[BUG/Help] <多轮对话微调训练之后的推理脚本evaluate.sh里是否也应该增加--history_column history参数?>
Is there an existing issue for this?
- [X] I have searched the existing issues
Current Behavior
之前默认的推理脚本evaluate.sh里没有--history_column history参数,多轮对话微调训练之后推理发现指标很低,增加该参数后发现指标明显上升。
Expected Behavior
No response
Steps To Reproduce
多轮对话微调训练之后的推理脚本evaluate.sh里是否也应该增加--history_column history参数?
Environment
- OS:
- Python:3.10.9
- Transformers:4.30.2
- PyTorch:2.0.1+cu118
- CUDA Support (`python -c "import torch; print(torch.cuda.is_available())"`) :true
Anything else?
No response
问一下 您说的是加上history的时候验证模型时候发现评分变高了是吗? 这个应该不影响你推理时候的对话效果吧?
我个人是发现训练多轮时候还不如训练单轮对话的数据效果好,多轮对话 即使max_length设置很高了 对话一句两句还行 后面就无限重复前两句回答,不知道友情况如何.. :)
问一下 您说的是加上history的时候验证模型时候发现评分变高了是吗? 这个应该不影响你推理时候的对话效果吧? 我个人是发现训练多轮时候还不如训练单轮对话的数据效果好,多轮对话 即使max_length设置很高了 对话一句两句还行 后面就无限重复前两句回答,不知道友情况如何.. :)
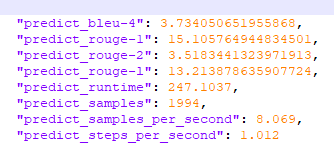
是的,这是加history之前的评分
加了history之后的评分是
评分确实高了,推理时候的对话效果应该不影响,只是看看能到多少分。单轮对话我没有训练过,只训练的多轮对话,效果分情况,有的表现好,有的表现差,我怀疑可能是数据样本不平衡造成的,我的数据是自己整理的也不多,数据这块挺花费时间的,我目前还在改数据。
问一下你说的是加上历史的时候验证模型的时候发现评分变高了是吗?这个应该不会影响你推理时候的对话效果吧?我个人是发现训练多轮的时候还不如训练单轮对话的数据效果好,多轮对话即使max_length设置了很开心了对话一句两句还行后面就无限重复前两句回答,不知道朋友情况如何..:)
是的,这是加历史之前的评分 加了历史之后的评分是 评分确实高了,推理时候的对话效果应该不影响,只是看看能到多少分。单轮对话我没有训练过,只训练的多轮对话,效果分情况,有的表现好,有的表现差,我怀疑可能是数据样本不平衡造成的,我的数据是自己整理的也不是多,数据这块挺费时间的,我目前仍在修改数据。

你表现好的模型 能进行几轮有效对话呢 不知道有没有出现发什么模型都回复同一句话的情况呢。
问一下你说的是加上历史的时候验证模型的时候发现评分变高了是吗?这个应该不会影响你推理时候的对话效果吧?我个人是发现训练多轮的时候还不如训练单轮对话的数据效果好,多轮对话即使max_length设置了很开心了对话一句两句还行后面就无限重复前两句回答,不知道朋友情况如何..:)
是的,这是加历史之前的评分 加了历史之后的评分是 评分确实高了,推理时候的对话效果应该不影响,只是看看能到多少分。单轮对话我没有训练过,只训练的多轮对话,效果分情况,有的表现好,有的表现差,我怀疑可能是数据样本不平衡造成的,我的数据是自己整理的也不是多,数据这块挺费时间的,我目前仍在修改数据。
你表现好的模型 能进行几轮有效对话呢 不知道有没有出现发什么模型都回复同一句话的情况呢。
我在训练集上也测试了,有的能正常对话四五轮,后面的就不按训练集答复了,也会出现问同一句话模型都回复同一句话的情况,但是换一句话问,模型回复也会变,不是发什么模型都回复同一句话,也可能我测试的还不够多,我目前用的max_source_length是768,我训练了100个epoch,感觉训练集记住的太少,没有达到这个长度,不知你设置的多大?
问一下你说的是加上历史的时候验证模型的时候发现评分变高了是吗?这个应该不会影响你推理时候的对话效果吧?我个人是发现训练多轮的时候还不如训练单轮对话的数据效果好,多轮对话即使max_length设置了很开心了对话一句两句还行后面就无限重复前两句回答,不知道朋友情况如何..:)
是的,这是加历史之前的评分 加了历史之后的评分是 评分确实高了,推理时候的对话效果应该不影响,只是看看能到多少分。单轮对话我没有训练过,只训练的多轮对话,效果分情况,有的表现好,有的表现差,我怀疑可能是数据样本不平衡造成的,我的数据是自己整理的也不是多,数据这块挺费时间的,我目前仍在修改数据。
你表现好的模型 能进行几轮有效对话呢 不知道有没有出现发什么模型都回复同一句话的情况呢。
我在训练集上也测试了,有的能正常对话四五轮,后面的就不按训练集答复了,也会出现问同一句话模型都回复同一句话的情况,但是换一句话问,模型回复也会变,不是发什么模型都回复同一句话,也可能我测试的还不够多,我目前用的max_source_length是768,我训练了100个epoch,感觉训练集记住的太少,没有达到这个长度,不知你设置的多大?
这边总是看不到信息 [email protected] 这是我邮箱给我发你联系方式 咱们详谈
问一下你说的是加上历史的时候验证模型的时候发现评分变高了是吗?这个应该不会影响你推理时候的对话效果吧?我个人是发现训练多轮的时候还不如训练单轮对话的数据效果好,多轮对话即使max_length设置了很开心了对话一句两句还行后面就无限重复前两句回答,不知道朋友情况如何..:)
是的,这是加历史之前的评分 加了历史之后的评分是 评分确实高了,推理时候的对话效果应该不影响,只是看看能到多少分。单轮对话我没有训练过,只训练的多轮对话,效果分情况,有的表现好,有的表现差,我怀疑可能是数据样本不平衡造成的,我的数据是自己整理的也不是多,数据这块挺费时间的,我目前仍在修改数据。
你表现好的模型 能进行几轮有效对话呢 不知道有没有出现发什么模型都回复同一句话的情况呢。
我在训练集上也测试了,有的能正常对话四五轮,后面的就不按训练集答复了,也会出现问同一句话模型都回复同一句话的情况,但是换一句话问,模型回复也会变,不是发什么模型都回复同一句话,也可能我测试的还不够多,我目前用的max_source_length是768,我训练了100个epoch,感觉训练集记住的太少,没有达到这个长度,不知你设置的多大?
你好,请问解决了吗,我也遇到了这个问题