fast-stable-diffusion
 fast-stable-diffusion copied to clipboard
fast-stable-diffusion copied to clipboard
Missing key(s) in state_dict
Hello, When trying to use controlnet with clip_vision as preprocessor and t2i_adapter_style-fp16 as model, i get the following error. Any idea? Thanks!
Loaded state_dict from [/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/models/t2iadapter_style-fp16.safetensors]
Error running process: /content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/controlnet.py
Traceback (most recent call last):
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/scripts.py", line 386, in process
script.process(p, *script_args)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/controlnet.py", line 742, in process
model_net = self.load_control_model(p, unet, model, lowvram)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/controlnet.py", line 541, in load_control_model
model_net = self.build_control_model(p, unet, model, lowvram)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/controlnet.py", line 579, in build_control_model
network = network_module(
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/adapter.py", line 81, in __init__
self.control_model.load_state_dict(state_dict)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1671, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for Adapter:
Missing key(s) in state_dict: "body.0.block1.weight", "body.0.block1.bias", "body.0.block2.weight", "body.0.block2.bias", "body.1.block1.weight", "body.1.block1.bias", "body.1.block2.weight", "body.1.block2.bias", "body.2.in_conv.weight", "body.2.in_conv.bias", "body.2.block1.weight", "body.2.block1.bias", "body.2.block2.weight", "body.2.block2.bias", "body.3.block1.weight", "body.3.block1.bias", "body.3.block2.weight", "body.3.block2.bias", "body.4.in_conv.weight", "body.4.in_conv.bias", "body.4.block1.weight", "body.4.block1.bias", "body.4.block2.weight", "body.4.block2.bias", "body.5.block1.weight", "body.5.block1.bias", "body.5.block2.weight", "body.5.block2.bias", "body.6.block1.weight", "body.6.block1.bias", "body.6.block2.weight", "body.6.block2.bias", "body.7.block1.weight", "body.7.block1.bias", "body.7.block2.weight", "body.7.block2.bias", "conv_in.weight", "conv_in.bias".
Unexpected key(s) in state_dict: "ln_post.bias", "ln_post.weight", "ln_pre.bias", "ln_pre.weight", "proj", "style_embedding", "transformer_layes.0.attn.in_proj_bias", "transformer_layes.0.attn.in_proj_weight", "transformer_layes.0.attn.out_proj.bias", "transformer_layes.0.attn.out_proj.weight", "transformer_layes.0.ln_1.bias", "transformer_layes.0.ln_1.weight", "transformer_layes.0.ln_2.bias", "transformer_layes.0.ln_2.weight", "transformer_layes.0.mlp.c_fc.bias", "transformer_layes.0.mlp.c_fc.weight", "transformer_layes.0.mlp.c_proj.bias", "transformer_layes.0.mlp.c_proj.weight", "transformer_layes.1.attn.in_proj_bias", "transformer_layes.1.attn.in_proj_weight", "transformer_layes.1.attn.out_proj.bias", "transformer_layes.1.attn.out_proj.weight", "transformer_layes.1.ln_1.bias", "transformer_layes.1.ln_1.weight", "transformer_layes.1.ln_2.bias", "transformer_layes.1.ln_2.weight", "transformer_layes.1.mlp.c_fc.bias", "transformer_layes.1.mlp.c_fc.weight", "transformer_layes.1.mlp.c_proj.bias", "transformer_layes.1.mlp.c_proj.weight", "transformer_layes.2.attn.in_proj_bias", "transformer_layes.2.attn.in_proj_weight", "transformer_layes.2.attn.out_proj.bias", "transformer_layes.2.attn.out_proj.weight", "transformer_layes.2.ln_1.bias", "transformer_layes.2.ln_1.weight", "transformer_layes.2.ln_2.bias", "transformer_layes.2.ln_2.weight", "transformer_layes.2.mlp.c_fc.bias", "transformer_layes.2.mlp.c_fc.weight", "transformer_layes.2.mlp.c_proj.bias", "transformer_layes.2.mlp.c_proj.weight".
