serenity
 serenity copied to clipboard
serenity copied to clipboard
AK+Everywhere: Add and use an exact double parsing method
It is based on https://github.com/fastfloat/fast_float, or the paper at https://arxiv.org/abs/2101.11408
Oh and I just found this explanation: https://nigeltao.github.io/blog/2020/eisel-lemire.html and https://nigeltao.github.io/blog/2020/parse-number-f64-simple.html
There is a number of things I need to figure out to make this as nice and fast as possible:
- [x] Ask the fast_float people about a weird edge case I haven't been able to trigger, asked see https://github.com/fastfloat/fast_float/issues/146
- [x] Add support for floats ~- [ ] Is this even needed?~
- [x] Add faster number parsing
- [x] Optimize until it is fast enough
- [x] Determine all the spots in serenity where this should be used
- [x] Make a nice and easy to use API
- [x] Determine how we generate the tables needed, because I would like to generate them, but it's too slow for constexpr it looks like ~~- [ ] Maybe the entire thing can be constexpr...~~ This would require moving everything to headers so that's for future someone
So if you know about a spot in serenity which does string -> double conversion and is not fixme'd or fixed in this PR leave a comment.
Will fix #14691 once implement in LibJS
Part of the test set It is parsing all the floating points in https://github.com/fastfloat/supplemental_test_files correctly
Checking strtof (it just does strtod and casts to float), I do see got 24 / 5268191 total failures.
And this test set is not made with float in mind so we'll probably want an exact strtof as well to not have annoyingly hard to track down bugs.
The changes should be done, just need to do the final benchmarks and rewrite some commit messages
Benchmark results:
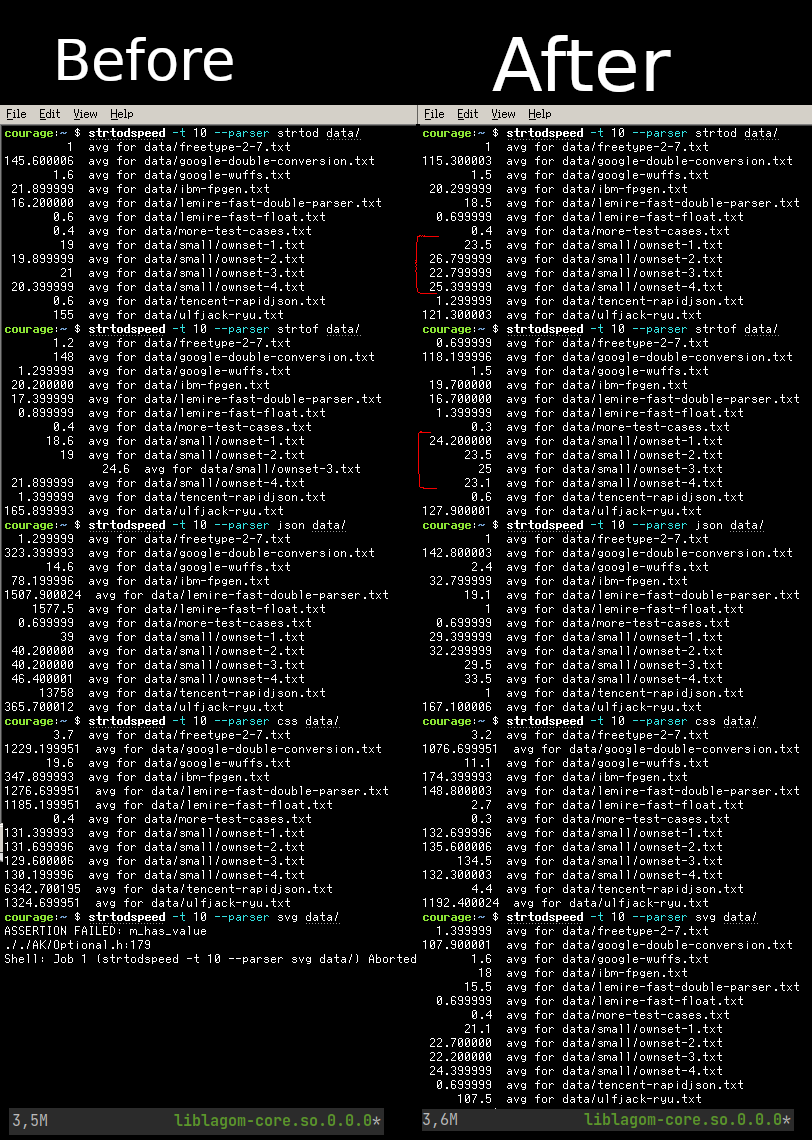
Some remarks: For easy cases (generated with https://gist.github.com/davidot/22eed5fdd526d027ad4d2a4388b0aef4) ~the new parser is not faster in fact it seems a tiny bit slower. (These are marked in red)~ No longer the case see image below https://github.com/SerenityOS/serenity/pull/15377#issuecomment-1287564022
But on the other tests the new method crushes the current implementations, and these also gave wrong results for over 50% of the dataset from https://github.com/fastfloat/supplemental_test_files/tree/main/data And the performance is much more predictable.
The current SVG number parser just crashed for integers outside of int range. So it couldn't even run the benchmarks, but with that fixed it was roughly the same speed as the json one.
