Build everything back to 2014.01
Kind of annoyed that we cannot bisect sometimes because the change is too old. It is surprising how often this happens.
In issue #23 it was noticed that lrz, although being relatively slow, does an amazing job compressing several builds at the same time. This means that for long-term storage we can put 50 (or so) builds together, and this way store most of them for free (in terms of storage). Yes, all operations with these builds will be slower, but I guess anyone can wait a second or two if they're trying to access something that old.
These changes are required:
-
build-existsshould try to find.zstarchives first, and if this fails try to find the build elsewhere. We will need some sort of lookup mechanism for finding the right file. - These two lines changed accordingly. Make sure that during this process we are not saving builds that are not required.
- Change
build.p6so that it can figure out that 50 consequent.zstarchives can be recompressed with.lrzinstead.
Just documenting some of the initial findings:
- If you compress 50 builds with lrz you get a ≈49 MB archive (fyi, each build is ≈28 MB, and if we compress each build separately with zstd we get ≈4.8 MB per build)
- Pessimistically, decompression of that big archive will only take 5 seconds (I only measured extraction of the whole thing, without skipping builds that are not needed)
ping @MasterDuke17, @timo
OK, so my estimation of 49 MB per archive with 50 builds was a little bit wrong. I've done some tests and here is what I've found:
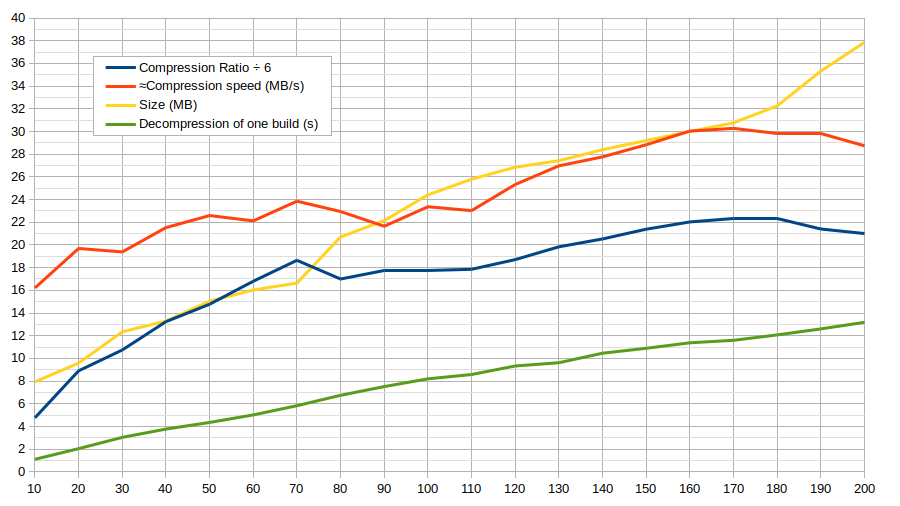 (We don't care about compression speed. Compression ratio is divided by 6 so that it fits into the graph nicely, and also because 6 is approximately equal to the current ratio we get with zstd)
(We don't care about compression speed. Compression ratio is divided by 6 so that it fits into the graph nicely, and also because 6 is approximately equal to the current ratio we get with zstd)
This was tested with a particular set of 200 builds, so it does not mean that we will see the same picture for other files. But it should give more insight than if I did nothing :)
A sweet spot seems to be around 60-80 builds per archive, but >4.5s delay just to get one build? Meh… Bisectable is not going to like it.
More info about my tests:
- I cleared disk cache before decompression so that it is a bit more pessimistic.
-
taris instructed to extract only one folder out of the whole archive, everything else is thrown away and is not saved to the disk. - I used
lrzipwith default settings. Maybe it used different window for different archives, I'm not sure (it is supposed to figure it out automatically). We should probably use it with--unlimitedoption, or just force the window size with--window. I don't think it will affect anything given that 200 builds uncompressed are a bit less than 6GB, and the server has much more available RAM than that. - Again, given that it is
lrzipwith default settings, it is using LZMA. Should I try with-loption so that it is using LZO instead? Note that space is not an issue at all, especially given that the compression ratio is easily over 100. - I was extracting the last build that was shown by
tar --list(andtar --listwas executed before the disk cache was cleared). I don't know if this is pessimistic, optimistic, random or something else.
