brevitas
 brevitas copied to clipboard
brevitas copied to clipboard
Understanding the `BrevitasONNXManager`
This is the continuation of #351, but since the topic has changed a lot I decided to make this a new issue.
Current state
I am at the state now where I have a model with several layers replaced with their Brevitas equivalent, and training seems to work fine. As I expected, loss increases when quantization is turned on at a certain training step, and the gradually decreases again (fine-tuning). Thanks a lot for getting me this far!
Exporting the model
I am now trying to export the model and later check the weights.
For exporting, I am playing around with the brevitas.export.onnx.generic.manager.BrevitasONNXManager.
The forward call
The first issue I run into is that my network takes two input tensors for its forward method.
For that, it seems that torch.onnx.export uses the input_t parameter (which it calls args) as
"args = (x, y, z)" The inputs to the model, e.g., such that model(*args) is a valid invocation of the model.
However, brevitas call forward as follows:
https://github.com/Xilinx/brevitas/blob/a5bfd6dc5e030f0047ac1ee47932b60e8e873e17/src/brevitas/export/base.py#L256-L258
This causes the forward call to fail
File "/home/speter/dev/parallel-wave-gan/tools/venv/lib/python3.6/site-packages/brevitas/export/base.py", line 258, in _cache_inp_out
_ = module.forward(input_t)
TypeError: forward() missing 1 required positional argument: 'c'
So I changed that line to read _ = module.forward(*input_t) as suggested by torch.onnx.export and that indeed gets me a step further (I think this needs an if-condition to check if the input is actually a tuple, but for my case it now works).
ReLU activation/input quantization
The next issue is that it seems like I need to use activation quantization for the ReLU layers, otherwise I get
File "/home/speter/dev/parallel-wave-gan/tools/venv/lib/python3.6/site-packages/brevitas/proxy/runtime_quant.py", line 164, in forward
AttributeError: 'ReLU' object has no attribute 'activation_impl
I was using input quantization, but I guess activation quantization ends up doing the same thing since its ReLU, so I'll just switch (or use both, but I guess this will add to training time and not provide any benefit).
ONNX opset_version
Now finally I am getting the following error from ONNX
RuntimeError: Unsupported: ONNX export of Slice with dynamic inputs. DynamicSlice is a deprecated experimental op. Please use statically allocated variables or export to a higher opset version.
A quick google search led me to people saying to pass opset_version=10 to the export call, so I did that.
Indeed the call now finishes without error - It does however produce warnings such as
UserWarning: You are trying to export the model with onnx:Resize for ONNX opset version 10. This operator might cause results to not match the expected results by PyTorch. ONNX's Upsample/Resize operator did not match Pytorch's Interpolation until opset 11. Attributes to determine how to transform the input were added in onnx:Resize in opset 11 to support Pytorch's behavior (like coordinate_transformation_mode and nearest_mode).
and
UserWarning: This model contains a squeeze operation on dimension 1 on an input with unknown shape. Note that if the size of dimension 1 of the input is not 1, the ONNX model will return an error. Opset version 11 supports squeezing on non-singleton dimensions, it is recommended to export this model using opset version 11 or higher. "version 11 or higher.")
as well as quite a few of the following:
Warning: Unsupported operator Quant. No schema registered for this operator.
Exported weights
This may be my inexperience with QAT, but it seems like the weights stored in the resulting .onnx file are not quantized.
They also do not align well with the scale (zero-point is 0 as expected).
Granted I only did QAT for a couple of batches to have a look at the output, but what should I expect from the weight values in the .onnx file?
Is the fact that scales and zero-points are also saved the only benefit of ONNX (aside from its compatibility with other software - that aspect is not relevant for me).
Concluding
This became quite the long text, sorry about that. Nevertheless it would be awesome if you could find the time to help me out!
Hopefully there is also some info in here that will help development of the library, and possibly users in the meantime.
Hello,
Thanks for the extensive feedback. Let me answer point by point.
- Yes the current export implementation is kind of naive and assumes a single input. Your approach to generalize it is correct. In general Brevitas is designed to be hackable, if you feel like the current implementation of something doesn't really work for your case, the best way is to just inherit from it and tweak it, like you did here.
- I think the issue with ReLU is fixed in the dev branch, do you mind checking?
- Anything related to how standard torch ops and the ONNX opset interact is beyond the scope of Brevitas. The warning related to the custom Quant op is something that showed up in more recent PyTorch versions, there's probably a way to suppress them/make them happy but in general they are totally harmless.
- Yes currently the weights are store in an unquantized fashion. The goal BrevitasONNX is to capture the connectivity of the network and the quantization operators acting on floating-point weights, biases and activations, together with their parametrization (scale and zero-point and bit width like you mentioned). It assumes that the backend reading it knows how to implement the Quant operator. The quantized weights can be computed as the output of the Quant operator applied to the floating point weights. I could implement it as a post processing step in the export to pre-compute them, but it would be a requirement really only to interpreted backends rather than compiled ones, which honestly I have yet to see, so it's not high priority.