The size difference is visible in libcore, the big part is a 651 array with u128, taking 10461 bytes so 10kb. (just noticed the difference is 0.1 mb I shouldn't have used -h)
@AtkinsSJ You might know whether I have used proper whitespace trimming and implementation for the LibWeb new double parser usage
Also if you happen to know more places where we parse doubles/floats in LibWeb/LibJS/Anything else used by the browser let me know. I checked all the strtod, strtof and parsers I could find.
I'm still a bit iffy on replacing individual spec-based implementations with a single one.
I get that, are you more worried about the supported format or the actual conversion to the appropriate value?
I intentionally made the supported format of the new one as wide as possible so it should except whatever you throw at it.
And to make sure we actually get the correct value we would have to have 3+ implementations of something like this algorithm.
Even though I'm sure things like 1.239487e97 are barely used in CSS, giving the incorrect value feels like it could cause very hard to spot problems.
I initially wanted to leave the spec comments with a comment saying this amounts to the same format, but that felt like it would just be a trust me comment.
I'm still a bit iffy on replacing individual spec-based implementations with a single one.
I get that, are you more worried about the supported format or the actual conversion to the appropriate value? I intentionally made the supported format of the new one as wide as possible so it should except whatever you throw at it. And to make sure we actually get the correct value we would have to have 3+ implementations of something like this algorithm. Even though I'm sure things like
1.239487e97are barely used in CSS, giving the incorrect value feels like it could cause very hard to spot problems.I initially wanted to leave the spec comments with a comment saying this amounts to the same format, but that felt like it would just be a trust me comment.
Being too forgiving with formats can be a problem in itself. But, I think we're good here at least for CSS. It always examines the input first to make sure it's a number before consuming one, and treats the float parsing as infallible. So it should be impossible for it to try and convert an invalid-for-css string to a float.
I think it's all fine. I just find specs reassuring! :sweat_smile:
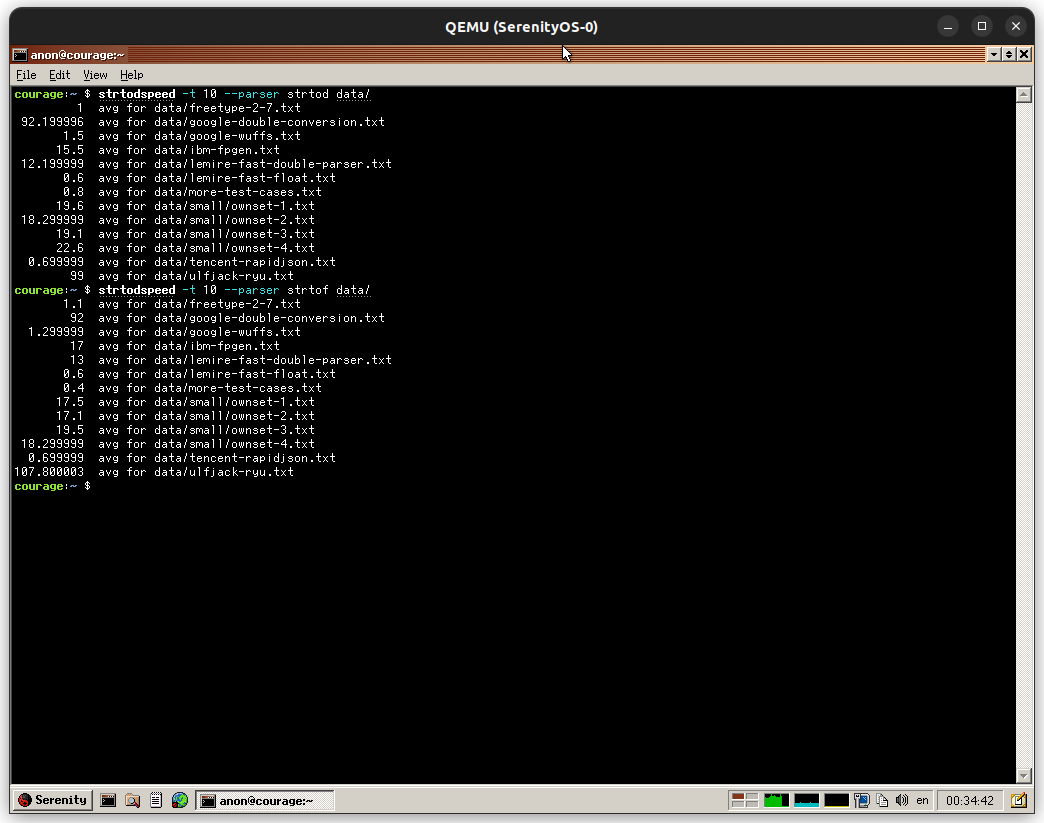
These are the new strtod and strtof performance numbers, so no regression for common cases is visible anymore and the long cases are even faster!
Sorry for the many names :sweat_smile:
I made to_double and to_float on strings non templated, hopefully making it more clear.
And then StringUtils does have a templated version in case you want that.
Also I added a commit which fixes WindowServer crashing on incorrect Mouse acceleration values which meant I couldn't get into serenity when double parsing broke. But this can also be triggered by just editing the WindowServer config