Add more information to crash reports
- [x] I carefully read the contribution guidelines and agree to them.
- [x] I checked if the issue/feature exists in the latest version.
Sometimes we get error reports, but cannot reproduce crashes due to different versions of the parsed website. To get rid of this difficulty, we should make it possible to add the fetched HTML page to the JSON report. I'd suggest to place an additional checkbox at the top/bottom of the report dialog which is not checked by default. If checked, a new element needs to be added at the end of the JSON. @theScrabi @mauriciocolli @karyogamy @TheAssassin I hope my idea is clear. Is there anything I did not take into account which makes this difficult or not recommendable?
I did not look into this yet, but I guess we need to make some changes in the extractor before we can access the fetched document in the frontend. The changes in the crash report converter are quite simple. However, we might want to add this additional information to Sentry, too.
That'll be a lot more data than we get now... I'm a bit concerned.
Are you speaking of A/B testing etc.?
This is hard to implement, since it is not always just html which is part of the extraction process. Also it would require massive changes in the backend. ... Im not sure if the outcome would justify the effort.
I think this would be very useful to be able to fix little nasty bugs that only happen sometimes to some person in some country. One of the extractor bugs I fixed lately only happened once every ~30 tries, so I had to tell Android Studio to run the same test indefinitely and put a breakpoint in the place the exception was thrown. Only then I was able to catch the page content. Instead if I could access this directly on my phone it would be far simpler, because I would be able to catch random error while using the app normally.
We needed some more info by some users recently, so I worked on this again. Open a channel page to throw an exception and test the changes: app-debug.apk.zip.
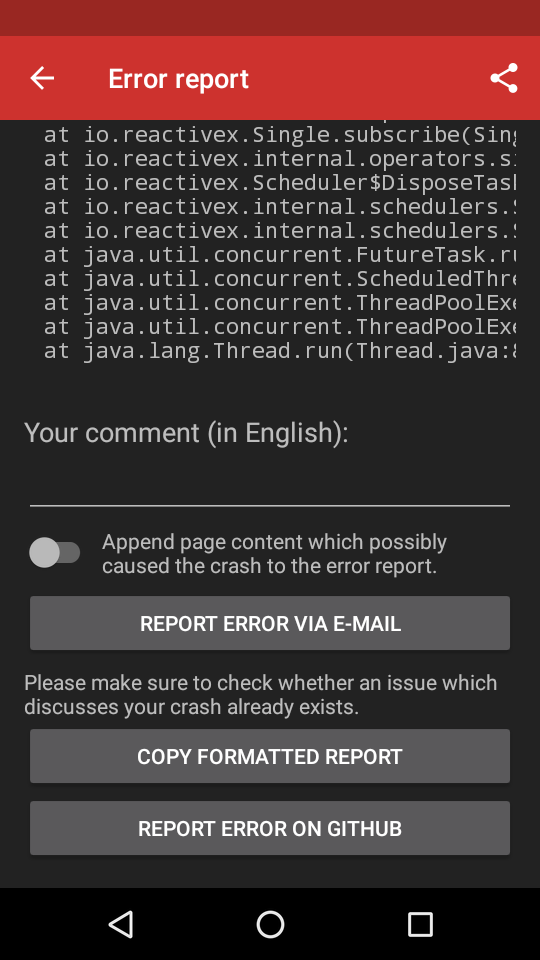
As you can see, I added some more functionality. It is mow possible to convert the error reoprt directly to Markdown / HTML which is more user friendly and does not require one to open the incredible bugreport to markdown converter. This should reduce the number of JSON pastes jere on GitHub significantly. I also modified the extractor exceptions to show us the documents or elements which caused problems.
Regarding the size problematic: I only include document parts or the whole document, when ExtractionException or ParsingException occur. In addition i added a switch to the ErrorActivity which is disabled by default, meaning no html documents are included at all. @TheAssassin I do not include the documents when reporting via email, but only when copying the report for GitHub.
This is hard to implement, since it is not always just html which is part of the extraction process. Also it would require massive changes in the backend
@theScrabi In the end, this was quite easy and uncomplicated. I just added aString document attribute to both Exception classes, getters and some more constructors.
Nice :D. I like all of this :)
Here are some thoughts though:
With the ability to open issues directly from NewPipe there might be a chance of user bloating the issues as they might paste without checking. What do you think?
Maybe there could be a "share" option to open issues with FastHub, with the issue and error report prerendered
With the ability to open issues directly from NewPipe there might be a chance of user bloating the issues as they might paste without checking. What do you think?
@theScrabi I can add an AlertDialog to make user promise to first search and then create an issue. Something like
Please make sure to first search the existing issues and to not just open a new issue. Every new issue requires us to check whether a similar ticket exists to keep the discussion on it bundled in one place. This is time we can spend fixing bugs. So please help us with this.
