roaring-rs
 roaring-rs copied to clipboard
roaring-rs copied to clipboard
Optimization: Galloping Array-Array operations
Most of the Array-Array operations use a two pointer walk. I think there may be gains to be had from "galloping" while merging.
To my knowledge this is a novel optimization. CRoaring vectorized Array-Array intersection is galloping (according to the paper) however AFAICT none of the scalar Array-Array ops perform galloping.
Links https://en.wikipedia.org/wiki/Timsort#Galloping_mode_during_merge http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/share/classes/java/util/TimSort.java#l701
I suspect the likelihood of entering galloping mode goes down (to zero?) for bitmaps that have run compression enabled.
I took a closer look at CRoaring and it has an optimization that's very similar to galloping in it's scalar Array-Array intersection.
https://github.com/RoaringBitmap/CRoaring/blob/1c2554436a9204fa3e2e62cc06e3910acf2bb8de/src/array_util.c#L730
It contains very clever 4-way and 2-way binary searches. It's impossible to translate into safe rust as-is. small and large would be shared refs that might alias the same memory as the exclusive ref to buffer.
I did a very ugly translation to rust, and constructed some benchmarks that:
- Filter only the array containers from bitmaps in the sample datasets, thus restricting all operations to Array-Array ops
- Conduct a pairwise and assign.
1 &= 2,2 &=3...N-1 &= N - Compare the current implementation to a 100% safe rust translation of CRoaring, and another that uses unsafe get_unchecked, and croaring (rust wrapper of CRoaring), named
curoptandopt_unsafeandcrespectively
Results
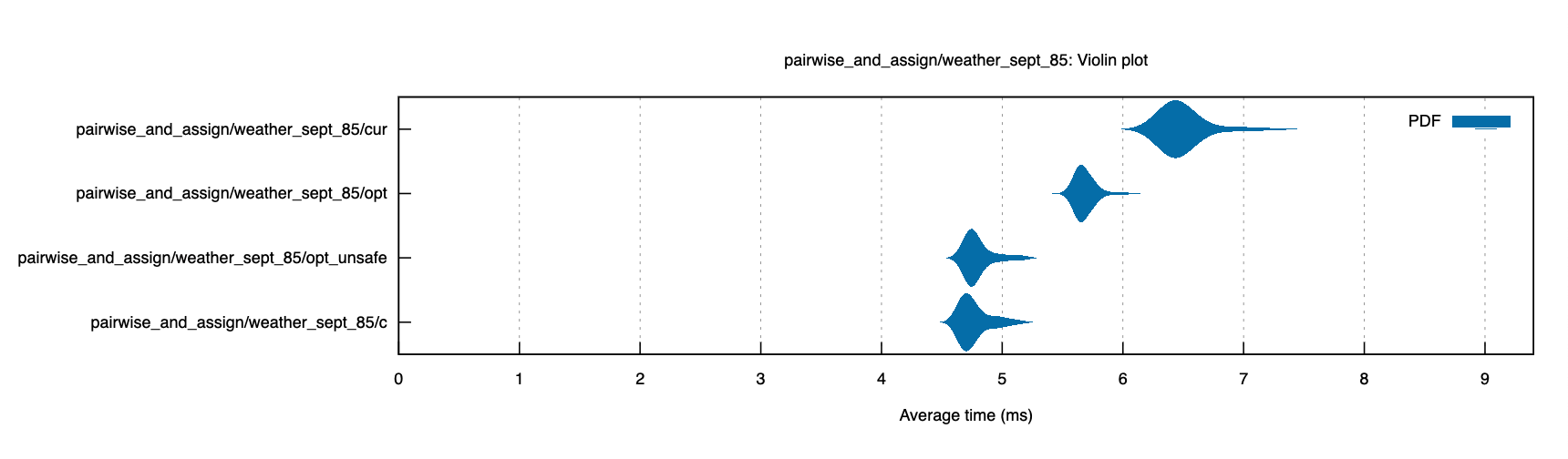
The unsafe version is comparable to croaring. It's difference is most pronounced in the weather_sept_85 dataset, so I'll show that here. I've also included the zipped benchmark run, which includes all datasets.
