Meta-Reinforcement-Learning
 Meta-Reinforcement-Learning copied to clipboard
Meta-Reinforcement-Learning copied to clipboard
Code snippets of Meta Reinforcement Learning algorithms
Meta Reinforcement Learning Notebooks
This Repository contains codes related to FL-RL Project. The complete codes and notebooks will be published soon.
The purpose of this project is to implement and test the PyTorch codes of Meta reinforcement Learning approaches from scratch.
Requirements
- Python 3.8
- PyTorch
- Gym v0.21.0
- Learn2Learn v0.2.0
- Cherry-RL v0.2.0
- Mojuco-Py
Content
- [x] Trust Region Policy Optimization
- [x] MAML A2C
- [x] MAML TRPO
- [x] MAML PPO
- [x] ANIL
- [ ] SNAIL
- [ ] Reptile
Experiments
Half Cheetah Environment
Training for 300 iterations.
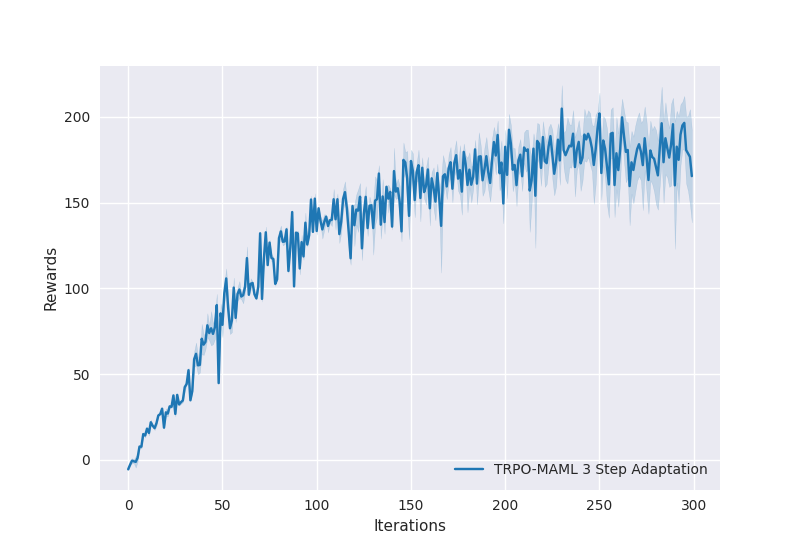
-
TRPO-MAML trained model output

-
After 3 TRPO Update steps on forward task

-
After 3 TRPO Update steps on backward task

Ant Environment
Training for 900 iterations.
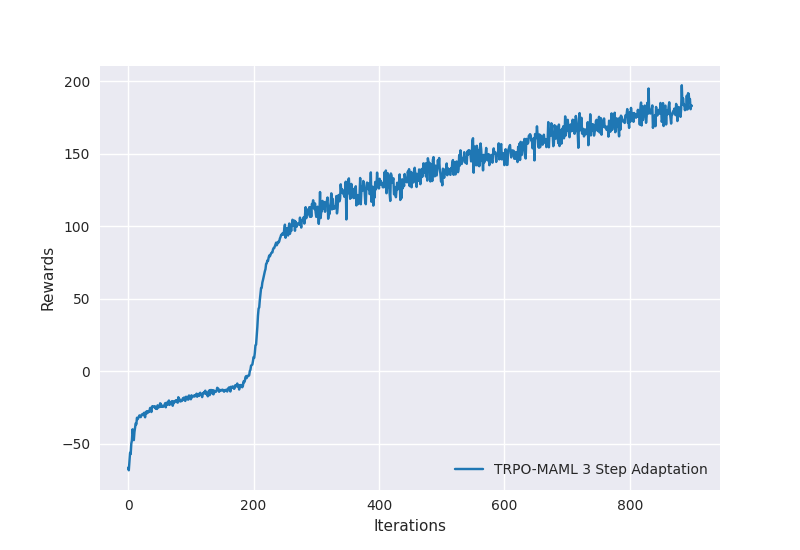
-
TRPO-MAML trained model output

-
After 5 TRPO Update steps on forward task

-
After 5 TRPO Update steps on backward task

References
- Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. 34th Int. Conf. Mach. Learn. ICML 2017 3, 1856–1868 (2017).
- Raghu, A., Raghu, M., Bengio, S. & Vinyals, O. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML. 1–21 (2019).
- Mishra, N., Rohaninejad, M., Chen, X. & Abbeel, P. A Simple Neural Attentive Meta-Learner. 6th Int. Conf. Learn. Represent. ICLR 2018 - Conf. Track Proc. 1–17 (2017).
- Schulman, J., Levine, S., Moritz, P., Jordan, M. I. & Abbeel, P. Trust Region Policy Optimization. 32nd Int. Conf. Mach. Learn. ICML 2015 3, 1889–1897 (2015).
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal Policy Optimization Algorithms. 1–12 (2017).
Metadata
31
Stars
1
Forks
Watchers
Owner
Metadata
Code snippets of Meta Reinforcement Learning algorithms