DDDER 前端架构演变
从2017 年4 月份到现在,入职DDDER 前端团队快要一年半了。感谢团队对我的信任,给予我在前端开发中极大的自由度。这一年半以来,我思考了很多问题,构想着自己理想中的项目架构分层,也想着数据流应该怎样实践、缓存策略应该怎样设计、如何增强开发中的强类型引导等等。
随着项目的几次大版本开发(对,还没正式上线就经历了三次大版本开发),慢慢的,DDDER 的前端架构已经进化到一个我比较满意的状态了(是进化还是黑暗进化,可能真不好说)。在这个过程中,我参考并引入了很多业界的优秀的工具和解决方案,写了很多轮子,同时也弃用了很多轮子。
在此,我很感谢乐于开源,乐于分享想法思路、经验总结的各位同行,超级感谢!
我之前也对入职DDDER 前端团队的前一年时间做过工作总结,里面写了一些被我使用过或参考过的工具和思路,有兴趣的可以点个Star 哈:近一年的工作技术总结。
但在今年4 月份到现在的这次大改版中,我遇到了一些很不一样的架构思路,进而导致DDDER 的前端架构发生了比较大的调整,也就是进化到我现在比较中意的一个状态。所以,很有必要对团队的前端架构演变做一个回顾,也算是对自己工作的一个总结吧。
画了个架构演变的过程图,仅供回忆,哈哈:
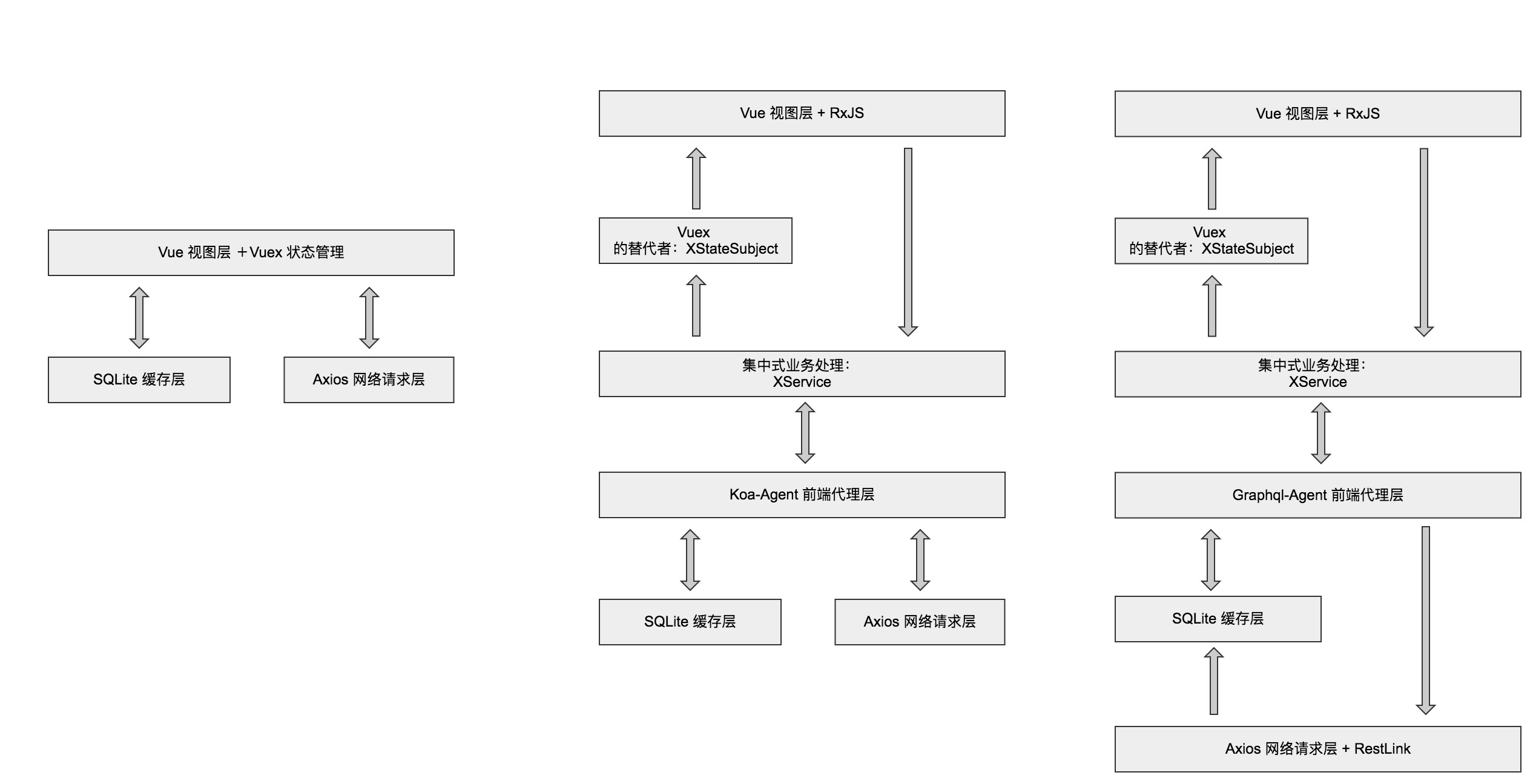
本文很大篇幅都会在"阶段三" 中哦~~
废话一大堆,终于说完了哈~~~
在近一年的工作技术总结 文章中提到过,由于DDDER 客户端的底层比较特殊,我选择了二次开发Vue 并将其作为视图层工具,二开的Vue 仓库地址参考:@ddder/vue。既然选择了Vue,项目的架构自然要往Vue 偏移的。
阶段一:可能是常规的Vue 技术栈
Vue + Vuex + Axios,这可能是业界技术文章中说得最多的Vue 技术栈,尤其是Vue + Vuex,一套本来是挺好用的视图层加应用状态管理组合。DDDER 前端架构一开始便使用了这个技术栈。
这个阶段我没有很多地参与到业务开发中,更多地是在写各种轮子来支撑,后期在Review 组员的业务代码时,发现对Vuex 存在一些很奇怪的用法。当时架构中有一层很薄的service 层供视图层调用,里面写的全是对接后台请求和读写sqlite 的api,比如:
// AccountService.js
/*------- Helpers -------*/
function bindVuexStore(obj, store) {
if (Array.isArray(obj)) {
let tmp = {};
obj.forEach(ele => _.merge(tmp, ele));
obj = tmp;
}
for (let key in obj) {
obj[key] = obj[key].bind({$store: store});
}
return obj;
}
/*------- Weird -------*/
let actions = vuex.mapActions('account', {
setUserInfo: 'setUserInfo',
updateUserName: 'updateUserName',
});
/*------- Weird -------*/
let getters = vuex.mapState('account', {
getUserInfo: 'getUserInfo'
});
/*------- Weird -------*/
let accountStore = bindVuexStore([getters, actions], global.store);
exports.login = function login(phone, password) {
return co(function*() {
// 发送登录请求给服务器,期待返回userInfo
let response = yield axios.post({
url: '/login',
data: {
phone,
password
}
});
if (response.code === 'S_OK') {
// 将userInfo 保存到user_info 表的伪代码
yield sqlite.save('user_info', response.userInfo);
/*------- Weird -------*/
accountStore.setUserInfo(response.userInfo);
}
return response;
})
}
exports.updateAccountName = function updateAccountName(userName) {
return co(function*() {
/*------- Weird -------*/
let userInfo = accountStore.getUserInfo();
// 发送登录请求给服务器,期待返回userInfo
let response = yield axios.post({
url: '/updateUserName',
data: {
userId: userInfo.userId,
userName
}
});
if (response.code === 'S_OK') {
/*------- Weird -------*/
accountStore.updateUserName(useName);
// 将userInfo 保存到user_info 表的伪代码
yield sqlite.save('user_info', {userName: userName});
}
return response;
})
}
上面有几个很奇怪的用法:
- 在service 层单独把
mutation和getter拿了出来,然后写了个bindVuexStore的方法绑定一个全局的Vuex Store,然后存到了一个accountStore的变量中; - 在
login接口的回调中,调用了accountStore.setUserInfo(response.userInfo);,把登录成功的用户信息写到Vuex Store 中; - 在
updateAccountName接口的一开始,调用了let userInfo = accountStore.getUserInfo();,将之前登录成功的用户信息从Vuex Store 中读取出来; - 在
updateAccountName接口的一开始,调用了accountStore.updateUserName(useName);,修改存于Vuex Store 中的用户名;