 criterion.zip
criterion.zip
Other notes:
- For BitAndAssign, CRoaring uses a hand-written vectorized algorithm. We would need to write explicit SIMD to be comparable in perf. (BitAndAssign is not vectorized)
Further exploration
- Check if there are some
assert!s that will get the safe code to run as fast as the unsafe variant - Look into explicit SIMD
- Do an all-for-all comparison, rather than a pairwise comparison. (guards against bitmaps that have non-intersecting containers)
I would like to see the ported versions you are talking about i.e. opt and opt_unsafe. Maybe I can find something interesting. But I like the fact that maybe simple assert!s could make the safe code faster.
You were talking about the small and large pointers in the C version that could possibly be aliased, Rust is allowed to alias non-mutable slices, it is only forbidden for mutable memory areas. So maybe you can translate the C version to a safe Rust version version with two unmutable aliased slices?
I would like to see the ported versions you are talking about i.e. opt and opt_unsafe. Maybe I can find something interesting. But I like the fact that maybe simple assert!s could make the safe code faster.
This branch I'm working in is an absolute mess, theres many different versions of each operation for a bunch of failed experiments. I'll toss the relevant parts in a gist until I can tidy up.
You were talking about the small and large pointers in the C version that could possibly be aliased, Rust is allowed to alias non-mutable slices, it is only forbidden for mutable memory areas. So maybe you can translate the C version to a safe Rust version version with two unmutable aliased slices?
It's not the two shared refs that alias, it's that the exclusive ref to the output buffer can alias either of the two shared res. Which violates rust safety.
I worked around the problem by providing two copies of the same function. One where small is mutable, and one where large is mutable. It's terrible, but it was good for running benchmarks.
This branch I'm working in is an absolute mess, theres many different versions of each operation for a bunch of failed experiments. I'll toss the relevant parts in a gist until I can tidy up.
@Kerollmops On second thought I just pushed it up in it's wildy unorganized glory, mostly because I didnt feel like putting a license on my gist. 🤣
Current impl: https://github.com/saik0/roaring-rs/blob/594cf85a67b640daa91de6af1da395b3e2dc6332/src/bitmap/store/array_store.rs#L340
The "opt", which mostly consists of a port of CRoaring's intersect_skewed : https://github.com/saik0/roaring-rs/blob/594cf85a67b640daa91de6af1da395b3e2dc6332/src/bitmap/store/array_store.rs#L983
Entrypoint to "opt" https://github.com/saik0/roaring-rs/blob/377760780e678279e082aff24fa8beea62e400d8/src/bitmap/store/array_store.rs#L1361
The "opt", which mostly consists of a port of CRoaring's intersect_skewed
Wow the binarySearch4 and binarySearch2 are not complex at all, I find them quite simple to understand, maybe we can use them. But the opt_unsafe version seems better, is it way more complex than that?
The ones with "gallop" in the name are failed experiments. Tried an adaptive galloping merge based on TimSort merge that I linked in main issue.
Wow the binarySearch4 and binarySearch2 are not complex at all, I find them quite simple to understand, maybe we can use them. But the opt_unsafe version seems better, is it way more complex than that?
Keep scrolling. They are called by "opt"
It's worth noting that doing a pairwise and over all the datasets, the hottest code path is actually this: https://github.com/saik0/roaring-rs/blob/594cf85a67b640daa91de6af1da395b3e2dc6332/src/bitmap/store/array_store.rs#L429
The skewed, with all it's binary searching, is an optimization for when one array contains 64x more than the other.
Keep scrolling. They are called by "opt"
Hum... Yeah, indeed! But at least there is no CPU-specific SIMD instruction here 😄