JDBC和DBUtils的架构设计
JDBC(Java Database Connectivity)定义了一套访问和操作数据源(通常是数据库)的接口和抽象,本文将对JDBC的架构进行探讨,然后通过DBUtils学习如何封装一个好用的JDBC框架,阅读完本文后,当你再使用Mybatis等持久层框架时,想必或多或少有种感觉:"它其实是一个认识很久的老朋友"。
JDBC 架构
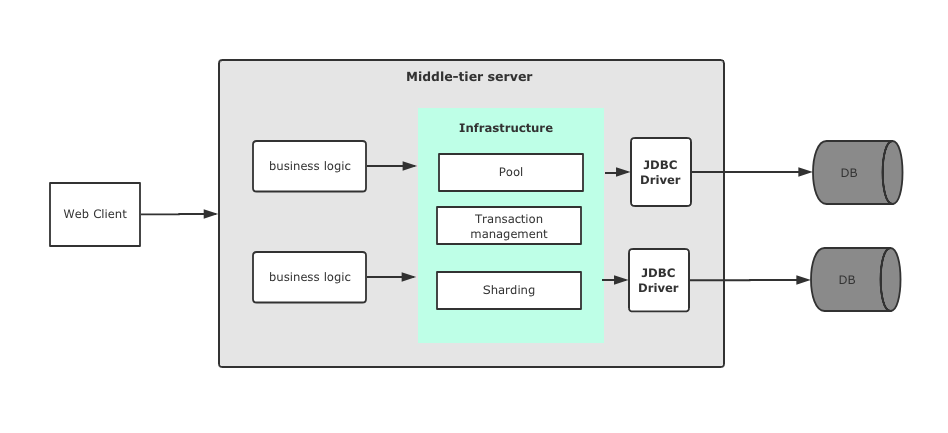
上图是一个典型的JDBC三层模型,在客户端和数据库中间加入中间层,在中间层中将业务逻辑与JDBC驱动分开,通过一个抽象层掩盖不同厂商JDBC驱动的区别,并且提供诸如连接池、事务管理和分库分表等功能,这个模型相对于应用直连数据库驱动增加了更好的扩展性。
JDBC驱动是每个数据库厂商针对JDBC API的实现,我们可以通过一套JDBC API无缝隙切换不同厂商的数据源,这些API在java.sql和javax.sql包下。
经典JDBC代码
我们先来看看经典的通过JDBC连接数据库的代码,类路径下包含最新的mysql jdbc驱动:
compile group: 'mysql', name: 'mysql-connector-java', version: '6.0.6'
app_config是数据库中一张表,拥有name和value两列数据,我们遍历并且打印表中所有数据,具体代码如下:
String url = "jdbc:mysql://127.0.0.1:3306/sayi?useUnicode=true&characterEncoding=UTF-8";
String user = "root";
String password = "sayi123";
@Test
public void testJDBC() {
String sql = "select * from app_config";
// 1.建立连接
// 2.创建Statement
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pst = conn.prepareStatement(sql)) {
// 3.执行
ResultSet rSet = pst.executeQuery();
// 4.处理结果
while (rSet.next()) {
String name = rSet.getString("name");
String value = rSet.getString("value");
System.out.println(name + ":" + value);
}
} catch (SQLException e) {
System.out.println("SQLState:" + e.getSQLState() + ", ErrorCode:" + e.getErrorCode()
+ ", Message:" + e.getMessage());
if (e.getNextException() != null) {
System.out.println(e.getNextException());
}
}
// 5.try-with-resources关闭资源
}
Connection、PreparedStatement、ResultSet都是JDBC API提供的接口,分别代表着连接、语句和结果集的抽象。
DriverManager是用来获取数据库连接的类,不同厂商实现接口Driver定义自己的驱动,然后注册到DriverManager中实现连接的获取。注意,我们无需通过Class.forName("com.mysql.jdbc.Driver");去加载驱动,DriverManager会通过SPI去加载,下文会详解。
JDBC API概览:java.sql和javax.sql
JDBC API的标准功能在java.sql下,javax.sql提供了可选API。
 java.sql下提供了Connection将数据库连接进行了抽象,同时提供Statement、PreparedStatement和CallStatement表示执行语句、带参数的执行语句和存储过程的抽象,通过executeQuery方法执行语句,通过结果集ResultSet提供的getXXX方法获取响应的数据。
