Teacher-Student-Network
 Teacher-Student-Network copied to clipboard
Teacher-Student-Network copied to clipboard
PyTorch implementation of Teacher-Student Network(Knowledge Distillation).
Teacher-Student-Network
Pytorch implementation of Teacher-Student Network which idea of model compression by teaching a smaller network, step by step, exactly what to do using a bigger already trained network. While large teacher model have higher knowledge capacity than small student model, this capacity might not be fully utilized. It can be computationally just as expensive to evaluate a model even if it utilizes little of its knowledge capacity. Knowledge distillation transfers knowledge from a large model to a smaller model without loss of validity. Teacher supervising the student's learning helps in achieving a better score metric than it was able to achieve when the student network tried learning in a supervised way.
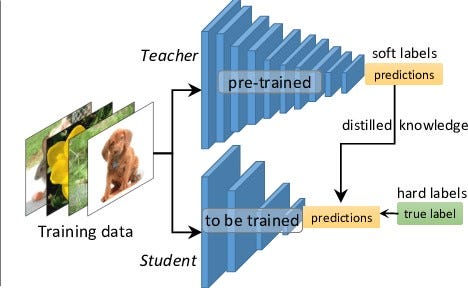
Dataset Information
The Student and teacher were trained on CIFAR100 and CIFAR10 dataset. The dataset contains 50k train images containing 100, 10 classes respectively
Usage
- Install all the libraries required
pip install -r requirements. - Run
python3 train.py. - For inference run
python3 predict.py.
Results
- CIFAR 100
| Method | Accuracy |
|---|---|
| Teacher Model | 54.3% |
| Student Model | 28.3% |
| Teacher-Student Model | 33.1% |
- CIFAR 10
| Method | Accuracy |
|---|---|
| Teacher Model | 87.3% |
| Student Model | 66.4 |
| Teacher-Student Model | 73.1% |
Extra Info
1) Trainin Stratergy : Teacher was trained first, and later used, to supervise the student's training 2) Optimizer : Adam optimizer was used with weight decay. 3) Learning Rate Scheduler : Linear decay scheduler. 4) Teacher Loss : Cross-Entropy Loss. 5) Texcher-Student Loss : Mixture of Cross-Entropy Loss and KL Divergence 5) Regularization : Weight Decay, Dropout, Image Augmentation 6) Performance Metric : Accuracy. 7) Epochs Trained : 100 9) Training Time : 52 minutes.
Metadata
Owner
Metadata
PyTorch implementation of Teacher-Student Network(Knowledge Distillation).