看到这四个用法,当时最强的感受是,Vuex 的数据和方法非常不适合在Vue 或Vuex 外部调用。另外,在Review 代码时非常不适应基于字符串来访问Vuex getter 或mutation 的用法,主要是WebStorm 没法索引到这些字符串指向的方法。
阶段二:Vue 与响应式编程
由于项目产品涉及到跨端使用,所以要求前端自行维护多端的代码。考虑到产品设计虽然是跨端的,但对项目本身来说,很多逻辑都是可以共用的,比如sqlite 数据库缓存的设计、web api 对接逻辑等等。于是我在项目中抽离了一层服务层来统一处理缓存和api 对接,我简单称为agent层。
agent层很大程度借鉴了koa的设计,提供相似的中间件机制,每个独立的访问均使用独立的context 来管理。只是agent层中api 注册的方式非常原始,将cmd 以key-value 方式注册即可,调用方式也很原始,agent提供唯一的方法,只需要提供对应cmd 路径以及参数即可调用,返回Promise。
agent层的源码以及demo 均放在Github 上:SamHwang1990/agent。
除了agent层的调整,视图层也发生了挺大的变化。项目脱离了Vuex,转而投入了RxJS 的怀抱中,整个Vue 视图层技术栈改为:Vue+RxJS+vue-rx。
上面的技术栈一开始移植到项目中时,可以说怎样都用得不顺手,主要体现在对数据流得修改上。当时,由于大部分数据都是以BehaviorSubject实例存在,若要修改数据流的数据,需要使用BehaviorSubject.prototype.getValue()拿到数据流当前值,然后再调用BehaviorSubject.prototype.next()来修改数据流。这种用法很繁琐,而且我自己认为过多的依赖getValue()方法其实非常不符合RxJS 的设计思想。
想了想,发现angular有很棒的思路参考:ngrx/platform 中的store ,里面有个很关键的概念,XStateSubject,一种继承于Observable.BehaviorSubject,提供类似于Vuex mutation 的方式来修改数据的对象,直接拿过来用。XStateSubject 的源码以及demo 均放在Github 上:SamHwang1990/xservice。
总结一下,相较于阶段一,阶段二最大的变化是增加了agent层,弃用Vuex,引入RxJS。产品PC 端第一版就基于阶段二的架构进行开发。整个版本开发下来,阶段二的架构中,最大的问题在agent层:
- 参考CTPersistance 开发的sqlite 缓存层工具库SamHwang1990/sqlite-persistence 用起来非常不顺手;
- 参考RTNetworking 开发的web api 层工具库SamHwang1990/http-networking 用起来非常不顺手;
-
agent中对接视图层的cmd不支持参数以及参数类型说明; -
agent中注册cmd的方式不够酷;
阶段三:Graphql-agent
考虑到上述agent 层的一些缺点,阶段三中,我引进了新的完全基于typescript 和graphql 的graphql-agent来处理sqlite 缓存以及web api 对接逻辑。具体来说,做了以下几件事情:
- 引入type-graphql 以及graphql-subscriptions 来作为ddder 客户端
graphql server模块; - 引入并二开了typeorm 来提供ddder 平台的sqlite 数据库orm;
- 引入apollo 相关配套来作为ddder 客户端的
graphql client模块; - 引入typedi 来提供依赖注入;
下面对上述的几件事情做更详细的解释,怕自己忘记思路哈。
Typescript 与Decorators
为配合type-graphql和typeorm,需要为项目开启typescript 的decorators 功能,开启步骤:
-
tsconfig.json中的compilerOptions新增两个配置:"emitDecoratorMetadata": true、"experimentalDecorators": true; - 安装
reflect-metadata:npm i reflect-metadata --save,并在触发decorator 函数前找个地方引用该库:import "reflect-metadata";
貌似ECMAScript 已经有了关于Decorators 的草案,但具体的细节还没认真看过,先记录一些使用体会:
- Decorator 本质上就是高阶函数;
- 目前使用到三种Decorator,一种用于修饰对象,一种用于修饰对象属性,一种用于修饰函数参数;
- 不同类型的Decorator 高阶函数会接受不同的参数,比如所修饰的对象,所修饰的对象属性说明(比如属性名),所修饰的函数参数说明;
举个例子,项目中为了让使用依赖注入的类能正确拿到TypeORM 的EntityManager,参考typeorm-typedi-extensions 写了一个Decorator:
import {ConnectionManager} from "typeorm";
import {Container} from "typedi";
/**
* Allows to inject an EntityManager using typedi's Container.
*/
export function GetterManager(connectionName: string = "default"): Function {
return function GetterManagerDecorator(object: Object|Function, propertyName: string, index?: number) {
Object.defineProperty(object, propertyName, {
get() {
const connectionManager = Container.get(ConnectionManager);
if (!connectionManager.has(connectionName))
throw new Error(`Cannot get connection "${connectionName}" from the connection manager. ` +
`Make sure you have created such connection. Also make sure you have called useContainer(Container) ` +
