ChatGLM-6B
 ChatGLM-6B copied to clipboard
ChatGLM-6B copied to clipboard
[Help] <title>p-tuning的prefix加在transformer哪些层?
Is there an existing issue for this?
- [X] I have searched the existing issues
Current Behavior
p-tuning v2文章里说把prefix加在transformer第21至24层效果比较好,如图。
请问本仓库p-tuning实现的是把prefix加在21-24层吗?这个设置是在代码的那一部分呢?
Expected Behavior
答疑
Steps To Reproduce
无
Environment
OS: Ubuntu 20.04
Python: 3.8
Transformers: 4.26.1
PyTorch: 1.12
CUDA Support: True
Anything else?
No response
根据transformer pretrained mode的api:https://huggingface.co/docs/transformers/main_classes/model
Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keeping the model weights fixed.
在p-tuning的main.py中有这个方法:
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
enable_input_require_grads这个方法是启动模型input embedding层的梯度。 所以我理解是p-tuning调整的是input_embedding?
https://github.com/huggingface/transformers/blob/a7920065f2cfd2549b838f9a30afd7c265fcdd88/src/transformers/modeling_utils.py#L1185
def enable_input_require_grads(self):
"""
Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keeping
the model weights fixed.
"""
def make_inputs_require_grads(module, input, output):
output.requires_grad_(True)
self._require_grads_hook = self.get_input_embeddings().register_forward_hook(make_inputs_require_grads)
根据transformer pretrained mode的api:https://huggingface.co/docs/transformers/main_classes/model
Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keeping the model weights fixed.
在p-tuning的main.py中有这个方法:
model.gradient_checkpointing_enable() model.enable_input_require_grads()enable_input_require_grads这个方法是启动模型input embedding层的梯度。 所以我理解是p-tuning调整的是input_embedding?
感谢回复,p-tuning的确是微调一个pre_seq_len长度的continuous prompts,加在transformer的一层或多层。论文说加在更深的层中效果更好,所以不确定这里的实现是加在哪些层,以及在什么地方设置。NLP萌新,理解不当麻烦指教。
看源码,实现在所有层了。 源码位置在modeling_chatglm.py 136行,和ptuning v2,代码一致。
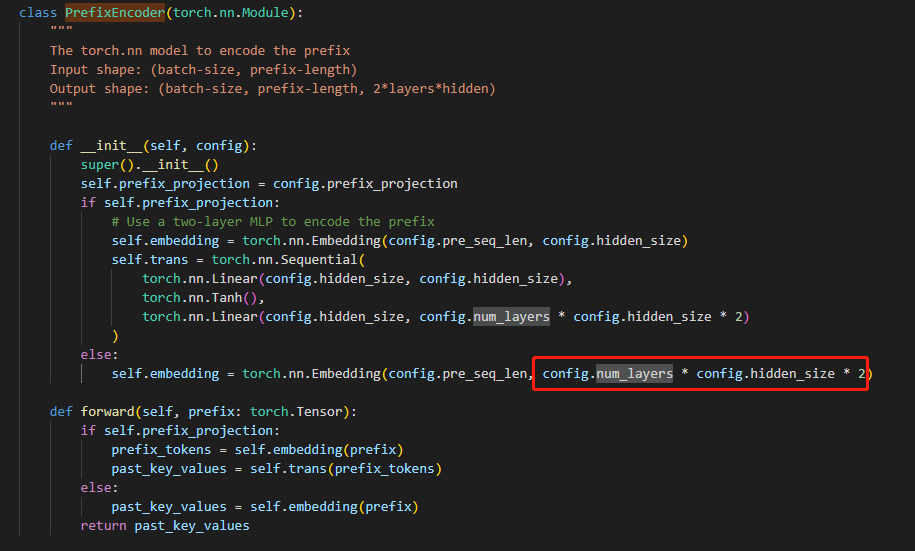
您好,多问一句,PrefixEncoder的forward函数的输入是什么?我看论文中的图应该指的是pre_seq_len的tokens作为输入?
看源码,实现在所有层了。 源码位置在modeling_chatglm.py 136行,和ptuning v2,代码一致。
您好,多问一句,PrefixEncoder的forward函数的输入是什么?我看论文中的图应该指的是pre_seq_len的tokens作为输入?
PrefixEncoder的输入是固定的
torch.arange(self.pre_seq_len).long()