stable-baselines3-contrib
 stable-baselines3-contrib copied to clipboard
stable-baselines3-contrib copied to clipboard
IQN
Description
Context
- [ ] I have raised an issue to propose this change (required)
Types of changes
- [ ] Bug fix (non-breaking change which fixes an issue)
- [x] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
- [ ] Documentation (update in the documentation)
Checklist:
- [x] I've read the CONTRIBUTION guide (required)
- [ ] The functionality/performance matches that of the source (required for new training algorithms or training-related features).
- [ ] I have updated the tests accordingly (required for a bug fix or a new feature).
- [ ] I have included an example of using the feature (required for new features).
- [ ] I have included baseline results (required for new training algorithms or training-related features).
- [ ] I have updated the documentation accordingly.
- [ ] I have updated the changelog accordingly (required).
- [x] I have reformatted the code using
make format(required) - [ ] I have checked the codestyle using
make check-codestyleandmake lint(required) - [ ] I have ensured
make pytestandmake typeboth pass. (required)
Note: we are using a maximum length of 127 characters per line
Results comparison
| Current implementation | Reference |
|---|---|
(6 seeds)  |
from https://github.com/toshikwa/fqf-iqn-qrdqn.pytorch (1 seed, same parameters)  |
 |
(2 seeds, same parameters)  |
https://di-engine-docs.readthedocs.io/en/latest/12_policies/iqn.html#benchmark 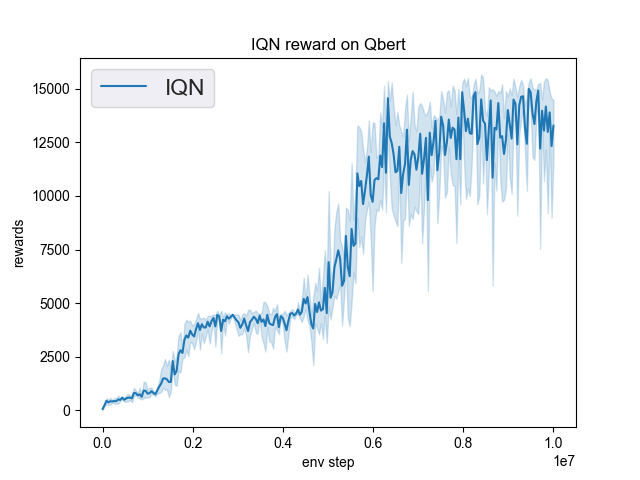 |
@qgallouedec Thank you for adding this. I wanted to report that for me it works well and I was able to adapt it to implement the paper Self-Imitation Advantage Learning . I'm not sure how useful it is for you but I'm happy to share my modifications to add SAIL-IQN to your IQN implementation (I don't have the resources right now to submit this as a separate PR):
New replay buffer to store discounted returns (G):
import warnings
import itertools
from typing import Generator, Optional, Union, NamedTuple, List, Dict, Any
import numpy as np
import torch as th
from stable_baselines3.common.type_aliases import ReplayBufferSamples, RolloutBufferSamples
from stable_baselines3.common.buffers import ReplayBuffer
from stable_baselines3.common.vec_env import VecNormalize
from gymnasium import spaces
PLACEHOLDER_RETURN_VALUE = np.finfo(np.float32).min
class SAILReplayBufferSamples(NamedTuple):
observations: th.Tensor
actions: th.Tensor
next_observations: th.Tensor
dones: th.Tensor
rewards: th.Tensor
returns: th.Tensor
class SAILReplayBuffer(ReplayBuffer):
def __init__(
self,
buffer_size: int,
observation_space: spaces.Space,
action_space: spaces.Space,
device: Union[th.device, str] = "cpu",
n_envs: int = 1,
optimize_memory_usage: bool = False,
gamma: float = 0.99
):
super().__init__(buffer_size, observation_space, action_space, device, n_envs, optimize_memory_usage)
## TODO: Haven't looked at supporting optimize_memory_usage true yet
# assert optimize_memory_usage == False, 'optimize_memory_usage does not work with SAIL currently'
self.gamma = gamma
self.returns = np.zeros((self.buffer_size, self.n_envs), dtype=np.float32)
