spark-redis
 spark-redis copied to clipboard
spark-redis copied to clipboard
How to write a byte array column to Redis?
I have a PySpark DataFrame with 2 columns [key, bz2], in which "key" is string and "bz2" is bytes (BinaryType). I want to write this dataframe into Redis, then my teammates will read them out using Node API.
I tried ways like (1) df.write.format("org.apache.spark.sql.redis").option("table", "PP").option("key.column", "key").option("host", REDIS_HOST).option("port", REDIS_PORT).option("auth", REDIS_PW).option("timeout", 100000).mode("append").save() (2) df.write.format("org.apache.spark.sql.redis").option("table", "PP").option("key.column", "key").option("host", REDIS_HOST).option("port", REDIS_PORT).option("auth", REDIS_PW).option("timeout", 100000).mode("append").option("model", "binary").save()
The 1st method will write only a short and incorrect sequence into Redis, will lose a lot of information. For the 2nd method, we don't know how to decode the persisted bytes with other languages like Node. The "binary" persistence mode seems only work with Spark-Redis library.
So, is it possible to write a byte array DataFrame column to Redis? How to do that?
Please advise. Thanks a lot.
It looks like this data type is currently not supported. I will investigate the details later.
@fe2s
I am having the same issue. I have a binary value (Array[Byte]) as follows -
[AB CD EE 8F DB 89 4F 33 9E 30 60 8B 2F 20 17 B4]
When writing to Redis as -
binary_values.write.format("org.apache.spark.sql.redis").mode(SaveMode.Append).option("table", "test").option("key.column", "value_binary").save()
the data in Redis appears as -
test:[B@2ef2a865
I understand that Array[Byte] is not supported.
I have tried converting the Array[Byte] to String and saving in Redis, but it seems to convert the String to UTF-8. Is there any way I can save a String without applying any encoding?
Any advice is much appreciated.
@iyer-r , I will take a look if we can support byte arrays.
Why doesn't UTF-8 work for you? Not sure I understood the question of converting a byte array to String without any encoding.
@fe2s
Here is an example -
Byte Array = [AB CD 22 A5 4B 2E 43 68 A0 65 3A 47 89 7E 50 B0]
String Representation = «Í"¥K.Ch e:G~P°
When I save this in Redis as a String column, it gets saved as -
test:\xc2\xab\xc3\x8d\"\xc2\xa5K.Ch\xc2\xa0e:G\xc2\x89~P\xc2\xb0
which is the UTF-8 representation of the above string.
I would expect it to be saved as \xab\xcd\"\xa5K.Ch\xa0e:G\x89~P\xb0 instead.
Hope this helps.
@iyer-r , Do you Scala or Python? How do you convert Byte Array to String? Please share you code.
If you use Python, I guess it might be because bytes in Python are in a range [0,255], whereas in Scala/Java [-128,127]. So if you use Spark built-in function to convert column type, the result might be different to what you expect in Python.
@fe2s
Apologies for the delay in getting back.
