Simple-Hourglass
 Simple-Hourglass copied to clipboard
Simple-Hourglass copied to clipboard
Simplified implementation about FCN-8, U-Net and RedNet in tensorflow with simple dataset
Simple Hourglass
![]()
![]()
Abstract
This repository demonstrates how to use Ear-Pen dataset project to train the model and complete the recognition task. The training data is from here. The architecture of these models are just like the horizontal hourglass and they really did the good job in such these tasks. The tasks include pixel segmentation, object recognition, denoising, super-resolution...etc.
Introduction
In 2015, the fully convolutional neural network (FCN) bring a big bang to the recognition territory[1]. From then on, there're many similar but creative model that had been created. The models included U-Net[2], SegNet, DeconvNet and very deep residual encoder decoder (RedNet)...etc[3]. In these project, FCN, UNet and RedNet are implemented to do the object recognition. The goal is to recognize and localize the target toward green earphone and red pen.
Unfortunately, there is still some trouble to implement pooling indice mechanism which will be adopt in SegNet and DeconvNet. Moreover, there's only GPU implementation toward max pooling with argmax mask in tensorflow. As the result, the both model will not be mentioned in this project.
Architecture
The following image illustrates the architecture of three models in order.

Result
In my experiment, the images and annotations are both shrieked for 10 times. As the result, the size of the data is 104*78. In each model, the program trained it for 500 epochs. For each model, we adpot 32 as the base number of filter. On the other words, we use the standard VGG structure to extract the image representation. The testing results are shown below:
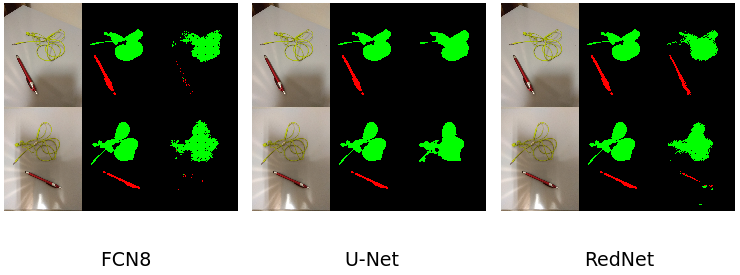
There're 200 training image which are generated by generate.py script. On the contrary, there're only 2 testing image. In the above image, the results of three model are shown paralleled. In each area, three sub-regions are split. the most left sub-region is original image, the middle one is ground truth and the right region is prediction.
 The above image shows the converge phenomenon of the three models. The vertical axis represents the log scale of the loss value. I record the loss value for each 20 epochs. To avoid the first loss value lead the image that cannot shows the detail of the backward converge situation, I change the first loss value as the value in last time period. As you can see, the whole three models can converge finally.
The above image shows the converge phenomenon of the three models. The vertical axis represents the log scale of the loss value. I record the loss value for each 20 epochs. To avoid the first loss value lead the image that cannot shows the detail of the backward converge situation, I change the first loss value as the value in last time period. As you can see, the whole three models can converge finally.

There's one testing video which are provided to evaluate the performance with practical situation. As you can see, the U-Net model are hardly to predict the red pen. However, the RedNet model can capture more detail of the image which is more sensitive to the environment.
Hardward and recommend
In theory, you don't need to use GPU to train and test the model. However, to accelerate the training process and enhance the performance, GTX-1070 was adopted in my work. The first reason is that 32 is a great basis number of filter in each architecture. However, the computation is very slow if you assign 32 as the basis number. Second, the RedNet has more matrix computation which CPU isn't talent in. As these reason, I recommend you to use GPU to train the model. According to my experience, 3 day should be spent if you want to train for 3 models.
TODO
- use more large images and annotations
- train for more epochs
Reference
[1] J.Long, E.Shelhamer, andT.Darrell, “Fully Convolutional Networks for Semantic Segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 4, pp. 640–651, Nov.2014.
[2] O.Ronneberger, P.Fischer, andT.Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation,” Miccai, vol. 9351, no. Pt 1, pp. 234–241, May2015.
[3] X.-J.Mao, C.Shen, andY.-B.Yang, “Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections.”