KNN-based Trajectory Similarity Join(Standalone Mode)
It is very nice of your team to offer this project to do the distributed trajectory similarity search effectively.
However,when I run the KNN-based Trajectory Similarity Join. I don't get the result as I excepted.
I use 100 trajectories and I want to know the distance between them. So there will be 10000 records in the result. To achieve this, I try to use KNN-based Join to solve it. So I write the code below
val knnJoin = TrajectorySimilarityWithKNNAlgorithms.DistributedJoin
val knnJoinAnswer = knnJoin.join(spark.sparkContext, rdd1, rdd2, TrajectorySimilarity.DTWDistance,10000)
println(s"KNN join answer count: ${knnJoinAnswer.count()}")
rdd1 and rdd2 are from the same input file with 100 trajecotries. In my opinion,the 10000 means the count,so it should return 10000 records in the knnJoinAnswer. However, the result is 1228. And I groupby the knnJoinAnswer to find the reason.
val intres = knnJoinAnswer.groupBy(_._1.id)
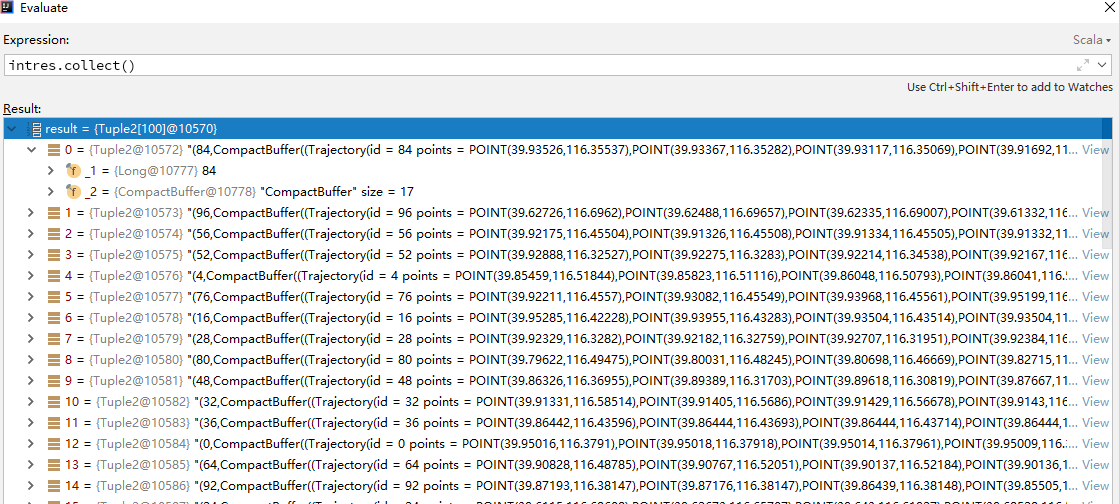
There are 100 trajs, while the corresponding value is less than 100. What's wrong? Thanks in advance.
It is very weird. Could you please provide the trajectories you are using for us to debug? @wxigsnrr
In fact,this file is randomly sampled from the file you given (trajectory.txt) Thanks a lot