Ongoing APIv3 Request Thread
-
[x] Return count of missing episodes (collecting), missing episodes (total). Count as in count of episodes and not count of groups.
-
[x] Return count of unreconized files, multiple files and duplicate files.
-
[x] Return breakdown of series by type (Series, OVA, Movie, Others)
Reference image
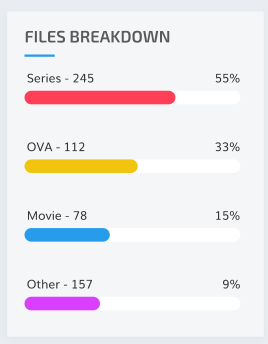
-
[x] Return
epnameandseries namefor recognized files inrecent files. Not very important as we could query/api/ep/getbyfilenamebut that takes a lot of queries. It would be very faster if everything's returned in a single call. -
[x] Return
sizeandnumber of seriesin/api/v3/ImportFolder -
[x] Fix
/api/modulesto return proper counts ofwatched_files,watched_series,hours_watched. Currently, it returns 0 for all three of then. EDIT: Fixed in v3 with a new endpoint -
[x] Fix
/api/file/recentto return datetime values forcreatedandupdatedfields. Currently it only returns date and it should return datetime according to Swagger. -
[x] ~~Make
/api/file/recentreturn only the filename instead of the relative path for keyfilename. Maybe keep the relative path but rename it accordingly.~~ Just use Substring(LastIndexOf(pathSeparator)) in whatever language -
[x] Return src info (BD, HDTV, www, etc) in
/api/ep. Inlevel=3I guess, as it's different for each file. EDIT: Fixed in v3 with new endpoint/api/v3/File/{id}/AniDB -
[x] v3 equivalent of
/api/file/recent -
[x] Fix the endpoint for changing password. The current needs the jmmuserid (#818 )
Need clarification on:
Return count of missing episodes (collecting), missing episodes (total). Count as in count of episodes and not count of groups.
Return count of unreconized files, multiple files and duplicate files.
Just want an endpoint with that data? Is there a place you expected it that doesn't have it.
As for the Import Folder stuff, it was copy and pasted from APIv1, so it's a mess that I need to rewrite from square one
Need clarification on:
Return count of missing episodes (collecting), missing episodes (total). Count as in count of episodes and not count of groups.Return count of unreconized files, multiple files and duplicate files.Just want an endpoint with that data? Is there a place you expected it that doesn't have it.
Just send that data in the dashboard endpoint, that's the only place it's needed.
The number of multiple files was scrapped, because it's confusing at its very concept. I know the system, and coming up with math that made sense wasn't easy. So, I gave Percentage of Multiples/Duplicates: how much of the collection is a multiple or duplicate.
Essentially, because totalling these gives very skewed data, based on the fact that Kaguya has anywhere from 1-3 files per episode, and all of A Dude and His Cat has exactly 2 files/ep.
Screenie
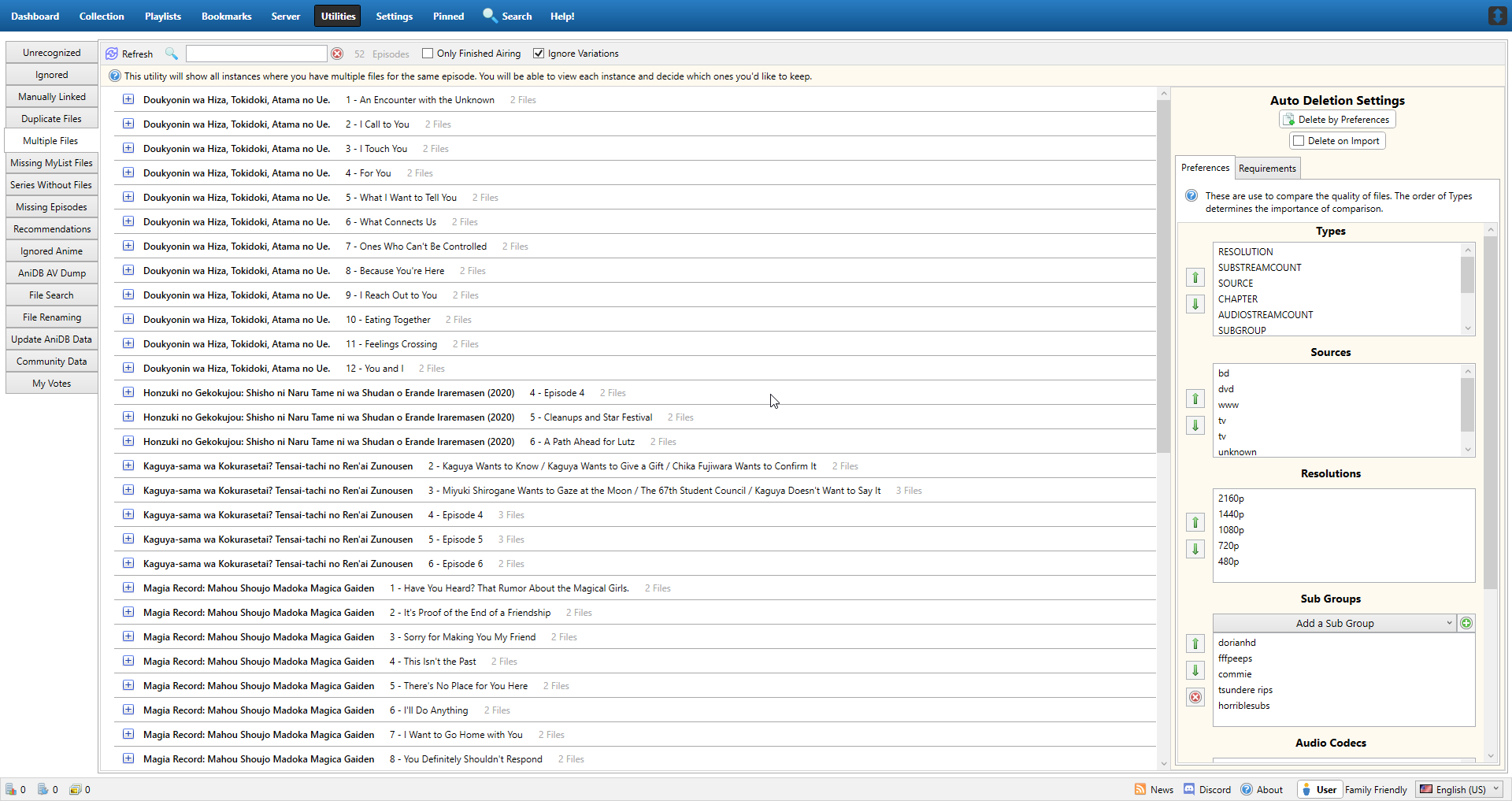
Just a quick one, I think
Make /api/file/recent return only the filename instead of the relative path for key filename. Maybe keep the relative path but rename it accordingly.
Isn't too needed, if you have the path, there are many libraries to extract the filename/basename from it.
Trying to figure out how to have certain properties have one DateTime style and the rest something different.
~~Why didn't I think of that?~~ proving I'm stupid I'm marking that as done. EDIT: Well, what do you know? I did do that. I don't know why I put that there then..
