β-VAE [LEARNING BASIC VISUAL CONCEPTS WITH A CONSTRAINED VARIATIONAL FRAMEWORK]
0. 論文情報・リンク
- 論文リンク:https://openreview.net/forum?id=Sy2fzU9gl
- 公開日時:2016/11/05
- 被引用数(記事作成時点):466 件
- 実装コード:
1. どんなもの?
- VAE のアーキテクチャに、disentanglement の程度を制御する単一のハイパーパラメーター β を導入することで、潜在空間をある程度狙い通りに disentanglement して制御することを可能にした VAE。
- 又、潜在空間の disentanglement の程度を定量的に評価するための指標も提案している。
2. 先行研究と比べてどこがすごいの?
- 従来の生成モデル手法では、潜在空間が複雑に絡み合っている(entangles)ために、教師なし学習の枠組みにおいて、生成画像の属性を分離して制御することが困難であった(例えば、MNIST では 0 ~ 9 の数字を狙って生成するなど)。一方 InfoGAN では、このような制御は可能であるが、学習が不安定で多様性も低く、狙い通りに disentanglement して制御することは実際には困難である問題が存在する。 本手法では、VAE のアーキテクチャに、disentanglement の程度を制御する単一のハイパーパラメーター β を導入することで、潜在空間をある程度狙い通りに disentanglement して制御することを可能にしている。
- 又、従来の手法では、潜在空間の disentanglement の程度を定性的にしか評価していなかったが、本手法では、disentanglement の程度を定量的に評価するための指標も提案している。
3. 技術や手法の"キモ"はどこにある?
-
β-VAE のアーキテクチャとハイパパラメーター β の導入

VAE では、上図のようなアーキテクチャの元で、潜在変数 z から画像を生成する確率分布 p_θ (x) の最大化を考える。 但し、確率分布のままでは扱いづらいため、その対数尤度の期待値
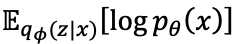 の最大化を考える。
の最大化を考える。β-VAE のアーキテクチャは、VAE をベースとしている。 但し、β-VAE では、観測データ x の集合を、conditionally independent factors(条件付き独立要素)の集合 V と conditionally dependent factors(条件付き非独立要素)の集合 W に分割した集合 D={X,V,W} で考える。 その上で、VAE と同じく以下の式のように、その対数尤度の期待値の最大化を考える。
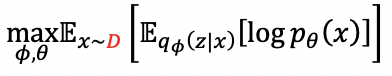
但し、事後分布の近似
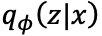 を 事前分布 p(z) に近づけるようにしながら上式の対数尤度を最大化したいので、これらの分布の間の KLダイバージェンスが条件として加わった、以下の最適化問題を解くことになる。
を 事前分布 p(z) に近づけるようにしながら上式の対数尤度を最大化したいので、これらの分布の間の KLダイバージェンスが条件として加わった、以下の最適化問題を解くことになる。

この最適化の式を、ラグランジュの未定乗数法から導かれる KTT 条件を使って変形すると、最終的に、以下の式のような、VAE の KLダイバージェンス項に制約 β をかけた変分下限の式が得られ、これが学習対象の式となる。
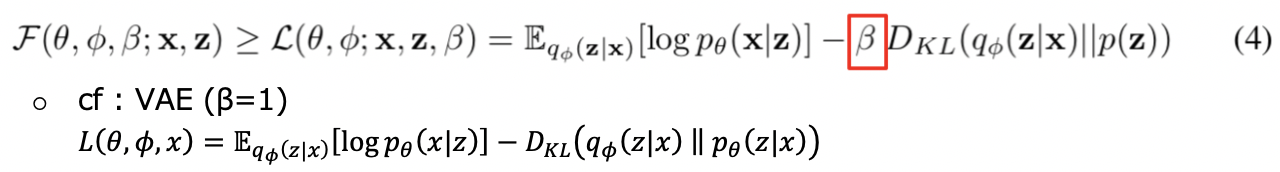
この β 値は、潜在変数 z が事前分布 p(z) に強く制約を受けることを強いるハイパーパラメーターになっており、β の値が大きいほど、conditionally independent factors v の disentanglement された学習が促進されるようになる。 但し、値を大きくしすぎると disentanglement の質と画像の品質のトレードオフのバランスが崩れるので、適切な値に設定することが重要となる。
-
disentanglement の程度を定量的に評価するための指標 disentanglement された潜在空間における生成因子(例えば、MNIST では数字の 0~9、文字の太さ、角度など)に関して、それらを分離する線形境界は、他の生成因子が変化した場合にも、その分離機能は正しく動作すると考えられる。 従って本手法では、生成モデルからの生成画像がどの因子を持っているのかを予め学習しておいた線形分離器で分類し、その正解率を計算することで、disentanglement の程度を定量的に評価することを考える。 ※ 但し、この線形分離器による方法は、事前に disentanglement される生成因子としてどのような因子があるか分かっている必要がある。
具体的には、以下のようなアルゴリズムで計算する。

4. どうやって有効だと検証した?
- 既存の InfoGAN や VAE と、disentanglement の制御可能性を定性的に比較して検証している。

5. 議論はあるか?
- xxx
6. 次に読むべき論文はあるか?
- xxx
7. 参考文献
- xxx