java.sql下提供了Connection将数据库连接进行了抽象,同时提供Statement、PreparedStatement和CallStatement表示执行语句、带参数的执行语句和存储过程的抽象,通过executeQuery方法执行语句,通过结果集ResultSet提供的getXXX方法获取响应的数据。

javax.sql提供了获取连接推荐的方式:DataSource,提供了抽象的数据库连接池ConnectionPoolDataSource和可复用的数据库连接PoolConnection,很多专注于数据库连接池性能的组件(DBCP、Druid等)都是对这一层抽象API进行实现。
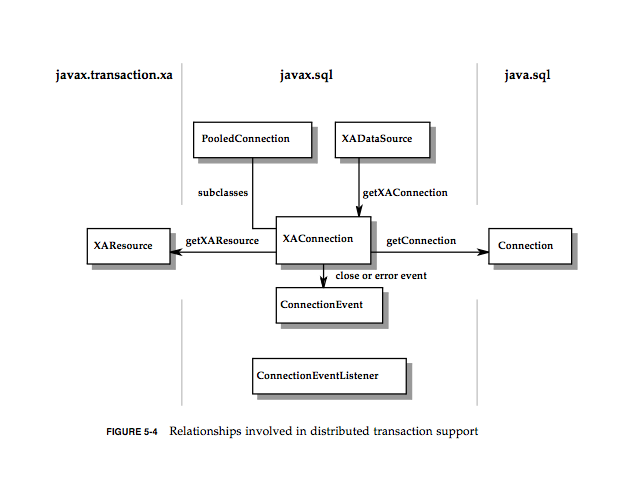
XA(eXtended Architecture)是针对分布式事务的标准,javax.sql下提供了一些XA开头命名的抽象接口。
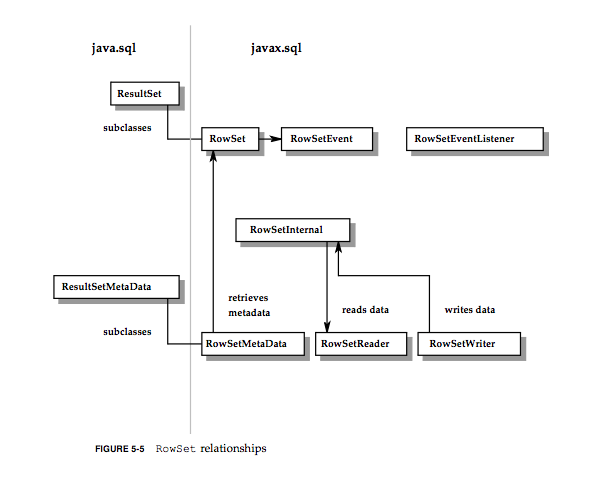
针对ResultSet接口,提供了RowSet接口。
DriverManager
我们已经知道建立连接的方式有两种:DriverManager和DataSource,我们先来看看DriverManager,每个厂商需要编写自己的数据库驱动实现接口java.sql.Driver,通过这个Driver获取连接,我们来看看mysql驱动类com.mysql.cj.jdbc.Driver:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
java.sql.DriverManager.registerDriver(new Driver());
} catch (SQLException E) {
throw new RuntimeException("Can't register driver!");
}
}
public Driver() throws SQLException {
// Required for Class.forName().newInstance()
}
}
典型的驱动实现方式是有个静态代码块,通过java.sql.DriverManager.registerDriver注册驱动,为了注册驱动必须使静态代码块能够执行,所以过去的版本采用了Class.forName的方式使驱动类进行初始化操作。
最新版本Driver驱动类初始化的触发操作是通过SPI机制实现,在mysql驱动jar下有个META-INF/services/java.sql.Driver文件,内容为具体驱动类:
com.mysql.cj.jdbc.Driver
接下来就可以通过在DriverManager类中通过ServiceLoader进行驱动类的加载和初始化了,我们看下DriverManager的源码:
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
类的静态代码块会调用加载驱动类的方法:
private static void loadInitialDrivers() {
// 从系统属性jdbc.drivers中获取驱动类
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// SPI方式获取驱动类
// If the driver is packaged as a Service Provider, load it.
// Get all the drivers through the classloader
// exposed as a java.sql.Driver.class service.
// ServiceLoader.load() replaces the sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
// 初始化SPI方式加载的驱动类
/* Load these drivers, so that they can be instantiated.
