睿驰
## 相关资料 * [什么是卫语句?更优雅的代码方式](https://cloud.tencent.com/developer/article/1783577) * [知乎 - 如何写好业务代码?](https://www.zhihu.com/question/60761181)
> 转载自【金融级分布式架构】SOFAJRaft-RheaKV 分布式锁实现剖析:https://mp.weixin.qq.com/s/ahcbgxWVVmRwrH9Y4-gXBA SOFAJRaft 是一个基于 Raft 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。 本文为《剖析 | SOFAJRaft 实现原理》第七篇,本篇作者米麒麟,来自陆金所。《剖析 | SOFAJRaft 实现原理》系列由 SOFA 团队和源码爱好者们出品,项目代号:,文末包含往期系列文章。 SOFAJRaft : https://github.com/sofastack/sofa-jraft ## 导读 在分布式部署、高并发、多线程场景下,我们经常会遇到资源的互斥访问的问题,最有效、最普遍的方法是给共享资源或者对共享资源的操作加一把锁。在 JDK 中我们可以使用 ReentrantLock 重入锁或者 synchronized...
> 转载自 【阿里巴巴云原生】基于 Istio 的全链路灰度方案探索和实践:https://mp.weixin.qq.com/s/nsN-FvTnixi-iOKeOmko4A
## 关于Redis热点key的一些思考 昨天在和一个已经跳槽的同事聊天时,询问他这段时间面试时碰到的一些问题。自己也想积累一下这方面的知识。其中他说了在面试某赞公司时面试官问他关于热点Key的的解决方案。于是针对这次谈话以及上网查的一些资料后的思考进行一下总结。方便后续自己查阅。 ## 什么是热点Key 其实对于热点Key,网上一查一大堆,这里我就引用网上的一段话。 从基于用户消费的数据远远大于生产的数据的角度来讲,我们平常使用的知乎等软件时,大多数人平常仅仅只是浏览,并不会去提问问题、发表的文章,偶尔会发表自己的文章或者看法,这就是一个典型的读多写少的情景,当然此类情景不太容易导致热点的产生。 在日常工作生活中一些突发的的事件,诸如:“双11”期间某些热门商品的降价促销,当这其中的某一件商品被数万次点击、购买时,会形成一个较大的需求量,这种情况下就会产生一个单一的Key,这样就会引起一个热点;同理,当被大量刊发、浏览的热点新闻,热点评论等也会产生热点;另外,在服务端读数据进行访问时,往往会对数据进行分片切分,此类过程中会在某一主机Server上对相应的Key进行访问,当访问超过主机Server极限时,就会导致热点Key问题的产生。 ## 怎么发现热key **方法一**:凭借业务经验,进行预估哪些是热key 其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。 **方法二**:在客户端进行收集 这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。 **方法三**:在Proxy层做收集 有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy。 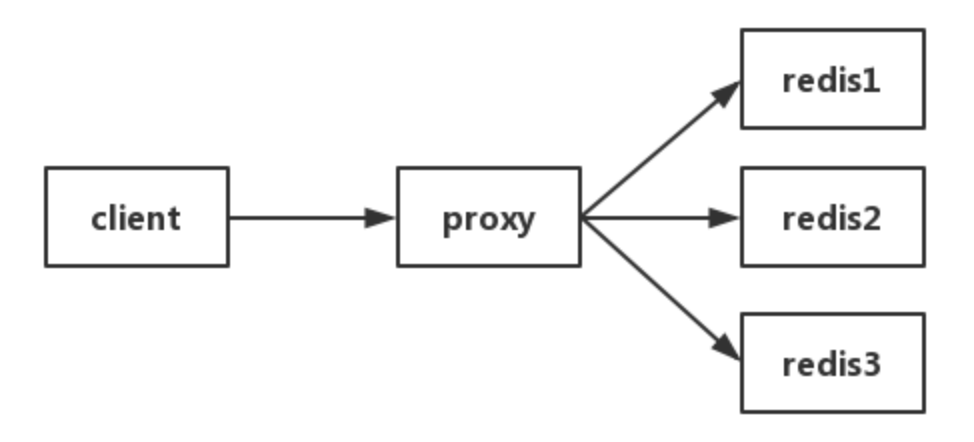 **方法四**:用redis自带命令 * monitor命令,该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。 * hotkeys参数,redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢。 **方法五**:自己抓包评估 Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性。 以上五种方案,各有优缺点。根据自己业务场景进行抉择即可。那么发现热key后,如何解决呢? ## 如何解决? 针对于热点Key的解决方案 笔者了解到的有如下3种:...