`in your application before you established a connection and importing any entity.`);
const connection = connectionManager.get(connectionName);
const entityManager = connection.manager;
if (!entityManager)
throw new Error(`Entity manager was not found on "${connectionName}" connection. ` +
`Make sure you correctly setup connection and container usage.`);
return entityManager;
}
});
};
}
使用例子:
import { Service } from 'typedi';
import { EntityManager } from "typeorm";
import { GetterManager } from './managerDecorator';
class Foo {
@GetterManager()
manager: EntityManager;
async doSomethingWithEntityManager() {
console.log(this.manager.connection.name);
}
}
类Foo 使用GetterManager来修饰了属性manager,最终,在类Foo 的方法doSomethingWithEntityManager中顺利通过this.manager 拿到了EntityManager 的实例。
奥妙就在GetterManager 函数中返回的函数GetterManagerDecorator。该函数接收两个参数:object、propertyName。函数在真正被调用到时,第一个实参为类Foo 的原型对象,即:(function Foo(){}).prototype,第二个实参则为所修饰的属性名:manager,于是,配合依赖注入的容易,GetterManagerDecorator 在类Foo 的原型上增加了一个名为manager 的getter 属性,动态从TypeORM 的注入容器中把EntityManager 给取出来。
依赖注入
在整个typestack 体系中,依赖注入扮演着非常重要的角色。而依赖注入的容器提供、相关的依赖分析、对象实例化以及属性、参数的注入全部使用typedi 来完成。
以我对typedi 的简单理解,说下typedi 是如何完成上述的功能的:
- 提供Container 来管理需要依赖注入的类,及其实例化单例对象;
- 使用
Container.get(className)获取容器中指定类的实例化对象; - 使用
Container.set(className, classInstance)往容器中设置指定类的实例化对象; - 使用@Service() 修饰器可往容器中声明需要依赖注入的类;
- 使用@Inject() 修饰器可往容器中声明某个类需要属性注入或参数注入等等;
大部分时候,其实我们都不需要自行调用Container.get(...)或Container.set(...),而是借由启动容器中某个类的实例化,typedi 会帮我们将所有依赖的注入类自动创建好的。
当然,typedi 提供的api 远不止这些,但我没真正用到,就不提了,详细可阅读README。
之所以为GraphqlAgent 层引入依赖注入,主要是因为typeorm 和type-graphql 这两个核心的库都依赖着这个功能:
- typeorm 中需要一个容易来管理数据库连接的Connection、EntityManager 等对象;
- type-graphql 中构建schema 时需要传一个resolver 数组,这些resolver 元素都是能处理graphql 请求的类,而这些类的实例化也是需要一个容器来管理的;
- 为了能打通typeorm 以及type-graphql 中的注入单例对象,我需要共用一个Container,于是引入typedi 并将其Container 作为typeorm 和type-graphql 的公用容器;
上述的第三点其实也符合typestack 的用法,同时在应用中,我为了更好地控制graphql 的消息推送而使用了独立的PubSub 实例对象,原因后面会提及。代码如下:
import {useContainer as useTypeGraphqlContainer} from 'type-graphql';
import {useContainer as useTypeORMContainer} from 'typeorm';
import { PubSub } from 'graphql-subscriptions';
import {Container} from 'typedi';
useTypeGraphqlContainer(Container);
useTypeORMContainer(Container);
// use for achieving graphql-agent subscription
export const pubSub = new PubSub();
Container.set(PubSub, pubSub);
虽然typedi 的引入有点被迫的性质,但配合上面两个库使用下来,几乎把所有实例化类的工作都省去了,我可以把所有处理请求的逻辑按模块放到类的实例方法中,而不用像之前agent 层那样只能作为js 模块的顶层函数存在。同时,以类的实例成员存在,自然各处理逻辑也能共用类实例属性,这真的很爽,很自然。举个例子:
假设我们需要两个接口来分别读取用户信息缓存以及邮件信息缓存,若仅仅作为js 模块的顶层函数来写,可能是这样的:
// module.js
const userMapCache = {};
const mailMapCache = {};
export.getUserInfo = function getUserInfoFromCache(userId) {
return userMapCache[userId];
}
export.getMailInfo = function getMailInfoFromCache(mId) {
return mailMapCache[mId];
}
//------------- 调用: entry.js ------------
import { getUserInfo, getMailInfo } from './module';
console.log(getUserInfo(123));
console.log(getMailInfo(456));
上面麻烦的地方在于module.js,若模块多几个局部变量或私有函数,里面代码顺序反正我怎样看都会很不爽。相反,使用类来管理这些api,我们的代码可以写成:
// module.ts
import { Service } from 'typedi';
@Service()
export class UserService {
private readonly cache: Record<string, any> = {};
public getUserInfo(userId: string) {
return this.cache[userId];
}
}
@Service()
export class MailService {
private readonly cache: Record<string, any> = {};
public getMailInfo(mId: string) {
return this.cache[mId];
}
}
//------------- 调用: entry.ts ------------
import { UserService, MailService } from './module';
import { Service, Inject } from 'typedi';
@Service()
export default class EntryResolver {
@Inject()
private userService: UserService;
@Inject()
private mailService: MailService;
public getUserInfoAndMailInfo(userId, mId) {
return {
userInfo: this.userService.getUserInfo(userId),
mailInfo: this.mailService.getMailInfo(mId),
}
}
}
上述代码中,用户信息的缓存放到UserService 类中的cache 只读私有属性,邮件列表缓存放到MailService 类中的cache 只读私有属性,后面无论加多少属性或方法,我们都有很好的编写规范和管理方式。
然后,EntryResolver 假设是由type-graphql 作为resolver 来启动,那EntryResolver 中的userService 和mailService 私有实例的创建都不用我们自己做,只需用Inject 修饰器声明好依赖注入即可。
近乎理想的TypeORM
在数据库orm 工具上,我选择了typeorm,主要是因为它满足了我对orm 的几个features 需求:
- 支持使用类来定义Model 和实例化Model,在typeorm 中叫
Entity,配合typescript,意味着会有比较理想的数据类型指引,另外,配合typescript 的decorator 能很方便地定义字段名、类型、序列化和反序列化的逻辑; - 有成熟的数据库migration 支持;
- 查询语句构建依赖方法链(类似Querydsl)而不是一个巨复杂的配置选项(比如sequelizejs);
- 查询语句的结果最好就是Model 的实例和实例列表,而不是Plain Object;
- orm 代码越简单越好,我估计是要二开的(二开的分支:@ddder/typeorm,溜了溜了);
目前用下来感觉也相当良好,除了一点,就是当出现错误时所给到的提示几乎不能帮助定位问题。比如当代码中的字段名与数据库中字段名不一致,或者字段类型不一致时,没有预警,而是只等代码执行出错,把错误抛出而已,这点差评!
另外,上面提到的二开了typeorm,其实只是参考现有的sqlite driver 增加了项目自己的driver 而已。
Web API 封装:Rest-Link
graphql-agent 中除了对接视图层、本地sqlite 缓存,还要对接和封装Web API 调用。项目中,我们使用的是axios 来创建XHR 请求以及处理返回结果,axios 本身的使用也非常简单。举个例子,假设有两个api 分别用来获取用户信息和好友信息,我们可以这样写:
import axios = require('axios');
// 获取用户信息
let userInfo = await axios({
baseURL: 'https://some-domain.com/api/',
method: 'get',
url: '/account/info',
});
// 获取好友信息
let friendInfo = await axios({
baseURL: 'https://some-domain.com/api/',
method: 'get',
url: '/user/info',
params: {
userId: 'friendId',
},
});
如果项目中分别有N 个地方需要获取用户信息和不同的好友信息,我们就需要将上面的直接调用改为函数封装了:
import axios = require('axios');
async function getAccountInfo() {
return await axios({
baseURL: 'https://some-domain.com/api/',
method: 'get',
url: '/account/info',
});
}
async function getFriendInfo(friendId) {
return await axios({
baseURL: 'https://some-domain.com/api/',
method: 'get',
url: '/user/info',
params: {
userId: friendId,
},
});
}
好了,上面的封装足够让我们满意了吗?很明显,没有。仔细看下有很多代码都是值得斟酌的:
-
baseURL的值出现了N 次的重复,意味着每次调整baseURL 的值都会牵扯多处的代码; - 传入axios 的配置格式重复了N 次,万一需要axios 的配置出现不兼容的修改,或者项目出于其他考虑要替换axios 为其他库,那就要调整很多地方咯;
- 每个api 函数如何加入统一的错误处理逻辑?
- 每个api 函数可否只需要声明url,其他配置都帮我自动生成?
上面说的几点,到底无非就是将调用axios 的细节给透明化,不能直接暴露给调用者。
之前曾经写过一个工具库去做封装:HttpNetworking,当时写的时候越写越懵,用起来更加是繁琐,而且配置很容易混淆,记忆成本太高,于是琢磨着写一个新的封装工具。刚好在研究apollo 时看到了apollo-link,看了一下文档,虽然apollo-link 本身是用来处理graqhql 请求的,不过,确认过眼神,这就是我要的web api 封装工具。于是参考其实现,写了一个rest-link(待上传代码)来对接各个微服务web api。举个例子,同样写获取用户信息和好友信息的两个接口:
import {
createExecutor,
createHttpLink,
RestLink,
Operation,
FetchResult,
NextLink,
} from 'rest-link';
// 1. 创建对接ddder web host 服务的Link
const ddderHostLink = RestLink.from([
new RestLink((operation: Operation, forward: NextLink) => {
return forward(operation)
.pipe(catchError(error => of({error: error})))
.map((result: FetchResult) => {
let {data: ddderResponse, code: status, error} = result;
// 统一的错误处理
if (error) {
}
return result;
})
}),
createHttpLink({
baseURL: 'https://some-domain.com/api/',
})
]);
// 2. url helper link 工厂函数
function createUrlConfigLink(apiPath: string, method?: string = 'get'): RestLink {
apiPath = apiPath.replace(/\./g, '/');
return new RestLink((operation: Operation, forward: NextLink) => {
if (operation.url == null) {
operation.url = apiPath;
}
if (operation.method === null) {
operation.method = method;
}
return forward(operation);
})
}
// 3. 对接获取用户信息的api
const getAccountInfo = createExecutor(
createUrlConfigLink('/account/info'),
ddderHostLink,
)
// 4. 对接获取好友信息的api
const getFriendInfo = createExecutor(
createUrlConfigLink('/user/info'),
ddderHostLink,
)
// ============ 实际调用 ============
let accountInfo = await getAccountInfo();
let friendInfo = await getFriendInfo({
params: {
friendId: 123
}
});
咋看下去,貌似比一开始多了一些代码,但随着你的api 数量增加、api 调用的地方越来越多,rest-link 所能提供的高度封装和可维护性,能帮你的项目不致于会因为web api 对接而失控。
在rest-link 中,贯穿始终的有两点:
- link 使用RxJS/Observable 来提供洋葱式中间件的概念;
- link 中间件中传递的operation 结构以及api 调用时使用的options 均以axios 的request config 为参考;
客户端实现全栈Graphql
在GrahpqlAgent 中,最核心的莫过于在graphql 方面的实践。先谈下我对graphql 的理解:
-
graphql后端需要定义支持解析的schema,前端调用者须按照所定义schema 子集来执行查询; - schema 中包含三种特殊的子类型:
query(类似于http 中的get 语义)、mutation(类似http 中的post 语义)、subscriptions(类似于subscribe 或watch 的语义); - 除了graphql 默认支持的几种标量类型,还支持使用
interface、enum、type来自定义复合类型; - graphql 中的强类型对前后端都有很强的约束。对于后端来说,接口的返回必须遵循所定义的schema 返回类型,否则去到前端的response 就只有error;对于前端来说,发起请求时所声明的查询、传输的参数类型、预期的返回体结构也必须按照schema 所定义来编写,否则请求还没去到后端的逻辑层就被graphql 拦截下来直接返回错误;
- graphql 请求对于前端来说,属于发起一种声明即所得的请求调用,实际使用中,因为要主动声明返回体结构,查询参数等等,代码上虽然会清晰,但总会觉得冗余和繁琐,有得有失吧;
- graphql 查询的返回体都有统一的结构:
{ data?: any, code?: string, error?: Error };
讲道理,之所以选用graphql 来作为客户端中,视图层与agent 层的通讯协议,其实最看重的只是强制类型支持。而类似query、mutation 的特性以及视图层自定义的返回体结构其实在客户端全栈来说都没什么意义。
下面举个例子来看下如何定义graphql 的schema:
# Graphql Schema 根结构
schema {
query: Query
mutation: Mutation
subscription: Subscription
}
# 在GraphqlAgent 中每个接口按照这个interface 结构外加一个`data` 属性来返回
# `code` 为接口的执行是否成功,比如S_OK 为成功,FA_XXX 则表示出现特定错误了
# `errorMessage` 为接口执行错误时可能给到的提示
interface IResponseSchema {
code: String!
errorMessage: String
}
# 声明一个用户信息的复合结构
type UserInfo {
phone: String!
userName: String
}
# 当GraphqlAgent 中的接口执行后,只需要告诉调用者有没有错误,而没有实质要返回的数据时就以这个结构返回
type Scale_Plain_Response implements IResponseSchema {
code: String!
errorMessage: String
}
# 当GraphqlAgent 需要额外返回用户信息时就以这个结构返回
type User_UserInfo_Response implements IResponseSchema {
code: String!
errorMessage: String
data: UserInfo
}
# 当前Graphql 服务支持的query api 签名
type Query {
userGetUserWithPhone(phone: String!): User_UserInfo_Response!
accountGetUserInfo: User_UserInfo_Response!
}
# 当前Graphql 服务支持的mutation api 签名
type mutation {
accountChangePhone(newPhone: String!): Scale_Plain_Response!
}
# 当前Graphql 服务支持的subscriptions api 签名
type Subscription {
subscriptionUserUpdateUserInfo: UserInfo!
}
在实际使用中,发现在复合的graphql 查询返回体中,code 字段并不能很好的表达每个子查询的执行结果,所以,我在项目中做了个约定,即所有query、mutation 接口的返回体都必须是IResponseSchema 的超类,即都要使用独立的code 来表达自身的执行结果。
下面举个发起查询以及处理查询的例子:
import Agent, { ResponseCode } from 'GraphqlAgent';
import gql from 'graphql-tag';
// 在GraphqlAgent 中使用了apollo-client 作为了graphql 客户端
let apolloClient = Agent.client;
async function graphqlRequestDemo() {
// 编写复合查询语句
let response = await apolloClient.query({
query: gql`
query queryDemo($userPhone: String!) {
userGetUserWithPhone(phone: userPhone) {
code,
errorMessage,
data {
phone,
userName
}
}
accountGetUserInfo() {
code,
errorMessage,
data {
phone,
userName
}
}
}
`,
variables: {
userPhone: 10086
}
});
// Apollo-client 的返回体与graphql 的返回体不太一致
// 当errors 存在时可以认为出现了未被捕获的错误
if (response.errors) {
console.warn(response.errors);
return;
}
let { userGetUserWithPhone, accountGetUserInfo } = response.data;
console.log(userGetUserWithPhone.code);
console.log(accountGetUserInfo.code);
}
上面的例子大致能了解graphql 中是怎样定义schema 以及如何发起查询请求和处理请求的。
那么问题来了,上述所定义的schema 是怎样反应到代码上的呢?具体的查询接口又是怎样写的?apollo-client 发起的请求怎样到达GraphqlAgent 层中写的接口?graphql 中的subscriptions 怎样实现呢?下面一一道来哈。
Schema 定义与编译
项目中,引入了type-graphql 来完成schema 定义以及编译。以上面schema 例子作为参考来说下如何用代码表达整个schema。
首先,type-graphql中提供了几种decorator 来帮助定义schema:
-
@ObjectType()用于自定义复合结构,比如上面的type UserInfo和type Scale_Plain_Response,但type Query、type Mutation、type Subscription除外; -
@Field()用于定义复合结构中的属性,比如UserInfo中的:phone: String!; -
@Resolver()是type-graphql中特有的一个概念,是一个类修饰符,所有query、mutation、subscription 接口的实现(貌似)只能以实例方法存在于被@Resolver()修饰的类中(有点拗口,下面会有例子); -
@Query()用于声明query 接口; -
@Mutation()用于声明mutation 接口; -
@Subscription()用于声明subscription 接口; -
@Arg()用于声明接口中接受的参数;
下面简单举个例子来阐述各decorator 的使用:
import {
ObjectType,
Field,
Resolver,
Query,
Mutation,
Subscription,
Arg
} from 'type-graphql';
@ObjectType()
class UserInfo {
@Field()
phone: string;
@Field({ nullable: true })
userName?: string;
}
@ObjectType()
class User_UserInfo_Response {
@Field()
code: string;
@Field({ nullable: true })
errorMessage?: string;
@Field(returnType => UserInfo);
data: UserInfo;
}
@Resolver()
export default class UserResolver {
@Query(returnType => User_UserInfo_Response)
public userGetUserWithPhone(@Arg('phone') phone: string): User_UserInfo_Response {
return {
code: 'S_OK',
data: {
phone: phone,
userName: 'foo',
}
}
}
@Subscription({topics: 'pubsub_topic_string'})
public subscriptionUserUpdateUserInfo(payload: any): UserInfo {
return payload;
}
}
接下来,我们需要将上面定义的schema 交给type-graphql 来编译出真正可用的graphql runtime schema。
这里先说下什么叫可用的graphql schema。通过对graphql.js 源码的简单浏览,大致上对Graphql 的运行原理有了个理解。本质上,graphql runtime schema 可以简单理解为一个[path, resolveFunction] 的集合,以上面的schema 为例,对应的runtime schema 大致类似于:
{
query: {
'userGetUserWithPhone': function userGetUserWithPhone(phone: string) {
return {
code: 'S_OK',
data: {
phone: phone,
userName: 'foo',
}
}
}
},
mutation: {}
}
当graphql 收到请求时,则会解析出请求中的path 列表,然后在runtime schema 中查找各个path 对应api 函数。于是,所谓的编译 runtime schema,简单理解就是type-graphql 会帮我们定义的schema 编译成类似上面的[path, resolveFunction] 集合。代码如下:
import { buildSchemaSync } from 'type-graphql';
import UserResolver from './UserResolver';
export default function buildRuntimeSchema() {
// 同步编译runtime schema
return buildSchemaSync({
resolvers: [ UserResolver ],
})
}
当然,上面的说法没有提及类型相关的细节,graphql 里面的逻辑会复杂很多,但这我们理解这件事并无大碍。
Apollo-Client
