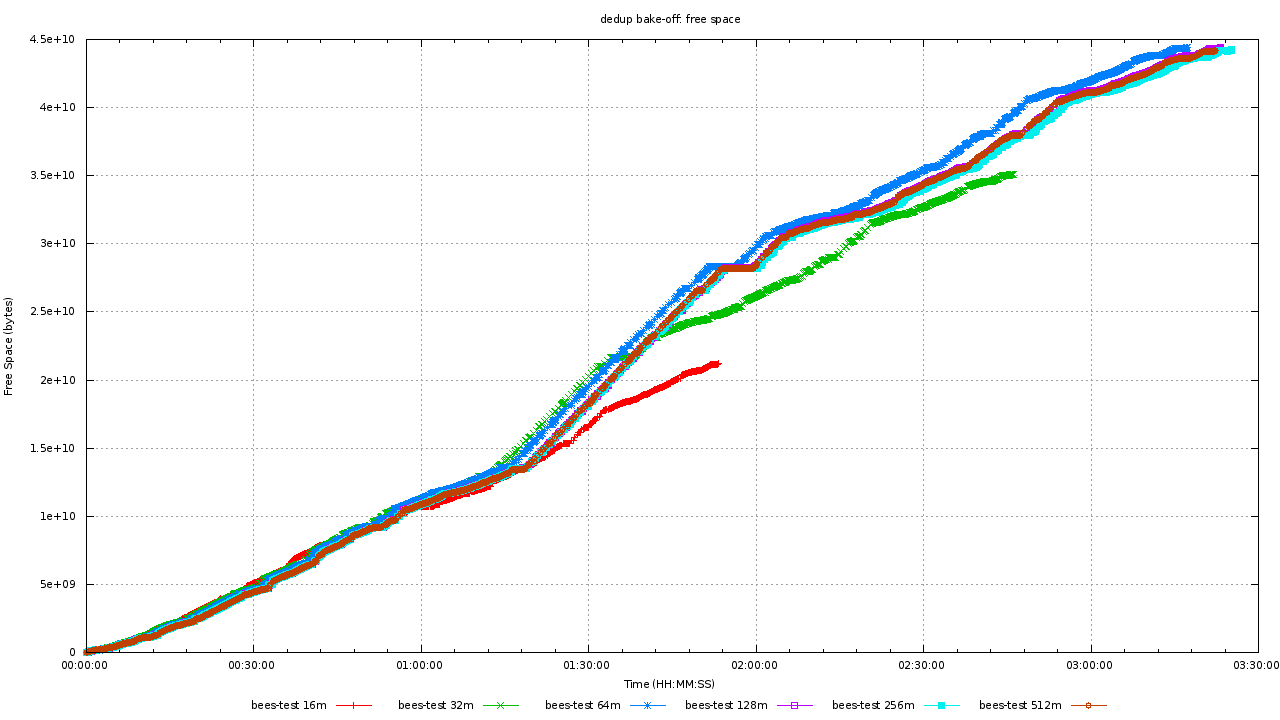
This is a filesystem starting with 104GB of data, 63GB of which is unique. The theoretical maximum hash table size is 63G / 4K * 16 = 252MB. bees dedupes 41GB of data with 4:1 hash table overcommit (64MB) and 50% of the data with 16:1 overcommit (16MB).
That works out to 1GB/TB. Spending any more RAM on hash table often just wastes disk space. The difference in final free space between the 64MB and 512MB hash tables is 448MB--the same as the difference in hash table size.
Notice the 16MB and 32MB hash tables scan the filesystem faster--fewer dedupes to do!
I'm curious to look into the code on this, but I'm wondering if it wouldn't be relatively easy to re-size the hash and re-hash the cells into the new hash size. That would for example allow you to start with using all memory, and then scale down to whatever you can afford without re-scanning whole filesystem. On the other hand, release notes suggest that the hash table structure is going to change anyway...
The individual hash table cells don't change, only their positions in the file (unless at some point in the future there's an option to change the hash length, in which case you could only make the length equal or smaller during a resize). It could be done by an offline tool.
One of the motivations for changing the hash table structure is to support changes in format from within bees (i.e. it could detect a difference between command-line options and the current file format).
I did resize my hash based on the above information and had my filesystem rescan blocks, but around day 5 btrfs had a "hiccup" and the filesystem is now not mountable. Not bees' fault, obviously a kernel problem, but I'm not too confident on the future of btrfs for my applications in the future.