Thank you for your quick reply.
- As to the first point: Like they always say in Python, "we are all consenting adults here".
- l tried the dev branch and it gives the same error. As far as I can tell, the latest changes to the file where the error appears are already in master. Let me know if I'm looking in the wrong place, or if you need more info (like the full stack trace).
- I see, so this is an upstream issue. And as you say, it indeed seems to export the model correctly.
Now about the final point, the weights. I am new to quantization so I probably don't have a good understanding yet. What I thought happens during QAT is that the weights are (fake-)quantized after the optimizer step, and that this leads to the weights aligning with the actual quantization that later happens on the specialized hardware.
In my case, I am doing the calculations using ap_fixed (and not int to later apply the scale) so I wanted to make sure that the weights align this fixed-point representation. Brevitas' PowerOfTwo constraint seems great for this.
However, after training the network for another ~300 epochs, the following is an example of weights before and after quantization.
I flattened and sorted the weights array (and took a subset), so the x-axis is just the weights in order. The y-axis is the actual weight value.
Quantization is performed with np.round(weights / scale) * scale (zero zero-point).
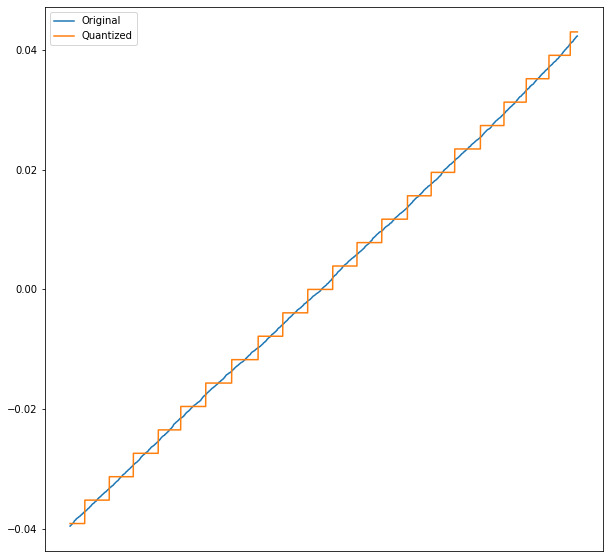 So here are my questions:
So here are my questions:
- Is this a normal result, or should the weights (before quantization) actually somewhat align with the quantized values?
- Clearly quantizing these weights significantly changes their value - does QAT train the network so that this later change is considered? (I'm having trouble phrasing this well).
- As this is a generative network, it's difficult to give an objective measurement. Loss is decreasing though, and while the resulting data has suffered a hit to its subjective quality, it's by no means horrible. I can't tell if its better than just using post-training quantization. From the data I have posted here, can you tell if there is something going wrong? I'm happy to give you more info, but I wanted to keep this to a reasonable length.
- Finally, changing over to using the scale+int (possibly also with non-zero zero-point) way of quantization directly in my hardware should not be that much work. Would this possibly lead to better quantization?
Thank you again for being so responsive - I hope the feedback I can give is worth your effort! Let me know if there is anything I could do to help out.
Hello,
Say that in your neural network you have some function f(W) that is doing some computation, a conv or whatever, that depends on floating points weights W. What QAT does is to replace W with Q(W) - where Q is your (fake)-quantization function - anywhere W is used in the forward pass, so you end up computing f(Q(W)).
Normally Q would have 0 gradients almost everywhere, so in QAT you use a gradient estimator (typically a straight through estimator) to be able to pass useful gradients back to W.
Once training is done Q(W) is a constant and is your set of quantized weights. BrevitasONNX exports Q and W separately, but you can easily compute it as you did here.
Given that:
- I think the misunderstanding is that W is not in-place updated by Q, which is why you see that W and Q(W) can be quite different. That is a different class of problem, so called quantized training, which is typically much harder to converge (especially as precision goes down), and it's useful if you are interested in providing savings at training time in terms of weight storage. QAT is focused only on providing savings at inference time.
- QAT accounts for that in the sense that never directly use W in your forward pass, you always use Q(W).
- Quantized GANs can be tricky to converge in my experience. I worked on an 8b MelGAN in the past and what ended up working the best is a learned parameter scale for weights and a const for activations, all trained from scratch and not from a pretrained model. It still took days to converge and a lot of tuning.
- At high precision (say 6 or more bits) it shouldn't really make much of a difference, but with a GAN I wouldn't take the risk and I'd try to train with a scaled int first, get to results I'm happy with, and the move to the more constrained scenario and see how it affects things using the same training regimen.