*/
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
// 初始化系统属性方式加载的驱动类
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
从代码中可以看出,通过SPI方式加载驱动类并且初始化,同时也可以通过jdbc.drivers系统属性加载并初始化驱动类。
DataSource
通过数据源获取连接官方推荐的方式,DataSource具体的实现是由每个厂商或者第三方框架定义的,通常我们会使用池化技术使连接对象池化。
使用数据源最大的好处是我们切换数据源就可以改变数据库的连接,这样对应用是透明的,比如我们可以通过JNDI定义数据源。
通过Mysql数据源获取连接的代码如下,我们还可以使用第三方数据库连接池框架:
com.mysql.cj.jdbc.MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl(url);
dataSource.setUser(user);
dataSource.setPassword(password);
Connection conn = dataSource.getConnection();
SQLException
当操作数据库发生异常时,就会抛出SQLException,这个异常包含了一些信息:
- getMessage方法获取异常描述
- getSQLState方法获取SQLState
- getErrorCode方法获取一个厂商提供的整型错误码
- getNextException获取异常链
我们可以继承SQLException定义更贴切的异常,比如当可以把sql和参数也放到描述中。
DBUtils:封装更简单易用的JDBC
如果我们每次数据库操作都要这么多步骤,那会是多么令人厌烦的事情啊,所以我们要针对JDBC API进行封装,把这些步骤模板化,模板以外我们只需要关心以下几点:
- 定义数据源
- sql参数
- 获得想要的结果,可能是一个数组、Map或者是一个JavaBean
DBUtils就是这样的一个封装,它让JDBC操作更简单,它的核心门面是QueryRunner,我们先来看看一个示例代码,获取app_config表所有的配置,生成的结果集为List<Object[]>:
@Test
public void testBasic() throws SQLException {
QueryRunner run = new QueryRunner(dataSource);
List<Object[]> query = run.query("select * from app_config",
new ResultSetHandler<List<Object[]>>() {
@Override
public List<Object[]> handle(ResultSet rs) throws SQLException {
List<Object[]> ret = new ArrayList<>();
while (rs.next()) {
ResultSetMetaData metaData = rs.getMetaData();
Object[] objs = new Object[metaData.getColumnCount()];
for (int i = 0; i < objs.length; i++) {
objs[i] = rs.getObject(i + 1);
}
ret.add(objs);
}
return ret;
}
});
query.stream().forEachOrdered(t -> System.out.println(Arrays.toString(t)));
}
QueryRunner

我们通过datasource构建一个QueryRunner对象,然后通过QueryRunner提供的方式执SQL。如图,它将具体的JDBC操作封装到每个具体方法里,我们只要传入sql和对应的参数即可。
由于我们处理数据库返回结果集的策略可能不一样,所以提供了一类型为ResultSetHandler接口的参数来自定义策略的实现,我们来看看query查询的源码:
private <T> T query(final Connection conn, final boolean closeConn, final String sql, final ResultSetHandler<T> rsh, final Object... params)
throws SQLException {
if (conn == null) {
throw new SQLException("Null connection");
}
if (sql == null) {
if (closeConn) {
close(conn);
}
throw new SQLException("Null SQL statement");
}
if (rsh == null) {
if (closeConn) {
close(conn);
}
throw new SQLException("Null ResultSetHandler");
}
PreparedStatement stmt = null;
ResultSet rs = null;
T result = null;
try {
stmt = this.prepareStatement(conn, sql);
this.fillStatement(stmt, params);
rs = this.wrap(stmt.executeQuery());
// 结果集处理策略
result = rsh.handle(rs);
} catch (final SQLException e) {
// 包装SQLException异常,增加sql和参数信息
this.rethrow(e, sql, params);
} finally {
closeQuietly(rs);
closeQuietly(stmt);
if (closeConn) {
close(conn);
}
}
return result;
}
ResultSetHandler的扩展
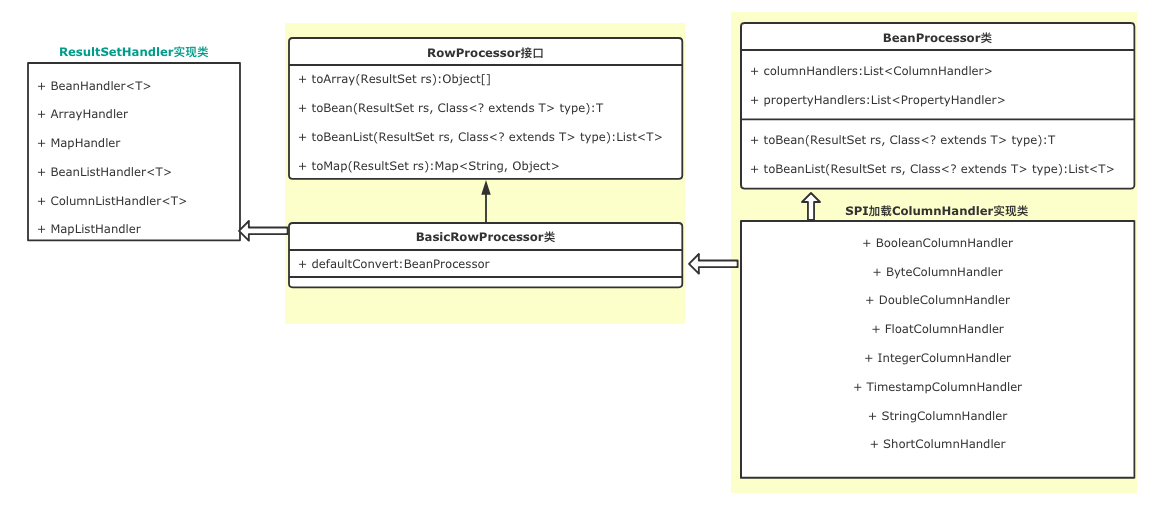
开放扩展的核心逻辑就是自定义ResultSetHandler,对于一些通用类型的返回,DBUtils提供了默认的ResultSetHandler,如上图,ArrayHandler可以将结果转化为数组、MapHandler将结果集转化为Map、BeanHandler<T>将结果集转化为JavaBean,那么这些实现类又是如何抽象的呢?
