Hierarchical-Multi-Label-Text-Classification
 Hierarchical-Multi-Label-Text-Classification copied to clipboard
Hierarchical-Multi-Label-Text-Classification copied to clipboard
The code of CIKM'19 paper《Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach》
Hierarchical Multi-Label Text Classification
![]()


This repository is my research project, and it is accepted by CIKM'19. The paper is already published.
The main objective of the project is to solve the hierarchical multi-label text classification (HMTC) problem. Different from the multi-label text classification, HMTC assigns each instance (object) into multiple categories and these categories are stored in a hierarchy structure, is a fundamental but challenging task of numerous applications.
Requirements
- Python 3.6
- Tensorflow 1.15.0
- Tensorboard 1.15.0
- Sklearn 0.19.1
- Numpy 1.16.2
- Gensim 3.8.3
- Tqdm 4.49.0
Introduction
Many real-world applications organize data in a hierarchical structure, where classes are specialized into subclasses or grouped into superclasses. For example, an electronic document (e.g. web-pages, digital libraries, patents and e-mails) is associated with multiple categories and all these categories are stored hierarchically in a tree or Direct Acyclic Graph (DAG).
It provides an elegant way to show the characteristics of data and a multi-dimensional perspective to tackle the classification problem via hierarchy structure.

The Figure shows an example of predefined labels in hierarchical multi-label classification of documents in patent texts.
- Documents are shown as colored rectangles, labels as rounded rectangles.
- Circles in the rounded rectangles indicate that the corresponding document has been assigned the label.
- Arrows indicate a hierarchical structure between labels.
Project
The project structure is below:
.
├── HARNN
│ ├── train.py
│ ├── layers.py
│ ├── ham.py
│ ├── test.py
│ └── visualization.py
├── utils
│ ├── checkmate.py
│ ├── param_parser.py
│ └── data_helpers.py
├── data
│ ├── word2vec_100.model.* [Need Download]
│ ├── Test_sample.json
│ ├── Train_sample.json
│ └── Validation_sample.json
├── LICENSE
├── README.md
└── requirements.txt
Data
You can download the Patent Dataset used in the paper. And the Word2vec model file (dim=100) is also uploaded. Make sure they are under the /data folder.
(As for Education Dataset, they may attract copyright protection under China law. Thus, there is no details of dataset.)
Text Segment
-
You can use
nltkpackage if you are going to deal with the English text data. -
You can use
jiebapackage if you are going to deal with the Chinese text data.
Data Format
See data format in data folder which including the data sample files. For example:
{"id": "3930316", "title": ["sighting", "firearm"], "abstract": ["rear", "sight", "firearm", "ha", "peephole", "device", "formed", "hollow", "tube", "end", "closed", "peephole"], "section": [5], "subsection": [104], "group": [512], "subgroup": [6535], "labels": [5, 113, 649, 7333]}
- "id": just the id.
- "title" & "abstract": it's the word segment (after cleaning stopwords).
- "section": it's the first level category index.
- "subsection": it's the second level category index.
- "group": it's the third level category index.
- "subgroup": it's the fourth level category index.
- "labels": it's the total category which add the index offset. (I will explain that later)
How to construct the data?
Use the figure in Introduction as example, now I will explain how to construct the label index.
Step 1: Figure has 3 categories, you should index this 3 categories first, like:
{"Chemistry": 0, "Physics": 1, "Electricity": 2, "XXX": 3, ..., "XXX": N-1}
Note: N is the total number of your categories.
Step 2: You index the next level, like:
{"Inorganic Chemistry": 0, "Organic Chemistry": 1, "Nuclear Physics": 2, "Material analysis": 3, "XXX": 4, ..., "XXX": M-1}
Note: M is the total number of your subcategories.
Step 3: You index the third level, like:
{"Steroids": 0, "Peptides": 1, "Heterocyclic Compounds": 2, ..., "XXX": K-1}
Note: K is the total number of your level-3 categories.
Step 4: If you have the fourth level or deeper level, index them.
Step 5: Now Suppose you have one record:
{"id": "1", "title": ["tokens"], "abstract": ["tokens"], "section": [0, 1], "subsection": [0,1, 2, 3], "group": [0,1, 2, 3], "labels": [0, 1, 0+N, 1+N, 2+N, 3+N, 0+N+M, 1+N+M, 2+N+M, 3+N+M]}
Assume that your total category number of level-1 is 10 (N=10), of level-2 is 100 (M=100). N & M is the offset for the labels attribute.
the record should be construed as:
{"id": "1", "hashtags": ["token"], "section": [0, 1], "subsection": [0, 1, 2, 3], "group": [0, 1, 2, 3], "labels": [0, 1, 10, 11, 12, 13, 110, 111, 112, 113]}
This repository can be used in other datasets (text classification) in two ways:
- Modify your datasets into the same format of the sample.
- Modify the data preprocess code in
data_helpers.py.
Anyway, it should depend on what your data and task are.