let displayName = filename.split('/');
displayName = displayName[displayName.length - 1];
@da3dsoul Did you complete the 4th one (Return epname and series name)? You marked it as complete but I still don't see it in the endpoint response.
I gave you ID, as names are user configurable and language dependent, plus you could use that to link to the series/episode in ClientV2. Though, in the future you'll want to use APIv3 anyway
Well, fair enough. At least saves me one API request of getting the ID.
For File/Recent, I would have it return the new FileDetailed model, which includes the relevant xrefs. If there are none, then it's unrecognized
The reason I asked that is, currently I have to run a for loop to separate out the recognized and unrecognized files. If I'm not wrong, the server can differentiate them without a loop? So having different endpoints would be better. The loop isn't slow in anyway, just trying to avoid unneeded things. But I can work with it, no problem.
API v3 equivalents needed
- [x]
/version - [ ]
/webui/updateand/webui/latest - [x] All
initendpoints - [x]
/os/drivesand/os/folder - [ ] Queue status and commands related endpoints
- [ ]
/serie/infobyfolder - [x]
/folder/import, ~/folder/scan~ - Scan is pointless, use import (Run Import) or folder/id/scan
Actions:
- [x] ~
/rescanunlinked~ - APIv2 version is replaced by folder/import - [x]
/avdumpmismatchedfiles- * - [x]
/anidb/updatemissingcache- * - [x] ~
/trakt/scan~ - APIv2 version is replaced by folder/import - [x]
/tvdb/regenlinks- * - [x] ~
/tvdb/checklinks~ - This was a test endpoint for making the algorithm. - [x]
/moviedb/update- This may be added to actions anyway as a different kind of endpoint, but the APIv2 version is replaced by folder/import
I'll add if any more come to my mind.
* I can do this, but it should be in a separate menu for power users, alongside several other dangerous commands
Just for your info, Run Import checks for new files, hashes them etc, Scans Drop Folders, Checks and Scans for community site links (tvdb, trakt, moviedb, etc), and Downloads missing images. Also some cleanup stuff, but that's not important to mention
- I can do this, but it should be in a separate menu for power users, alongside several other dangerous commands
Those actions will be hidden until and unless the user specifically goes and enables them to show up on the dashboard. So that's okay.
For ShokoMetadata and future Jellyfin plugin
- [x] ~~
/ep/getbyfilename~~ DO ENOUGH RESEARCH! - [x] ~~
/serie/fromep~~
@Cazzar Can you get the Filesystem endpoints (os/drives and os/folder)? The point of them is to be able to remotely browse for an import folder when adding them, but linux and docker stuff gets in the way there. Feel free to not use CloudFileSystem there. I have tried that and didn't have much luck, but I know you are more familiar with the implications.
Init is done. Note that you need to use the settings controller during init for settings things. init user should have access
- [x] Need an endpoint for getting the list of unrecognized files. The current way I'm doing it is very stupid.
- [x] Add a new property property
NameonShoko.Server.API.v3.Models.Shoko.Episode, where Shoko decides what the preferred name/title of the episode is.
Closing this for now, it's easier to ask/be-asked on discord, and we haven't used this issue in... a while.