上面我们看到过如何使用type-graphql 定义和编译Graphql Schema,当执行完buildSchemaSync后基本就没type-graphql什么事了。然后也看到通过将编写的查询语句发给GraphqlAgent 暴露的apollo-client 实例来执行查询并处理返回的响应。
那apollo-client 的查询是怎样发到编译好的schema 中呢?答案在创建apollo-client 时所使用的apollo-link 中间件队列。当client 会将查询语句以及相关上下文都会扔到link 队列中逐层传递,名副其实中间件。所以,正常来说,如果client 对接的是http 服务器,就需要在link 队列中使用apollo-link-http 来完成网络请求以及底层的网络响应处理。而如果对接的只是本地的schema,则可以在link 队列中使用apollo-link-schema,代码如下:
import ApolloClient from 'apollo-client';
import { SchemaLink } from 'apollo-link-schema';
import buildRuntimeSchema from './buildRuntimeSchema';
export const client = new ApolloClient({
link: new SchemaLink({
schema: buildRuntimeSchema()
}),
... // more options
})
代码中,将type-graphql 编译得到的schema 传给SchemaLink 即可,非常简单。
实现Graphql Subscriptions
嗯,原理上,这其实有点绕。。。
项目中,当客户端需要及时知道服务端某些变化或及时收到来自服务端的通知,我们往往会让服务端将这些变化或通知以{topic, payload} 的方式推送,然后客户端订阅相关topic,然后处理收到的payload。这种推送,正是需要subscriptions 出场的时候了。相对于query、mutation 偏向于主动“拉取”的语义,subscriptions 则偏向于“订阅”、“推送”的语义。
实现上,我们需要先利用type-graphql 在服务端的graphql schema 中定义好支持的topic。在上文UserResolver 的定义中其实就展示了如何定义subscription schema:
@Resolver()
export default class UserResolver {
@Subscription({topics: 'pubsub_topic_string'})
public subscriptionUserUpdateUserInfo(payload: any): UserInfo {
return payload;
}
}
这里,我们在schema 中定义了一个topic 为subscriptionUserUpdateUserInfo,payload 类型为:UserInfo 的subscription。
然后我们看下如何订阅这个topic 并处理payload:
import Agent, { ResponseCode } from 'GraphqlAgent';
import gql from 'graphql-tag';
// 在GraphqlAgent 中使用了apollo-client 作为了graphql 客户端
let apolloClient = Agent.client;
async function graphqlSubscriptionsDemo() {
let observable = Agent.client.subscribe({
query: gql`
subscription {
subscriptionUserUpdateUserInfo {
phone,
userName
}
}
`
});
let subscription = observable.subscribe(data => {
let userInfo = data['subscriptionUserUpdateUserInfo'];
console.log(userInfo.phone, userInfo.userName);
// subscription 创建了就记得销毁哦,否则会有内存泄漏
subscription.unsubscribe();
subscription = null;
});
}
这里,我们将查询语句传给 apollo-client 的subscribe 方法,然后返回了一个冷启动的observable。到这里,熟悉RxJS 的朋友应该知道怎么处理了。需要提醒一下,apollo-client 返回的observable 不是RxJS/Observable 类型,而是zen-observble,虽然两者都是来源于javascript 的"Observables" 规范,但在helpers 函数上不完全一致哦。
ok,上面展示了如何定义schema 和如何订阅推送。下面来说下如何触发推送以及当observable.subscribe() 触发时发生了什么?
在type-graphql 编译生成的schema 中使用的是Publish-Subscribe 的设计来触发推送。具体来说,type-graphql中实例化了一个graphql-subscriptions 中的PubSub 单例并保存到内部作用域中。回顾刚才在type-graphql 中定义schema 时,我们在@Subscription 的decorator 中传了一个包含topics 属性的对象,这个topics 用途就是,当冷启动的observable 触发订阅时,就会触发schema 监听type-graphql 内部的PubSub 单例,当这个PubSub 单例有对应topic 消息publish 时,就会触发schema 定义的函数来处理请求,进而将结果传给observable.subscribe() 触发时创建的Observer。
嗯,我还想再说深层一些。。。
在标准的apollo-client 实践中,使用的是apollo-link-ws 来做客户端订阅,而在ddder 中,我提供了apollo-link-subscription 中间件来生成client.subscribe() 返回的observable,当该observable 启动时,会在link 上下文中获取由type-graphql 生成的schema 以及查询语句生成的document,并传给graphql.js 的subscribe 方法来触发对PubSub topic 的订阅。
下面把这整个subscribe 的流程中设计的代码理顺一下:
- schema 定义的subscription 被
type-graphql编译后,在runtime schema 中大致是这样的存在:
{
subscriptions: {
subscriptionUserUpdateUserInfo: {
subscribe: () => pubSub.asyncIterator('pubsub_topic_string'),
resolve: payload => payload,
}
}
}
-
apollo-client中需要根据查询语句的类型,判断走apollo-link-schema还是apollo-link-subscription:
import { SchemaLink } from 'apollo-link-schema';
import { SubscriptionLink } from 'apollo-link-subscription';
new ApolloClient({
link: splitLink(
({ query }) => {
const { kind, operation = undefined } = getMainDefinition(query);
return kind === 'OperationDefinition' && operation === 'subscription';
},
new SubscriptionLink({
schema: schema
}),