Pre-trained Word Vectors
You can pre-training your word vectors(based on your corpus) in many ways:
- Use
gensimpackage to pre-train data. - Use
glovetools to pre-train data. - Even can use a fasttext network to pre-train data.
Usage
See Usage.
Network Structure
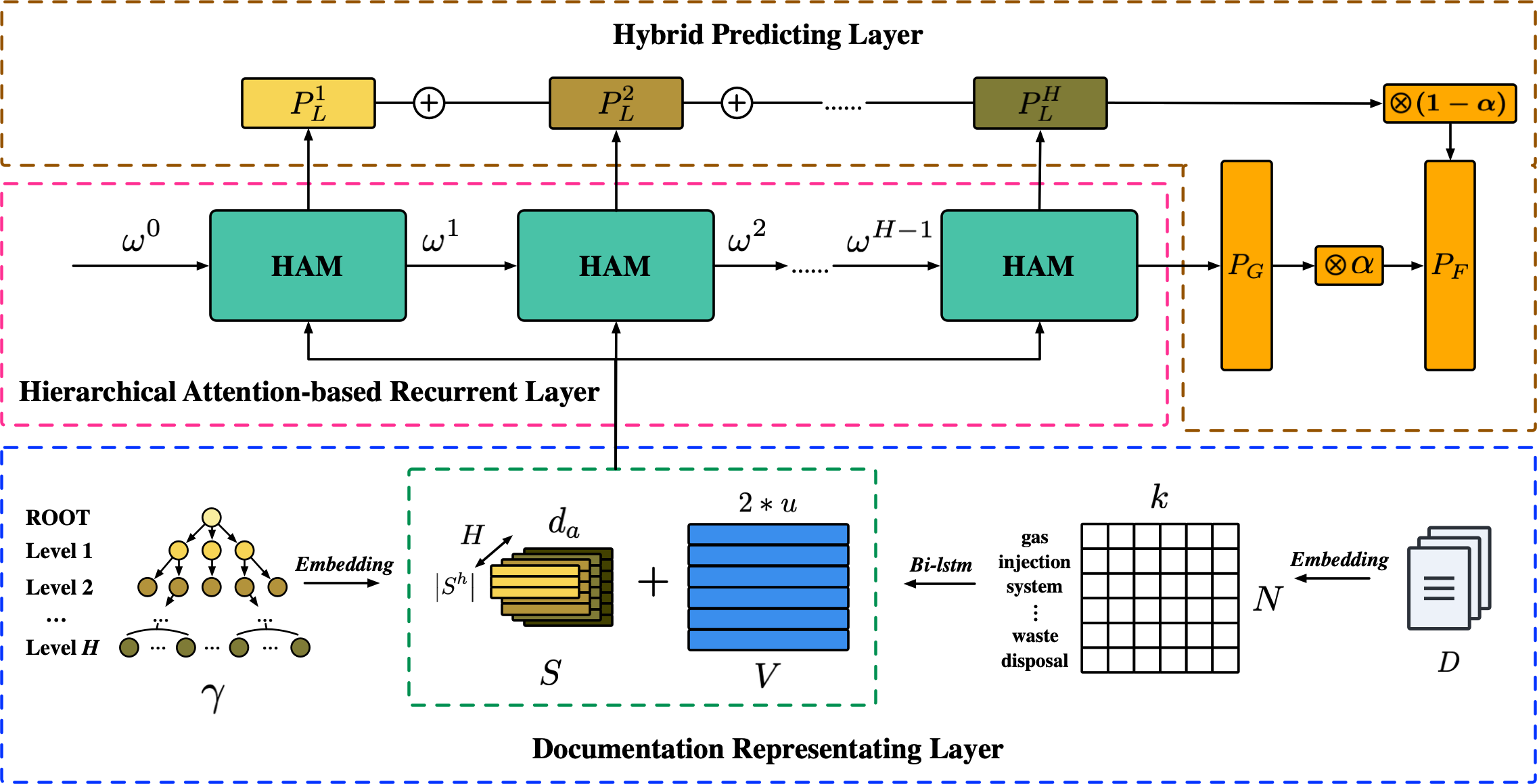
Reference
If you want to follow the paper or utilize the code, please note the following info in your work:
@inproceedings{huang2019hierarchical,
author = {Wei Huang and
Enhong Chen and
Qi Liu and
Yuying Chen and
Zai Huang and
Yang Liu and
Zhou Zhao and
Dan Zhang and
Shijin Wang},
title = {Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach},
booktitle = {Proceedings of the 28th {ACM} {CIKM} International Conference on Information and Knowledge Management, {CIKM} 2019, Beijing, CHINA, Nov 3-7, 2019},
pages = {1051--1060},
year = {2019},
}
About Me
黄威,Randolph
SCU SE Bachelor; USTC CS Ph.D.
Email: [email protected]
My Blog: randolph.pro
LinkedIn: randolph's linkedin
Metadata
Owner
Metadata
The code of CIKM'19 paper《Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach》