Spiders
 Spiders copied to clipboard
Spiders copied to clipboard
Published
20 hours ago •
 Tactful-biao
Tactful-biao
Learn the web crawler.
项目介绍:
在这个文件夹下的爬虫程序都统一写在这个README里面, 欢迎与我交流
- 简单小爬虫
- baike.py 这是一个爬取糗事百科的简单的爬虫。详情请参考我的博客:爬取糗事百科/
- mmjpg.py 是一个爬虫程序爬取 http://www.mmjpg.com代码中已经加入了详细的注释.当然如果你还有什么不懂的,欢迎来我的博客留言:http://bbiao.me
- seed.py 是爬取电影天堂所有电影种子的一个网络爬虫。可以参考我的博客:爬取《电影天堂》所有电影种子
- mzitu.py是一个爬虫程序,爬取妹子图http://www.mzitu.com代码中加入了多线程,爬取速度是十分快的 代码没有添加注释
- ip.py 是一个获取代理的脚本(国外网站,自备梯子),里面涉及到一种巧妙的加密方式,我写在公众号里面了,感兴趣的可以关注我的公众号,公众号在最下面。也可以参考我的博客https://bbiao.me/2018/05/23/分享两个有趣的思路/
- house.py 是一个获取赶集网房源信息的爬虫(需要使用代理),保存到mysql数据库,我的《数据之美》对数据进行了分析,感兴趣的可以看看。
- house.sql 是数据库的设计。
- music.py 是获取网易云评论的一个爬虫,只实现参数破解,数据抓取,数据提取,没有保存到本地。也没有多页爬取,这些都很简单,而且我也不需要这些数据,不想继续往下写了,感兴趣的朋友可以完善下。欢迎关注公众号《一个简单程序猿》,里面有详细的解析。
-
12306
该目录下是一个爬取12306的小程序
- setup.py 这是一个python的构建工具
- station_name.py 这是一个获取12306全国所有车站的简写信息的脚本
- station.py 这个脚本里面包含两个列表,一个是车站中文名,另一个是车站的英文简写
- tickets.py 这是一个真正获取12306票数信息的脚本,脚本中对数据进行了清理
-
查询 该目录下都是一些查询的脚本.
- KY.py 是查询考研的脚本
- MHK.py 是查询MHK三级和四级成绩的脚本
- NCRE.py 是查询全国计算机二级(高级Office)的脚本
- cet_new.py 是查询大学英语四六级的一个脚本。
- movie.py 是一个资源获取的脚本(各种资源,只需给个关键词就可以获得想要的东西,自己去探索)
- 用法: python3 movie.py 想要的资源名称
 脚本中有简单的注释。如果有不了解的地方,欢迎到我的博客上留言。
脚本中有简单的注释。如果有不了解的地方,欢迎到我的博客上留言。
- 用法: python3 movie.py 想要的资源名称
-
监票脚本
该文件夹下的脚本是对12306中的脚本进行了扩展,添加了监控的功能,其实就是加入了一个发邮件的功能。详情可以参考该文件夹下的README
-
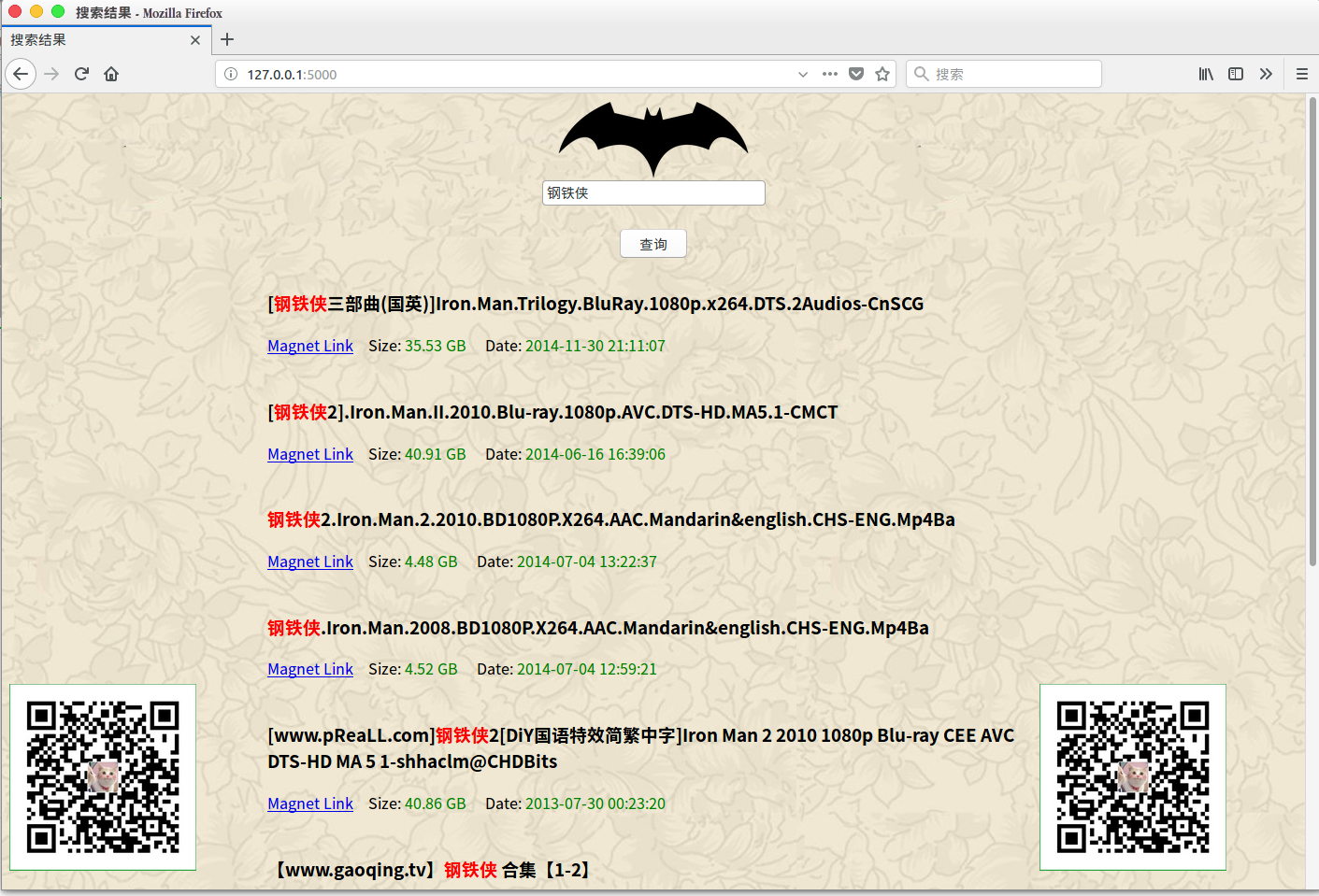
movies 该目录下是一个基于Flask的web程序,功能是资源搜索,详细功能我在我的公众号中已经介绍了。效果图如下:
-
Qzone是一个爬取QQ空间的爬虫,爬取了QQ好友的全部说说,留言,以及个人信息等数据,在我的博客中对该爬虫的思路等进行了简单的介绍 ,可以参考我的这篇文章<爬取QQ空间>
2019 年 8 月 18 日 代码再次重构,说实话我不想再继续这个项目了,因为太恶心了。。。一方面来自于空间方面(对方随便加点手段,我们就要绞尽脑汁),另一方面是要面对自己之前所写的代码(这个更恶心,看自己之前的代码有点怀疑人生,简直不忍直视,甚至想重新写一遍)。
代码已经重构,通过正则表达式。功能相同,代码优雅了一些。同时理解上也难了一些,老版本可以从我的公众号<一个简单程序员>上输入“QQ空间”获取, 欢迎关注,与我交流。
- Ubuntu 16.04 系统测试通过
- 至少Python 3.5
- 安装 selenium 并配置Phantomjs
- 安装相关依赖 pip3 install -r requirements.txt
注: del_mood和del.board 是一个批量化删除说说和留言的程序(全部删除),涉及到说说和留言删除,无法恢复,谨慎使用!
- del_mood 批量化删除说说(全部)
- del_board 批量化删除留言(全部)
谨慎使用!!!!
爬虫QZone通过Phantomjs模拟登录获取Cookies进行操作,爬取了全部好友的个人说说:
- 好友姓名(name)
- 设备(source)
- 具体内容(content)
- 发表时间(createTime)
- 转发量(forward)
- 评论内容(comment)
- 配图(pics)
- ~~点赞数(like)~~
- ~~具体点赞的人(likers, qq号, 性别, 地址, 星座))~~
留言爬取的内容包括
- 好友姓名(owner)
- 总留言数(total)
- 留言人的昵称(name)
- 留言人的qq(qq)
- 留言的时间(time)
- 留言的内容(content)
- 回复的内容(replyList(包括回复人的昵称和回复的内容))
个人档的爬取包括
- 好友空间名称(spacename)
- 好友昵称(nickname)
- 空间标语(desc)
- 性别(sex)
- 年龄(age)
- 生日(birthday)
- 星座(constellation)
- 国家(country)
- 省份(province)
- 城市(city)
- 家乡(hometown)
- 婚姻状态(marriage)
- 职业(chreer)
- 详细地址(address)
数据统一存储在mongodb中,分了四个表,分别是black(记录无法访问空间的好友), information(存储个人信息的表), board(存储留言的表), mood(存储说说的表).
另外点赞的人的爬取需要加上时间限制(大于3秒请求不会出现问题),如果不加的话,会出现系统繁忙等问题。(亲身经历)
该项目我会不断完善的,如果有什么好的建议或者疑问可以在issues中提,我会尽力解决。
我的公众号: 一个简单程序猿
