[BUG] <em> then return to line introduces a supplementary space
String htmlItalic1 = '''
<p>
<em>
Italic stuff
</em>
, normal stuff.
</p>
''';
String htmlItalic2 = '''
<p>
<em>Italic stuff</em>
, normal stuff.
</p>
''';
void main() {
runApp(
MaterialApp(
home: Scaffold(
appBar: AppBar(),
body: Column(
children: [
Html(data: htmlItalic1,),
Html(data: htmlItalic2,),
Html.fromDom(document: parse(htmlItalic1),),
Html.fromDom(document: parse(htmlItalic2),),
],
),
),
),
);
}
Running this, you will see the following :

However, putting this into a .html and rendering it in Chrome gives out this :
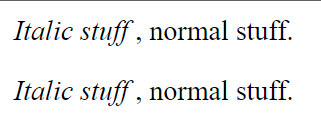
<p>
<em>
Italic stuff
</em>
, normal stuff.
</p>
<p>
<em>Italic stuff</em>
, normal stuff.
</p>
Done with Flutter 2.8 and flutter_html 2.2.1.
Bumping this : It seems Chrome handles this in the background, only keeping once space between other stuff and adding a space between pure text elements if needed, as can be seen by opening this HTML in Chrome :
<p>
<span>BEFORE</span>
<em>
<span>TEXT </span>
</em>
<span>AFTER</span>
</p>
It would be nice to have an option handling this.
Here's a fix I'm applying that seems to work in my case. It doesn't handle trimming preceding spaces, but Chrome doesn't seem to either so I'm sticking to that.
void treatEm(Document doc) {
// Treat the content so we don't have double spaces around <em> nodes
// https://github.com/Sub6Resources/flutter_html/issues/974
for(Node em in doc.querySelectorAll('em')) {
em.text = em.text?.trim();
// Delete the preceding node if it is pure emptiness ("\n " for example)
int indexEm = em.parent!.nodes.indexOf(em);
if(indexEm > 0) {
if(em.parent!.nodes[indexEm-1].text?.trim().isEmpty ?? false) {
em.parent!.nodes.removeAt(indexEm-1);
}
}
}
}
Edit : fixed the fixing
Encountered more cases
static void treatEm(Document doc) {
// Treat the content so we don't have double spaces around <em> nodes.
// https://github.com/Sub6Resources/flutter_html/issues/974
for(Element em in doc.querySelectorAll('em')) {
// Is one of the nodes a <span> surrounded by emptiness ?
// If yes, remove the emptiness.
Node? span = em.querySelector('span');
if(span != null) {
int indexSpan = em.nodes.indexOf(span);
if(indexSpan > -1) {
if(
indexSpan < em.nodes.length-1
&& em.nodes[indexSpan+1].nodeType == Node.TEXT_NODE
&& (em.nodes[indexSpan+1].text ?? '').trim().isEmpty
) em.nodes.removeAt(indexSpan+1);
if(
indexSpan > 0
&& em.nodes[indexSpan-1].nodeType == Node.TEXT_NODE
&& (em.nodes[indexSpan-1].text ?? '').trim().isEmpty
) em.nodes.removeAt(indexSpan-1);
}
}
// Now we might still have something like :
// <p>Some text <em>Italic </em> some more text.
// I don't know why but some text is formatted with 2 spaces :
// One trailing the <em> and one beginning the next bit of text.
// We check for that on the left and right and trim if needed.
int indexEm = em.parent!.nodes.indexOf(em);
int len = em.parent!.nodes.length;
if(indexEm > -1 && em.text.endsWith(' ') && indexEm < len-1)
if(em.parent!.nodes[indexEm+1].text?.startsWith(' ') ?? false)
em.text = em.text.trimRight();
if(indexEm > 0 && em.text.startsWith(' '))
if(em.parent!.nodes[indexEm-1].text?.endsWith(' ') ?? false)
em.text = em.text.trimLeft();
// We then do the same thing for the <em> :
// Delete the surrounding nodes if it is pure emptiness ("\n " for example).
// Only if no span was uncovered.
if(em.parent == null || span == null) continue;
if(indexEm > 0) {
if(
indexEm < em.parent!.nodes.length-1
&& em.parent!.nodes[indexEm+1].nodeType == Node.TEXT_NODE
&& (em.parent!.nodes[indexEm+1].text ?? '').trim().isEmpty
) em.parent!.nodes.removeAt(indexEm+1);
if(
indexEm > 0
&& em.parent!.nodes[indexEm-1].nodeType == Node.TEXT_NODE
&& (em.parent!.nodes[indexEm-1].text ?? '').trim().isEmpty
) em.parent!.nodes.removeAt(indexEm-1);
}
}
// Works to test with :
//
// Has a single space parsed in between 2 <em> at 'because he certainly'.
// https://archiveofourown.org/works/25172989
//
// 'The List!' must be like that, 'Too calmly' like that. Chapt 3 has 'I had sex with Batman'.
// https://archiveofourown.org/works/36282724/chapters/93382831
//
// This has double trailing spaces, and sometimes a space before the punctuation ('egg .').
// https://archiveofourown.org/works/37469116/chapters/93508141
}
Edit : The previous method was too good and parsed 2 spaces around an if their were two, whereas modern browsers seem to get rid of them automatically, so I adapted to this paradigm. Oh well.