> 转载自 【阿里云云栖号】如何计算Java对象所占内存的大小:https://segmentfault.com/a/1190000015009289 本文以如何计算Java对象占用内存大小为切入点,在讨论计算Java对象占用堆内存大小的方法的基础上,详细讨论了Java对象头格式并结合JDK源码对对象头中的协议字段做了介绍,涉及内存模型、锁原理、分代GC、OOP-Klass模型等内容。最后推荐JDK自带的Hotspot Debug工具——HSDB,来查看对象在内存中的具体存在形式,以论证文中所述内容。 ## 背景 目前我们系统的业务代码中大量使用了LocalCache的方式做本地缓存,而且cache的maxSize通常设的比较大,比如10000。我们的业务系统中就使用了size为10000的15个本地缓存,所以最坏情况下将可缓存15万个对象。这会消耗掉不菲的本地堆内存,而至于实际上到底应该设多大容量的缓存、运行时这大量的本地缓存会给堆内存带来多少压力,实际占用多少内存大小,会不会有较高的缓存穿透风险,目前并不方便知悉。考虑到对缓存实际占用内存的大小能有个更直观和量化的参考,需要对运行时指定对象的内存占用进行评估和计算。 要计算Java对象占用内存的大小,首先需要了解Java对象在内存中的实际存储方式和存储格式。 另一方面,大家都了解Java对象的存储总得来说会占用JVM内存的堆内存、栈内存及方法区,但由于栈内存中存放的数据可以看做是运行时的临时数据,主要表现为本地变量、操作数、对象引用地址等。这些数据会在方法执行结束后立即回收掉,不会驻留。对存储空间空间的占用也只是执行函数指令时所必须的空间。通常不会造成内存的瓶颈。而方法区中存储的则是对象所对应的类信息、函数表、构造函数、静态常量等,这些信息在类加载时(按需)只会在方法区中存储一份,不会产生额外的存储空间。因此本文所要讨论的主要目标是Java对象对堆内存的占用。 ## 内存占用计算方法 如果读者关心对象在JVM中的存储原理,可阅读本文后边几个小节中关于对象存储原理的介绍。如果不关心对象存储原理,而只想直接计算内存占用的话,其实并不难,笔者这里总结了三种方法以供参考: * 使用java.lang.instrument.Instrumentation.getObjectSize()方法,可以很方便的计算任何一个运行时对象的大小,返回该对象本身及其间接引用的对象在内存中的大小。 * 使用sun.misc.Unsafe类,有一个objectFieldOffset(Field f)方法,表示获取指定字段在所在实例中的起始地址偏移量,如此可以计算出指定的对象中每个字段的偏移量,值为最大的那个就是最后一个字段的首地址,加上该字段的实际大小,就能知道该对象整体的大小。 * 通过OpenJDK官方提供的JOL(Java Object Layout)工具,用来分析JVM中对象布局的工具,它可以帮我们在运行时计算某个对象的大小。 * 使用第三方工具:这里要介绍的是lucene提供的专门用于计算堆内存占用大小的工具类:RamUsageEstimator ## Java 对象内存布局 HotSpot JVM 使用名为...
