difference in evaluation during inference and training
I have trained a model using my custom dataset and had precision value of about 0.72 but when I used the saved weights for test script the value jumped to 0.95 I am not sure why this is happening. this also occurs when I try to train the model further from last saved weights. I am not sure what is causing this. Any help would be appreciated.
for training: python train.py --data drone.data --cfg drone.cfg --weights 'weights/best.pt' --name yolov4-pacsp --img 1024 1024 1024
for testing: python test.py --img 1024 --conf 0.001 --batch 8 --data drone.data --weights weights/best_yolov4-pacsp.pt --cfg drone.cfg
If I run train again with final best saved weights the values change alot.


So this is the difference its really weird. This is using last weights.
classes=1 train=drone/train.txt valid=drone/test.txt
names=data/drone.names
Also I see that you have changed the repo that is more like yolov5 and I only see weights and cfg files with mish activation. Are the previous ones available? I wanted to train with the normal ones. The weights file would be same I guess but what about yaml file? do I change something?
Have you solved this problem? I have encountered the same problem, but I am sure that the parameters of test.py and train.py are the same
Hi, I have a similar problem. My own has 4 classes. In my training process, the mAP in tensorboard is 0.66. But the test result shows mAP is 0.003. I don't know why. Can you help me?
The training code: python train.py --batch-size 8 --cfg yolov4.cfg --data data/urpc2020.yaml
The testing code: python test.py --weights runs/exp0/weights/last.pt --cfg yolov4.cfg --data data/urpc2020.yaml --save-json --verbose --save-txt
For img-size , I set both codes to 640.
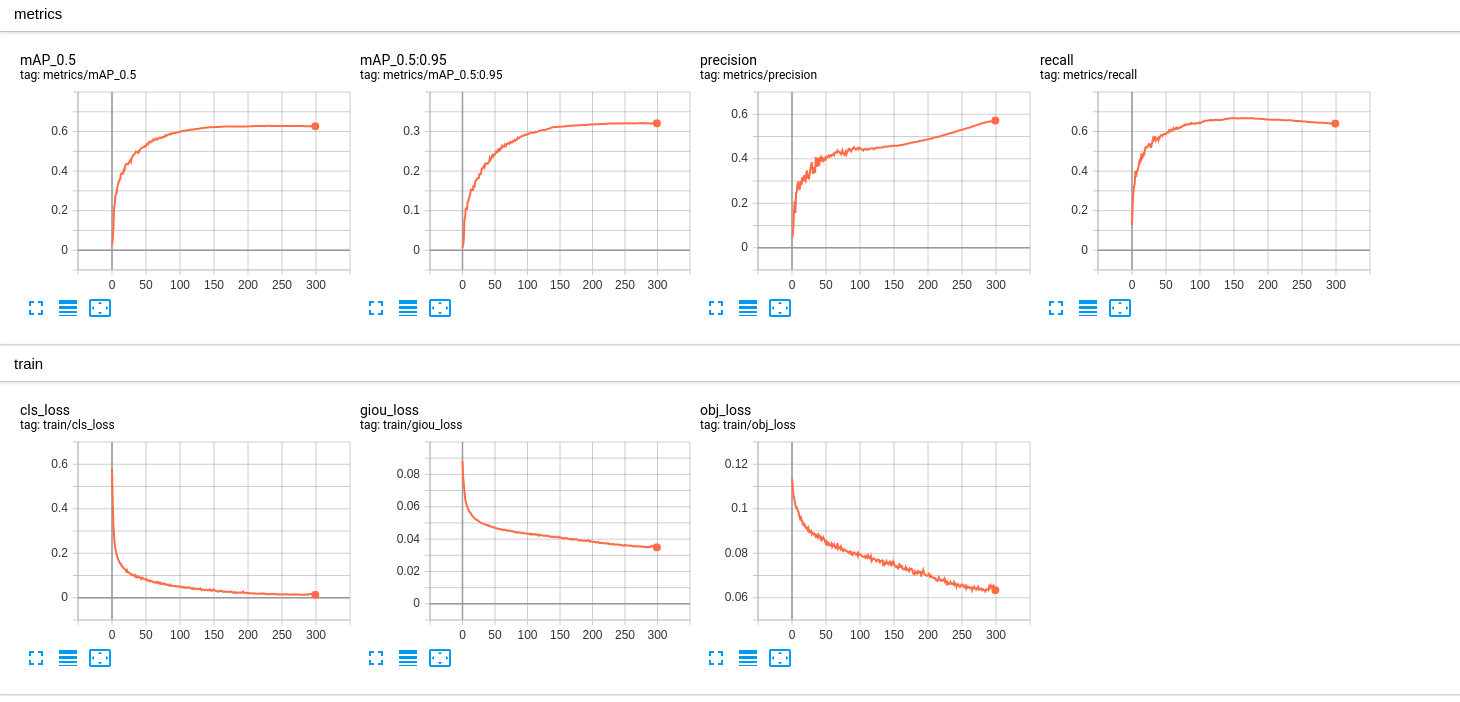
This is the training plot in tensorboard:
This is the testing results in terminal:
Model Summary: 327 layers, 6.39538e+07 parameters, 6.39538e+07 gradients
Scanning labels data/labels.cache (1180 found, 0 missing, 20 empty, 0 duplicate, for 1200 images): 100%|████████████████████████████████████████████| 1200/1200 [00:00<00:00, 7212.83it/s]
Class Images Targets P R [email protected] [email protected]:.95: 100%|███████████████████████████████████████████████████████| 75/75 [01:15<00:00, 1.01s/it]
all 1.2e+03 9.94e+03 0.0128 0.0159 0.00338 0.001
holothurian 1.2e+03 654 0.0303 0.0413 0.00297 0.000672
echinus 1.2e+03 3.3e+03 0.0127 0.0149 0.00534 0.00175
scallop 1.2e+03 4.06e+03 0.0049 0.00369 0.005 0.0015
starfish 1.2e+03 1.93e+03 0.00339 0.00363 0.000238 7.42e-05
Speed: 9.9/1.7/11.6 ms inference/NMS/total per 640x640 image at batch-size 16
COCO mAP with pycocotools... saving detections_val2017_last_results.json...
loading annotations into memory...
Done (t=0.05s)
creating index...
index created!
Loading and preparing results...
DONE (t=1.03s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=27.28s).
Accumulating evaluation results...
DONE (t=1.60s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.003
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.008
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.005
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.005
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.002
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.008
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.013
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.008
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.045
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.007