# For each env store where the episode starts (0 for all envs at the beginning)
# but will vary as each episode can end at a different point
self.episode_start_indices = np.zeros(self.n_envs, dtype=np.int32)
def update_episodic_return(self, completed_env_indices: np.ndarray, episode_end_idx: int):
# completed_env_indices - indices of envs with completed episode
# For all episodes that have ended episode_end_pos will contain the end position though
# it may be infrequent for multiple episodes to end at the same position
for env_idx in completed_env_indices:
# episode_start_idx can be > episode_end_idx due to buffer wrap-around
episode_start_idx = self.episode_start_indices[env_idx]
G = 0
x = 0
i = episode_end_idx # index used to calculate discounted return
if episode_start_idx < episode_end_idx:
max_episode_steps = episode_end_idx - episode_start_idx
else:
# This won't be accurate if we've wrapped around more than once but we should somewhere require
# max_episode_steps to be less than buffer size to prevent that from happening.
max_episode_steps = self.buffer_size - episode_end_idx + episode_start_idx
while x <= max_episode_steps:
G = self.rewards[i, env_idx] + self.gamma * G
self.returns[i, env_idx] = G
i = (i - 1) % self.buffer_size
x += 1
pass
pass
def add(
self,
obs: np.ndarray,
next_obs: np.ndarray,
action: np.ndarray,
reward: np.ndarray,
done: np.ndarray,
infos: List[Dict[str, Any]],
) -> None:
# we want position before it gets updated
pos = self.pos
super().add(obs=obs, next_obs=next_obs, action=action, reward=reward, done=done, infos=infos)
self.returns[pos] = np.repeat(PLACEHOLDER_RETURN_VALUE, repeats=self.n_envs)
if np.any(done):
# Only use dones that are not due to timeouts
true_dones = done * (1 - self.timeouts[pos])
if np.any(true_dones):
self.update_episodic_return(np.flatnonzero(true_dones), pos)
# Update episode start indices (whether due to timeout or not) to the current start index
# of the next episode (self.pos)
np.put_along_axis(self.episode_start_indices, np.flatnonzero(done), self.pos, axis=0)
pass
return
def sample(self, batch_size: int, env: Optional[VecNormalize] = None) -> SAILReplayBufferSamples:
# noinspection PyTypeChecker
return super().sample(batch_size=batch_size, env=env)
def _get_samples(self, batch_inds: np.ndarray, env: Optional[VecNormalize] = None) -> SAILReplayBufferSamples:
# Sample randomly the env idx
env_indices = np.random.randint(0, high=self.n_envs, size=(len(batch_inds),))
if self.optimize_memory_usage:
next_obs = self._normalize_obs(self.observations[(batch_inds + 1) % self.buffer_size, env_indices, :], env)
else:
next_obs = self._normalize_obs(self.next_observations[batch_inds, env_indices, :], env)
data = (
self._normalize_obs(self.observations[batch_inds, env_indices, :], env),
self.actions[batch_inds, env_indices, :],
next_obs,
# Only use dones that are not due to timeouts
# deactivated by default (timeouts is initialized as an array of False)
(self.dones[batch_inds, env_indices] * (1 - self.timeouts[batch_inds, env_indices])).reshape(-1, 1),
self._normalize_reward(self.rewards[batch_inds, env_indices].reshape(-1, 1), env),
self.returns[batch_inds, env_indices]
)
return SAILReplayBufferSamples(*tuple(map(self.to_torch, data)))
and updated training loop:
# Sample replay buffer
replay_data = self.replay_buffer.sample(batch_size, env=self._vec_normalize_env)
with th.no_grad():