I don't think the issue is caused by the notebook, check with the extension's repo
i made a copy of t2iadapter_style_sd14v1.yaml and renamed it to match the model like so > t2iadapter_style-fp16.yaml . There is two other .yaml's that should be copied and renamed or probably just renamed from ending in _sd14v1 > -fp16
i did it at both instances i found the yaml file and now its working for me G:\My Drive\sd\stable-diffusion-webui\extensions\sd-webui-controlnet\models G:\My Drive\sd\stable-diffusion-webui\models
i made a copy of t2iadapter_style_sd14v1.yaml and renamed it to match the model like so > t2iadapter_style-fp16.yaml . There is two other .yaml's that should be copied and renamed or probably just renamed from ending in _sd14v1 > -fp16
i did it at both instances i found the yaml file and now its working for me G:\My Drive\sd\stable-diffusion-webui\extensions\sd-webui-controlnet\models G:\My Drive\sd\stable-diffusion-webui\models
Thanks a lot. This helped.
Devs, please fix this :(
its not though... i just double checked. please try running a controlnet with color preprocessor and t2i color adapter model
 if it was working you would have one of these files for guidance
if it was working you would have one of these files for guidance
this fix works. after you copy them to a different folder i just copy them back with the new name. so i have 3 extra yaml's kept sd14v1 and added fb16
try the controlnet then rename the 3 files in terminal and try again https://github.com/pcrii/fast-philo-diffusion/commit/1b0e5656d16f664bc424cca98d503385354ea471
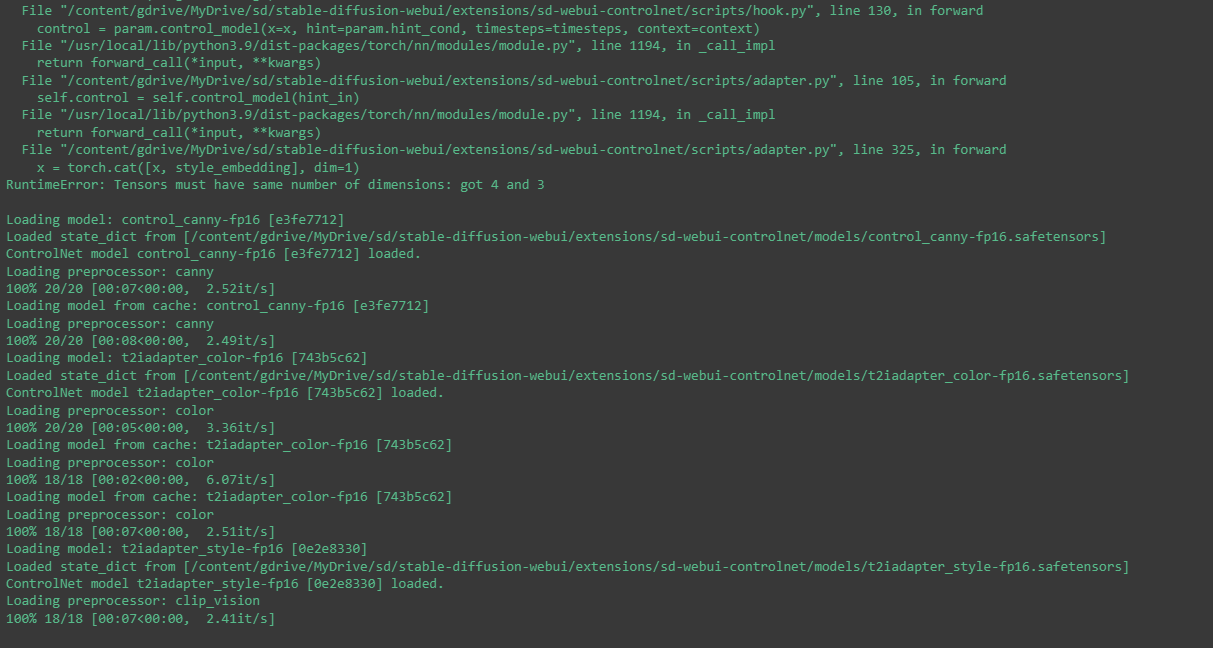
Hi! the changelog says that the t2i models are fixed. Still, starting from a fresh install, running the t2i style model, I got this error now: "RuntimeError: Tensors must have same number of dimensions: got 4 and 3". Anyone else having an issue? (note: i'm running that on colab)
Traceback (most recent call last):
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/txt2img.py", line 56, in txt2img
processed = process_images(p)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/processing.py", line 486, in process_images
res = process_images_inner(p)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/processing.py", line 636, in process_images_inner
samples_ddim = p.sample(conditioning=c, unconditional_conditioning=uc, seeds=seeds, subseeds=subseeds, subseed_strength=p.subseed_strength, prompts=prompts)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/processing.py", line 836, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 351, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 227, in launch_sampling
return func()
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 351, in <lambda>
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args={
File "/usr/local/lib/python3.9/dist-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion/sampling.py", line 145, in sample_euler_ancestral
denoised = model(x, sigmas[i] * s_in, **extra_args)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py", line 138, in forward
x_out[a:b] = self.inner_model(x_in[a:b], sigma_in[a:b], cond={"c_crossattn": c_crossattn, "c_concat": [image_cond_in[a:b]]})
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion/external.py", line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "/content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion/external.py", line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/sd_hijack_utils.py", line 17, in <lambda>
