google.protobuf.message.DecodeError: Error parsing message with type 'sentencepiece.ModelProto'
raise "google.protobuf.message.DecodeError: Error parsing message with type 'sentencepiece.ModelProto'"
protobuf==3.20.0
Could you please give the full error log. Specifically, I need to know which line this error occurs on.
Alright.
Explicitly passing a revision is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Traceback (most recent call last):
File "web_demo.py", line 4, in
Alright.
Explicitly passing a
revisionis encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision. Traceback (most recent call last): File "web_demo.py", line 4, in tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) File "/home/users/chenxu.wang/anaconda3/envs/hdflow/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 658, in from_pretrained return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs) File "/home/users/chenxu.wang/anaconda3/envs/hdflow/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1804, in from_pretrained return cls._from_pretrained( File "/home/users/chenxu.wang/anaconda3/envs/hdflow/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 1959, in _from_pretrained tokenizer = cls(*init_inputs, **init_kwargs) File "/home/users/chenxu.wang/.cache/huggingface/modules/transformers_modules/local/tokenization_chatglm.py", line 214, in init self.sp_tokenizer = SPTokenizer(vocab_file) File "/home/users/chenxu.wang/.cache/huggingface/modules/transformers_modules/local/tokenization_chatglm.py", line 35, in init self.text_tokenizer = self._build_text_tokenizer(encode_special_tokens=False) File "/home/users/chenxu.wang/.cache/huggingface/modules/transformers_modules/local/tokenization_chatglm.py", line 67, in _build_text_tokenizer tokenizer = TextTokenizer(self.vocab_file) File "/home/users/chenxu.wang/anaconda3/envs/hdflow/lib/python3.8/site-packages/icetk/text_tokenizer.py", line 26, in init self.proto.ParseFromString(proto_str) google.protobuf.message.DecodeError: Error parsing message with type 'sentencepiece.ModelProto'
Are you sure you correctly downloaded the ice_text.model file? The correct file size should be about 2.7MB.
I have the same error. I have downloaded model files from huggingface, model files as followed


I have the same error. I have downloaded model files from huggingface, model files as followed
@jamestch You also need to download the ice_text.model file.
You need to install
git lfsto download large models from hf.
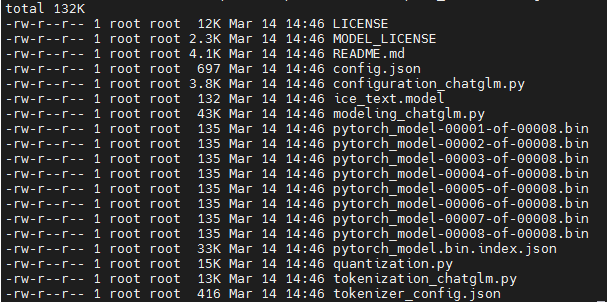
I have installed git lfs, model files showed above is downloaded from huggingface by command git clone https://huggingface.co/THUDM/chatglm-6b
I have the same error. I have downloaded model files from huggingface, model files as followed
@jamestch You also need to download the
ice_text.modelfile.
I have downloaded the ice_text.model file correctly since the SHA256 is right. But it did not work
I met the same error when loading the pre-trained LLaMA-2-7b model using the function AutoTokenizer.from_pretrained().
After setting use_fast=True, this error was fixed.
Finally, I re-downloaded the tokenizer-relevant files and solved this issue. Take the LLaMA-2-7b-hf as an example, update the files as below:
- special_tokens_map.json
- tokenizer_config.json
- tokenizer.json
- tokenizer.model