> 转载自 【有赞技术】有赞流量回放在中台营销的实践:https://mp.weixin.qq.com/s/rlqXjr17u70nm1mgD8-r0g ## 一、流量回放介绍 ### 1.1 流量回放是什么 流量回放是系统重构、拆分、中台化时重要的自动化回归手段。通过采集可录制流量,在指定环境回放,再逐一对比每个调用和子调用差异来发现接口代码是否存在问题。因为线上流量大、场景全面,可以有效弥补人工评估测试范围的局限性,进而降低业务快速迭代带来的风险。流量回放的整体流程图如下图所示。 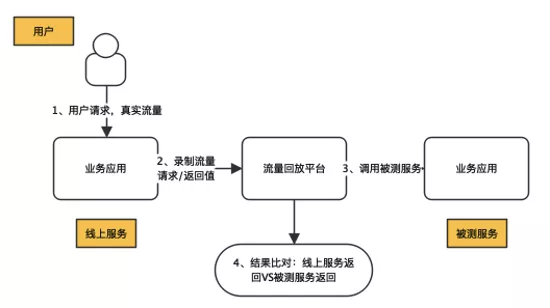 ### 1.2 有赞流量回放平台介绍 有赞流量回放平台是基于jvm-sandbox-repeater做的二次开发。通过AOP在运行期无侵入式(业务系统无感知)录制接口入参/返回值。同时可以录制子调用的入参和返回值,子调用类型包括dubbo、mybatis、redis等。因此在支持读流量回放的基础上,可以支持写流量的mock回放。整体架构如下图所示。 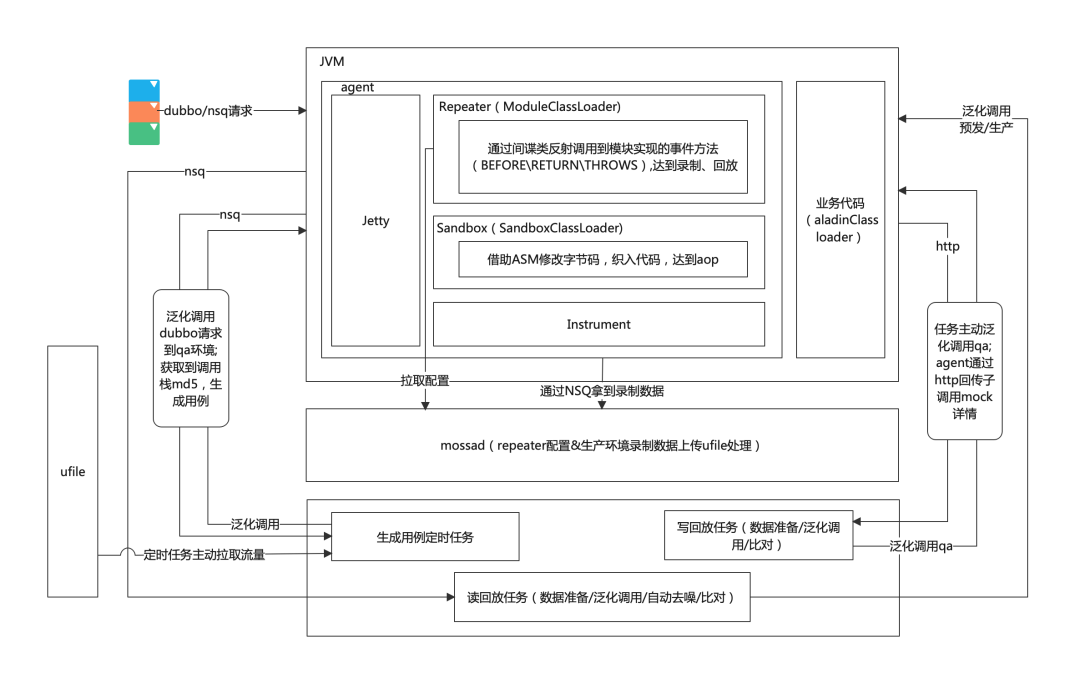 下面详细介绍下有赞流量回放平台的两个模式,读模式(pre环境读接口非mock回放)和写模式(qa环境接口mock回放)。
先看一下Redis官方对Lua脚本的解释:https://redis.io/commands/eval > Atomicity of scripts > > Redis uses the same Lua interpreter to run all the commands. Also Redis guarantees that a script is executed in an atomic way:...
我们知道在分布式系统中,一个后端服务可能被分开部署了多台服务器。想要统计实时的在线人数,需要借助一个中间件,我这里用的是redis。 这里必须说明一点,很多情况下,用户是不会手动点击登出按钮的,所以我们无法拿到一个非常精确的实时在线的一个数据,只能拿到一个近似实时的一个值。 本文就会给出几种设计方案,来分析下各个方案的优缺点: | 分案 | 概述 | 优缺点 | | --- | --- | --- | | 使用有序集合 | 这种方案能够同时储存在线的用户 和 用户上线时间,能够执行非常多的聚合计算,但是所消耗的内存也是非常可观的。| | | 使用集合 | 这种方案能储存在线的用户,也能够执行一定的聚合计算,相对有序集合,所消耗的内存要小些,但是随着用户量的增多,消耗内存空间也处于增加状态 | |...
## 一、Sentinel 是什么? 随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。 [Sentinel](https://github.com/alibaba/Sentinel/wiki/%E4%BB%8B%E7%BB%8D) 具有以下特征: * 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。 * 完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。 * 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。 *...
> 转载自 【RocketMQ官微】RocketMQ消息幂等的通用解决方案:https://mp.weixin.qq.com/s/X25Jw-sz3XItVrXRS6IQdg