OK, here it is with LZO:
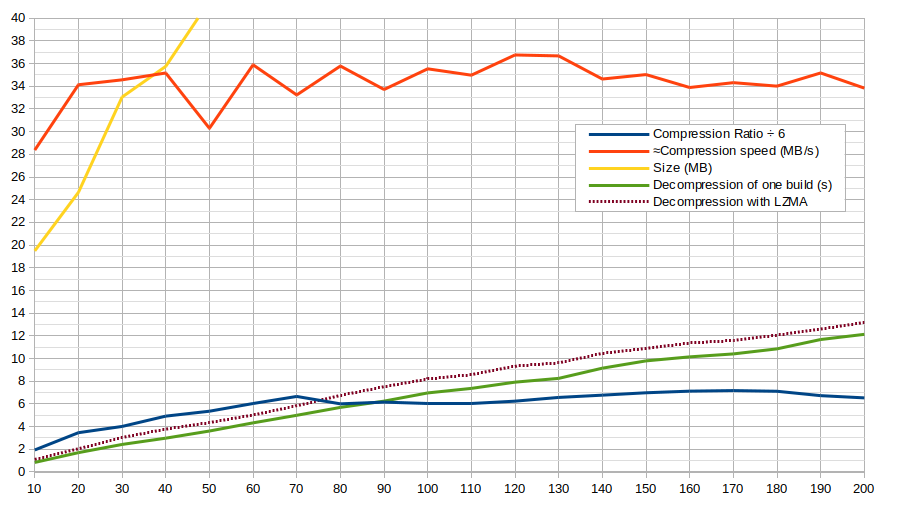
It is indeed faster. However, most of the time it is less than 1 second of a difference, but with a significant ratio downgrade… not worth it.
Any other ideas? :)
More experiments done, now with varying compression level (--level option in lrzip):
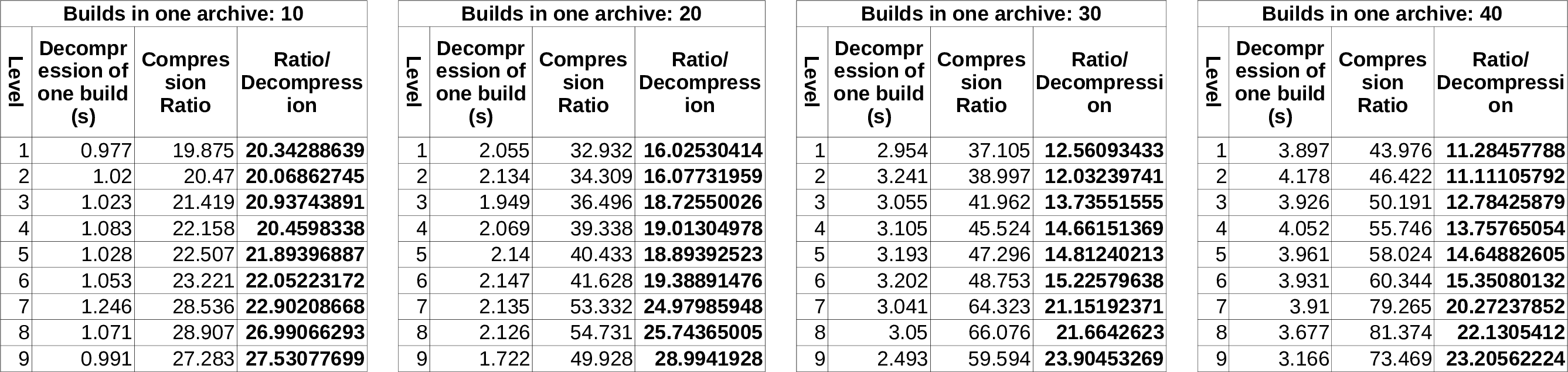
It's hard for me to interpret this meaningfully, but it seems that this magical ratio/decompression ratio is what we are after. For example, a value of 25 would mean that in both configurations it's doing equally, but we should pick the one that has a lower decompression speed.
I would appreciate any feedback on this, as I'm confused by the whole thing badly…
However, the sweep spot indeed seems to be on 20 builds per archive with level 9. Not exactly the best compression ratio there, but it's fast.
Ah, this is now done. We don't have any tests for build.p6 and I'm not sure if we ever will, so maybe this is closeable.
OK, we might want to revisit this. From zstd changelog:
Zstandard has a new long range match finder written by our intern Stella Lau (@stellamplau), which specializes on finding long matches in the distant past. It integrates seamlessly with the regular compressor, and the output can be decompressed just like any other Zstandard compressed data.
There are some graphs comparing zstd with lrzip, but we will have to test it out with our data.
That said, for https://github.com/perl6/whateverable/issues/122 this should be delayed. Both lrzip and zstd are in debian stable, and that should cover the majority of those who will attempt to run it.
Ignore what I said in the previous comment. Archives produced in long range mode should be usable by any version.
OK we should start dropping lrzip in favor of zstd I think (note that we're using both right now, so it will be 1 dependency less). See this: https://github.com/facebook/zstd/releases/tag/v1.3.4
@MasterDuke17++ for reminding.