Here is the Scala code that attempts to write a byte array --
import org.apache.spark.sql.types._
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.Row
sc.stop()
val spark = SparkSession.builder().master("local").config("spark.redis.host", "10.114.71.171").getOrCreate();
val toBinary = udf((input: String) => {
var sb = new StringBuilder
for ( i <- 0 until input.size by 2)
{
val str = input.substring(i, i + 2)
sb.append(Integer.parseInt(str, 16).toChar)
}
sb.toString.toCharArray.map(_.toByte)
})
val rawData = Seq(Row("ABCD22A54B2E4368A0653A47897E50B0"))
val schema = StructType(List(StructField("string_value", StringType, true)))
val df = spark.createDataFrame(spark.sparkContext.parallelize(rawData), schema)
df.show()
val binary_df = df.withColumn("binary_value", toBinary($"string_value"))
binary_df.show()
binary_df.write.format("org.apache.spark.sql.redis").mode(SaveMode.Append).option("table", "test").option("key.column", "binary_value").save()
And here is the Redis output -
10.114.71.171:6379> keys *
1) "test:[B@6008e6bd"
2) "_spark:test:schema"
Here is how I am attempting to write a String value, instead of a Byte array -
import org.apache.spark.sql.types._
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.Row
sc.stop()
val spark = SparkSession.builder().master("local").config("spark.redis.host", "10.114.71.171").getOrCreate();
val toBinary = udf((input: String) => {
var sb = new StringBuilder
for ( i <- 0 until input.size by 2)
{
val str = input.substring(i, i + 2)
sb.append(Integer.parseInt(str, 16).toChar)
}
sb.toString
})
val rawData = Seq(Row("ABCD22A54B2E4368A0653A47897E50B0"))
val schema = StructType(List(StructField("string_value", StringType, true)))
val df = spark.createDataFrame(spark.sparkContext.parallelize(rawData), schema)
df.show()
val binary_df = df.withColumn("binary_value", toBinary($"string_value"))
binary_df.show()
binary_df.write.format("org.apache.spark.sql.redis").mode(SaveMode.Append).option("table", "test").option("key.column", "binary_value").save()
And this is the corresponding output -
10.114.71.171:6379> keys *
1) "test:\xc2\xab\xc3\x8d\"\xc2\xa5K.Ch\xc2\xa0e:G\xc2\x89~P\xc2\xb0"
2) "_spark:test:schema"
Hi @raj-blis ,
I didn't understand what you try to do. Your input dataframe has a string ABCD22A54B2E4368A0653A47897E50B0, why do you convert it to byte array (first snippet) or another string (second snippet) before saving? Can you please describe your use case? What type of data do you have in spark and how do you want to consume it from Redis after saving?
Hi @fe2s ,
The input dataframe is a string with 32 hexadecimal characters.
By saving it in binary format (i.e. 2 hexadecimal characters clubbed into a corresponding character) - I can reduce the memory usage by half.
Thus instead of saving a string like - ABCD22A54B2E4368A0653A47897E50B0, I am trying to save it as -
- An array of bytes like
[AB CD 22 A5 4B 2E 43 68 A0 65 3A 47 89 7E 50 B0]as in the first example (which ends up being saved astest:[B@6008e6bdinstead) - A string of 16 characters where each character corresponds to the above bytes -
«Í"¥K.Ch e:G~P°(which ends up being saved astest:\xc2\xab\xc3\x8d\"\xc2\xa5K.Ch\xc2\xa0e:G\xc2\x89~P\xc2\xb0instead - had it been saved correctly, it should appear astest:\xab\xcd\"\xa5K.Ch\xa0e:G\x89~P\xb0in the redis-cli output; the additional \xc2 characters that you see are due to UTF8 conversion)
Hope that explains the situation.
I ran with a raw option: redis-cli --raw and see that the string is the same as in spark before saving:
127.0.0.1:6379> keys *
test:«Í"¥K.Ch e:G~P°
_spark:test:schema
Also, reading it back in spark-redis gives me the same string:
val readDf = spark.read.format("org.apache.spark.sql.redis").option("table", "test").option("key.column", "binary_value").load()
readDf.show()
+--------------------+----------------+
| string_value| binary_value|
+--------------------+----------------+
|ABCD22A54B2E4368A...|«Í"¥K.Ch e:G~P°|
+--------------------+----------------+
Do you see any issues with that?
Hi @fe2s,
For my use-case, I am writing data using Spark-Redis and querying through a C++ application.
For the given input - ABCD22A54B2E4368A0653A47897E50B0, here is a TCP dump of the query from C++ -

See the highlighted part is the actual input above.