new SchemaLink({
schema: schema
})
),
... // more options
});
- 当客户端调用
Agent.client.subscribe时发起subscribe类型查询时,会进入apollo-link-subscription,此时,就会马上返回一个冷启动的Observable,当Observable 启动时,会调用graphql.js 的subscribe 方法,并将schema 和查询语句传进去:
import { Operation, FetchResult, Observable } from 'apollo-link';
import { subscribe, GraphQLSchema } from 'graphql';
return new Observable<FetchResult>(observer => {
let asyncIterator = null;
subscribe( // 调用graphql.js 的subscribe 方法
this.schema, // runtime schema
operation.query, // 查询语句被gql 编译后的query 结构
this.rootValue,
typeof this.context === 'function'
? this.context(operation)
: this.context,
operation.variables,
operation.operationName,
).then(_asyncIterator => {
// subscribe 方法返回的是AsyncIterator,类型对象
// 参见:https://github.com/tc39/proposal-async-iteration
asyncIterator = _asyncIterator;
asyncIterate(
asyncIterator,
observer.next.bind(observer),
observer.complete.bind(observer),
observer.error.bind(observer),
() => observer.closed
);
}).catch(error => {
if (!observer.closed) {
observer.error(error);
}
});
return () => {
if (asyncIterator) {
asyncIterator.return();
asyncIterator = null;
}
}
});
在graphql.js 的subscribe 方法中:
- 根据查询语句中指定的path 找到对应的subscribe 函数触发pubSub 对应topic 的订阅:
// graphql-js
// src/subscription/subscribe.js
// function subscribeImpl()
// 关键代码:
const sourcePromise = createSourceEventStream(
schema,
document,
rootValue,
contextValue,
variableValues,
operationName,
subscribeFieldResolver,
);
// function createSourceEventStream()
// 关键代码:
const resolveFn = fieldDef.subscribe || exeContext.fieldResolver;
const result = resolveFieldValueOrError(
exeContext,
fieldDef,
fieldNodes,
resolveFn, // runtime schema 中path 对应的subscribe 函数
rootValue,
info,
);
// function resolveFieldValueOrError()
// 该函数会调用resolveFn,也就是subscribe 函数的调用
// 类似于(() => pubSub.asyncIterator('pubsub_topic_string'))();
- 当pubSub 有消息推送时,会触发path 对应的resolve 函数进行payload 处理:
// graphql-js
// src/subscription/subscribe.js
// function subscribeImpl()
// 关键代码:
// 形参就是pubSub 推送过来的payload
// `execute()` 方法是`graphql-js` 内部的方法,就是内部根据schema 和查询语句执行queyr、mutation 函数的入口
const mapSourceToResponse = payload =>
execute(
schema,
document,
payload,
contextValue,
variableValues,
operationName,
fieldResolver,
);
execute 函数返回后,就会触发asyncIterator 的一次onNext,进而成功完成了一次推送。
That's all~~~
另外,type-graphql 中支持自定义pubSub 的实例,于是项目中,我会另外创建一个独立的pubSub 作为整个GraphqlAgent 的推送来源。只要能拿到这个pubSub 实例,就能让其他模块在适当时候触发推送:
import { buildSchemaSync } from 'type-graphql';
import { PubSub } from 'graphql-subscriptions';
import UserResolver from './UserResolver';
export const pubSub = new PubSub();
export default function buildRuntimeSchema() {
// 同步编译runtime schema
return buildSchemaSync({
pubSub: pubSub,
resolvers: [ UserResolver ],
})
}
强缓存控制与复合数据
另外,参考了Telegram 的API,GraphqlAgent 每个接口返回的数据基本都是复合型数据。比如名为messageGetById 会根据留言id 获取留言信息,那简单的返回像是:
{
messageId: 123,
senderId: 123,
receiverId: 456,
content: 'hello word',
}
那所谓的复合结构,就是返回留言信息时会将留言中涉及的其他entity 一并返回,比如用户信息:
{
messageInfo: {
messageId: 123,
senderId: 123,
receiverId: 456,
content: 'hello word',
},
userList: [
"123": {
userName: 'foo',
},
"456": {
userName: 'bar',
}
]
}
终于说完DDDER 架构演变了,花了很多篇幅在阶段三中,主要是因为这层的架构有点复杂,不记详细点,真的会忘掉思路的。
最后,感谢老大给予了我这么大的自由度来折腾,也感谢团队对我的信任,也感谢业界同行对我的巨大帮助,阿里嘎多~~~
全文终!
api 封装那部分我也搞了个库 https://github.com/tuateam/tua-api 中间件直接用 koa-compose...
通过配置来表达api 和中间件的设计挺好的,tua-api 几乎所有api 运行的细节封装起来,将来一旦架构设计修改时也能轻易在tua-api 内部做出调整,不用改业务代码,赞👍~~~
反而利用rest-link 写api 时会将大部分机制暴露到开发者面前,重构起来会比较麻烦。。。
不过在业务代码使用api 时,我会倾向使用能被IDE 索引的方案(比如作为模块顶级变量导出),tua-api 调用时要手写api 名称,感觉IDE 可能会索引不出来?