Maybe there could be a "share" option to open issues with FastHub, with the issue and error report prerendered
@Serkan-devel I added the Report error on GitHub button, which opens the share menu when FastHub or any other GitHub clients are installed. But as @theScrabi said, when directing people to create a new issue, they won't check whether one dealing with the problem already exists. As a result there would be tons of new issues which we need to close, but we'd like to spend our time with solving the bugs, not maintaining bug trackers :)
Regarding the size problematic: I only include document parts or the whole document, when ExtractionException or ParsingException occur. In addition i added a switch to the ErrorActivity which is disabled by default, meaning no html documents are included at all. @TheAssassin I do not include the documents when reporting via email, but only when copying the report for GitHub.
We could also use this with Sentry, implementing a proper retention policy is long overdue. Right now we're storing years old issues nobody will ever look into any more.
I'm not sure how well Sentry is still in use. @all can you perhaps tell how you use Sentry and whether you have suggestions in order to allow for using it more efficiently. We collect a lot of data, and my concern is it's too much to overlook, despite having Sentry combine similar reports.
Exception
- User Action: requested stream
- Request: https://www.youtube.com/watch?v=kxNkKBBM6ik
- Content Country: GB
- Content Language: en
- Service: YouTube
- Version: 0.17.3
- OS: Linux Android 6.0 - 23
Crash log 1
java.lang.NullPointerException: Attempt to invoke virtual method 'int java.lang.String.hashCode()' on a null object reference
at org.schabi.newpipe.extractor.services.youtube.extractors.YoutubeStreamExtractor.getPlayerConfig(YoutubeStreamExtractor.java:674)
at org.schabi.newpipe.extractor.services.youtube.extractors.YoutubeStreamExtractor.onFetchPage(YoutubeStreamExtractor.java:652)
at org.schabi.newpipe.extractor.Extractor.fetchPage(Extractor.java:52)
at org.schabi.newpipe.extractor.stream.StreamInfo.getInfo(StreamInfo.java:63)
at org.schabi.newpipe.extractor.stream.StreamInfo.getInfo(StreamInfo.java:59)
at org.schabi.newpipe.util.ExtractorHelper.lambda$getStreamInfo$3(ExtractorHelper.java:115)
at org.schabi.newpipe.util.-$$Lambda$ExtractorHelper$5fJcha6Sq5APJBLdG6osaJby-mc.call(lambda)
at io.reactivex.internal.operators.single.SingleFromCallable.subscribeActual(SingleFromCallable.java:44)
at io.reactivex.Single.subscribe(Single.java:3438)
at io.reactivex.internal.operators.single.SingleDoOnSuccess.subscribeActual(SingleDoOnSuccess.java:35)
at io.reactivex.Single.subscribe(Single.java:3438)
at io.reactivex.internal.operators.maybe.MaybeFromSingle.subscribeActual(MaybeFromSingle.java:41)
at io.reactivex.Maybe.subscribe(Maybe.java:4154)
at io.reactivex.internal.operators.maybe.MaybeConcatArray$ConcatMaybeObserver.drain(MaybeConcatArray.java:153)
at io.reactivex.internal.operators.maybe.MaybeConcatArray$ConcatMaybeObserver.request(MaybeConcatArray.java:78)
at io.reactivex.internal.operators.flowable.FlowableElementAtMaybe$ElementAtSubscriber.onSubscribe(FlowableElementAtMaybe.java:66)
at io.reactivex.internal.operators.maybe.MaybeConcatArray.subscribeActual(MaybeConcatArray.java:42)
at io.reactivex.Flowable.subscribe(Flowable.java:14479)
at io.reactivex.internal.operators.flowable.FlowableElementAtMaybe.subscribeActual(FlowableElementAtMaybe.java:36)
at io.reactivex.Maybe.subscribe(Maybe.java:4154)
at io.reactivex.internal.operators.maybe.MaybeToSingle.subscribeActual(MaybeToSingle.java:46)
at io.reactivex.Single.subscribe(Single.java:3438)
at io.reactivex.internal.operators.single.SingleSubscribeOn$SubscribeOnObserver.run(SingleSubscribeOn.java:89)
at io.reactivex.Scheduler$DisposeTask.run(Scheduler.java:578)
at io.reactivex.internal.schedulers.ScheduledRunnable.run(ScheduledRunnable.java:66)
at io.reactivex.internal.schedulers.ScheduledRunnable.call(ScheduledRunnable.java:57)
at java.util.concurrent.FutureTask.run(FutureTask.java:237)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:269)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1113)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:588)
at java.lang.Thread.run(Thread.java:818)
Just took crash report via debug apk, After Installing this apk showing "Leak detected need storage permission,I didn't enable this option.
@mehedihasanziku Sorry to bother you again, but you need to enable the "Append page content which possibly caused the crash to the error report" switch, so that we can see the page content. Please try to get another crash using the apk above (and enable the switch) and post it directly to #2737. Thanks :-)