This query does not yield any result. When I do a KEYS * command and take a tcpdump, here is what comes up -
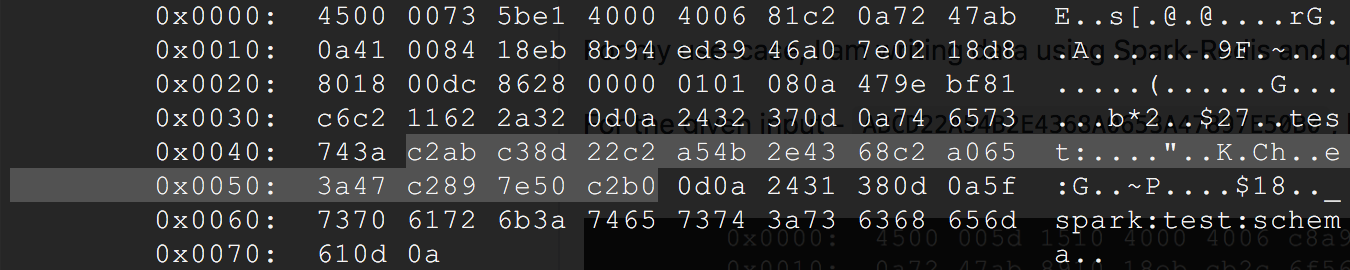
As you can see, what is stored in Redis has embedded \xC2 characters in it, which are caused by UTF-8 conversion, hence the C++ code is not able to query for the key.
Your attempt to write and read back in Scala worked, because you are also reading back the UTF-8 encoded value.
From my understanding this is because we are using Java Strings, see sb.toString in the toBinary method. Java strings have a default encoding of UTF8.
Hence the need to be able to write the actual byte[], instead of a String. Hope that explains the situation.
Hi @raj-blis ,
Thanks for the detailed explanation. You are right, spark-redis uses string based API. I will take a look if we store raw byte array without converting to string.
Hi @fe2s ,
Thank you for your patience with this matter.
Do you have any idea about how much work is involved and how long it will take? We need to plan work on our side accordingly. Also, I am happy to help in any way I can to progress on this.
Hi @raj-blis ,
in HashRedisPersistence we use string oriented Redis API to write and read data, i.e. Pipeline.hmSet() takes string parameters. This API works with byte[] alternatively and I guess this is what we need to address your request. It will require creating serialization and deserialization functions that converts any Spark type to a byte[] and vice-versa that might be tricky (something similar is done in java.io.DataOutputStream)
However I'm not sure how this would work if you then read these data directly from Redis with C++ client for instance.
In general your request with memory optimization is not very common. I'm thinking if it makes sense to create something very specific to your use case without generalization.
In the dataframe that you want to write, do you have other columns that are not byte[]?
Can we do something like this:
a) implement Spark-Redis support to write RDD[Array[Byte]] to Redis Key/Value data structure
b) in your Spark code convert DataFrame to RDD[Array[Byte]] with some custom serialization logic
c) parse byte array in your C++ client
Hi @fe2s
That sounds like a good plan.
Did you want to support the Array[Byte] in the HashRedisPersistence.save method in master branch or is this something we should be doing custom to ourselves?
@raj-blis ,
no, my suggestion was to implement RDD support for byte arrays, not DataFrame. It will be much easier. The API will be similar to this one, but it will take RDD[(Array[Byte], Array[Byte])], i.e. an RDD of key/value. Would it work for you?
@fe2s
Got it. The RDD should work too. Note that in my case, the key is an Array[Byte] and the value is a list of Array[Byte]. Can that be supported?
@raj-blis
Okay, we can implement a function spark.toRedisList() that takes RDD[(Array[Byte], Seq[Array[Byte]])] as an argument. It will store data in Redis List. RDD type is a tuple where first element is a list name and the second is a list of values. Would it work for you?
@fe2s
That sounds good. I will work on using RDD within our code.
Thanks for your help with this. Much appreciated.
Hi @raj-blis , I have implemented the function in this branch https://github.com/RedisLabs/spark-redis/tree/issue-205-toRedisByteLIST You should find the usage example in the unit test. Could you please test it with your use case and let me know if it works as expected?
Hi @fe2s
I have verified that this fix works and the data is stored and retrieved correctly in binary format.
Thank you for patiently going through this and coming up with the fix.