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/sd_hijack_utils.py", line 28, in __call__
return self.__orig_func(*args, **kwargs)
File "/content/gdrive/MyDrive/sd/stablediffusion/ldm/models/diffusion/ddpm.py", line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/sd/stablediffusion/ldm/models/diffusion/ddpm.py", line 1329, in forward
out = self.diffusion_model(x, t, context=cc)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py", line 233, in forward2
return forward(*args, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py", line 130, in forward
control = param.control_model(x=x, hint=param.hint_cond, timesteps=timesteps, context=context)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/adapter.py", line 105, in forward
self.control = self.control_model(hint_in)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/adapter.py", line 325, in forward
x = torch.cat([x, style_embedding], dim=1)
RuntimeError: Tensors must have same number of dimensions: got 4 and 3
i did get that error but i just hit generate again and it worked right the next time. in this screenshot you can see i successfully used clip vision and the t2i adapter
i errored changed nothing just pressed generate again it worked. i think controlnet is lagging. example. here it claims no input image is given. i was to fast for it i guess
Error running process: /content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/controlnet.py
Traceback (most recent call last):
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/scripts.py", line 409, in process
script.process(p, *script_args)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/controlnet.py", line 705, in process
raise ValueError('controlnet is enabled but no input image is given')
ValueError: controlnet is enabled but no input image is given
100% 18/18 [00:07<00:00, 2.48it/s]
Loading model from cache: control_canny-fp16 [e3fe7712]
Loading preprocessor: canny
100% 18/18 [00:10<00:00, 1.76it/s]
Yes it's super weird. Now I don't get errors, but I have the same output regardless of the weight (from 0 to 2) of the clip_vision + t2iadapter style controlnet brick (enabled is clicked, of course).
EDIT: it seems that on a clean launch of the UI, the clip_vision+t2i style are taken into account for one image generation. Then, for the next image generations, it's no longer the case, the other controlnets are taken into account, but the clip_vision + t2i are ignored. There's no warning or error message in the colab console. Sometimes, when using these things, the UI just crashes (there's an error message, which means need to go on colab, stop and rerun the last cell to reboot the UI)
I'm trying to use controlnet with the clip_vision preprocessor + t2i style adapter model. I noticed that the clip_vision annotator result is always empty, contrary to other preprocessors, I cannot see the result. Is this normal?
i made a copy of t2iadapter_style_sd14v1.yaml and renamed it to match the model like so > t2iadapter_style-fp16.yaml . There is two other .yaml's that should be copied and renamed or probably just renamed from ending in _sd14v1 > -fp16
i did it at both instances i found the yaml file and now its working for me G:\My Drive\sd\stable-diffusion-webui\extensions\sd-webui-controlnet\models G:\My Drive\sd\stable-diffusion-webui\models
For some reason this didn't work for me, also didn't have anything in my Stable-diffusion-webui-models folder regarding the yaml files