所有结果集的策略实现无非就是将数据库中的一行数据映射到某种数据类型,所以提供了RowProcessor接口抽象这些功能,比如toArray、toBean等,它的默认实现是BasicRowProcessor。
由于结果集转化为JavaBean涉及到Java数据类型和JDBC数据类型的匹配映射,所以BasicRowProcessor的toBean方法默认使用BeanProcessor来处理,BeanProcessor处理数据库列与JavaBean属性的映射关系,以及通过ColumnHandler处值类型转化,注意的是,ColumnHandler采用SPI方式加载,所以我们可以扩展自己的数据库列数据到某种Java数据类型的转化,如枚举。 我们可以自定义BeanProcessor来处理数据库行到Bean的映射。
RowProcessor的实现
我们主要通过BasicRowProcessor源码看toArray和toMap方法的实现:
public Object[] toArray(final ResultSet rs) throws SQLException {
final ResultSetMetaData meta = rs.getMetaData();
final int cols = meta.getColumnCount();
final Object[] result = new Object[cols];
for (int i = 0; i < cols; i++) {
result[i] = rs.getObject(i + 1);
}
return result;
}
public Map<String, Object> toMap(final ResultSet rs) throws SQLException {
final ResultSetMetaData rsmd = rs.getMetaData();
final int cols = rsmd.getColumnCount();
final Map<String, Object> result = createCaseInsensitiveHashMap(cols);
for (int i = 1; i <= cols; i++) {
String columnName = rsmd.getColumnLabel(i);
if (null == columnName || 0 == columnName.length()) {
columnName = rsmd.getColumnName(i);
}
result.put(columnName, rs.getObject(i));
}
return result;
}
BeanProcessor的扩展:列和字段的映射关系
BeanProcessor有个子类GenerousBeanProcessor,重写了mapColumnsToProperties方法,支持将下划线间隔命名的数据库列名映射为JavaBean某个驼峰风格的字段。
我们可以自己实现这个方法来决定这种映射关系。
ColumnHandler的扩展:JDBC数据类型和Java数据类型的转化
比如数据库某列存储的是一些整型值,我们的JavaBean这个字段是一个枚举,那么我们就需要定自己的列处理方法了。
首先我们写一个列处理类:
package com.deepoove.database.column;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.commons.dbutils.ColumnHandler;
import com.deepoove.database.TypeEnum;
public class TypeEnumColumnHandler implements ColumnHandler {
@Override
public boolean match(Class<?> propType) {
// JavaBean字段的类型为枚举
return TypeEnum.class.equals(propType);
}
@Override
public Object apply(ResultSet rs, int columnIndex) throws SQLException {
// 将列的值转化为枚举
int type = rs.getInt(columnIndex);
if (type == 0) return TypeEnum.CLIENT;
return TypeEnum.SERVER;
}
}
然后通过SPI的方式进行加载,在MET-INF/services/org.apache.commons.dbutils.ColumnHandler文件中加如这个扩展:
com.deepoove.database.column.TypeEnumColumnHandler
一切OK,它能正确生成结果Bean。
参考资料
《JDBC 4.3 Specification》
总结
JDBC是一个高度抽象的设计,完美的体现了面向接口编程,数据库连接池是一个非常热门的技术方向,可以将连接池化从而复用连接可以做到监控,同时也可以在JDBC层作一些封装进而可以进行分库分表,Sharding-JDBC正是对JDBC的增强。
DBUtils是一个极简的封装,但是它的许多理念在一些更重的框架里面都能看到影子,比如值类型处理,列与字段映射等。QueryLoader提供了从配置文件加载SQL的功能,这又有点类似Mybatis的Mapper.xm加SQL。