# BEGIN - SAIL addition.
rewards = replay_data.rewards
# Ref to https://github.com/google-research/google-research/blob/master/sail_rl/agents/sail_iqn.py
# Calculates **current state** action-values.
# Shape: batch_size x n_quantiles x num_actions.
replay_target_net_outputs = self.quantile_net_target(replay_data.observations, self.n_quantiles)
# Shape: batch_size x num_actions
replay_target_q_values = replay_target_net_outputs.mean(dim=1)
replay_action_one_hot = th.nn.functional.one_hot(replay_data.actions.squeeze(-1), self.action_space.n).type(th.float32)
replay_target_q = th.max(replay_target_q_values, dim=1).values
replay_target_q_al = th.sum(replay_action_one_hot * replay_target_q_values, dim=1)
comp_value = th.max(replay_target_q_al, replay_data.returns)
if self.clip > 0.:
sil_bonus = self.alpha * th.clamp(comp_value - replay_target_q, min=-self.clip, max=self.clip)
else:
sil_bonus = self.alpha * (comp_value - replay_target_q)
rewards = rewards + sil_bonus.unsqueeze(-1)
# END - SAIL addition
# Compute the quantiles of next observation
next_quantiles = self.quantile_net_target(replay_data.next_observations, self.n_quantiles)
# Shape of next_quantiles:
# batch_size x n_quantiles x num_actions.
# e.g. if num_actions is 2, it might look something like this:
# Vals for Quantile .2 Vals for Quantile .4 Vals for Quantile .6
# [[0.1, 0.5], [0.15, -0.3], [0.15, -0.2]]
# Q-values = [(0.1 + 0.15 + 0.15)/3, (0.5 + 0.15 + -0.2)/3].
# Compute the greedy actions which maximize the next Q values
next_greedy_actions = next_quantiles.mean(dim=1, keepdim=True).argmax(dim=2, keepdim=True)
# Make "num_tau_prime_samples" copies of actions, and reshape to (batch_size, num_tau_prime_samples, 1)
next_greedy_actions = next_greedy_actions.expand(batch_size, self.num_tau_prime_samples, 1)
# Compute the quantiles of next observation, but with another number of tau samples
next_quantiles = self.quantile_net_target(replay_data.next_observations, self.num_tau_prime_samples)
# Follow greedy policy: use the one with the highest Q values
next_quantiles = next_quantiles.gather(dim=2, index=next_greedy_actions).squeeze(dim=2)
# 1-step TD target
target_quantiles = rewards + (1 - replay_data.dones) * self.gamma * next_quantiles
# Get current quantile estimates
current_quantiles = self.quantile_net(replay_data.observations, self.num_tau_samples)
# Make "num_tau_samples" copies of actions, and reshape to (batch_size, num_tau_samples, 1).
actions = replay_data.actions[..., None].long().expand(batch_size, self.num_tau_samples, 1)
# Retrieve the quantiles for the actions from the replay buffer
current_quantiles = th.gather(current_quantiles, dim=2, index=actions).squeeze(dim=2)
# Compute Quantile Huber loss, summing over a quantile dimension as in the paper.
loss = quantile_huber_loss(current_quantiles, target_quantiles, sum_over_quantiles=True)
return loss
The extra parameters alpha and clip are defaulted to 0.9 and 1.0.
I found immediately that SAIL-IQN performs nicely on sparse rewards so am quite happy with my initial results but by no means has my testing been thorough.
Thanks for your feedback @emrul! This PR is still draft because I can't replicate exactly the results of the paper for Qbert. I don't know if it's a hyperparameter problem or something else, I'm still looking.
I think SIL (and probably maybe SAIL) would fit in SB3-contrib. However, it would be best to discuss it in a dedicated issue. I'll open it right away.
Thanks @qgallouedec - I didn't know there's a reproduction issue, I will look into this also - I compared your implementation with the Dopamine one and the Medipexel/pytorch port of that and it looked quite different. I will dig in to see where they differ and feedback if I find anything to assist.