RecBole
 RecBole copied to clipboard
RecBole copied to clipboard
[🐛BUG] 用自己的数据集跑FM模型时出现 TypeError
描述这个 bug 我根据原子文件的要求将自己的数据集 (lastfm 360k) 转换成了原子文件,在用run_recbole()跑General model 时没有问题,但在跑FM模型时出现 TypeError
如何复现 复现这个 bug 的步骤:
- 在colab content目录下建立folder “lfm360k”:/content/lfm360k
- 在lfm360k下上传.inter .user .item .yaml 文件
- 运行colab 下面的zip文件里有.inter .user .item .yaml 和 .ipynb 文件 lfm360k.zip
预期 想知道怎么解决这个bug,是原子文件的问题还是yaml文件的问题
屏幕截图
实验环境(请补全下列信息):
- 操作系统: Windows
@evelyn023 您好!感谢您对RecBole的关注与支持! 1.我在下载您的数据文件后发现了问题,您在yaml文件中的‘load_col’参数中设置了每一个原子文件中要加载的列,但.user和.item对应的加载列在原子文件中并没有出现,似乎是.user和.item两个文件的加载列写反了。 2.由于General model只涉及.inter文件而不涉及.user和.item文件,因此能够正确运行。 请您检查yaml文件中的‘load_col’参数并进行相应修改,如有后续问题欢迎您在下面列出。
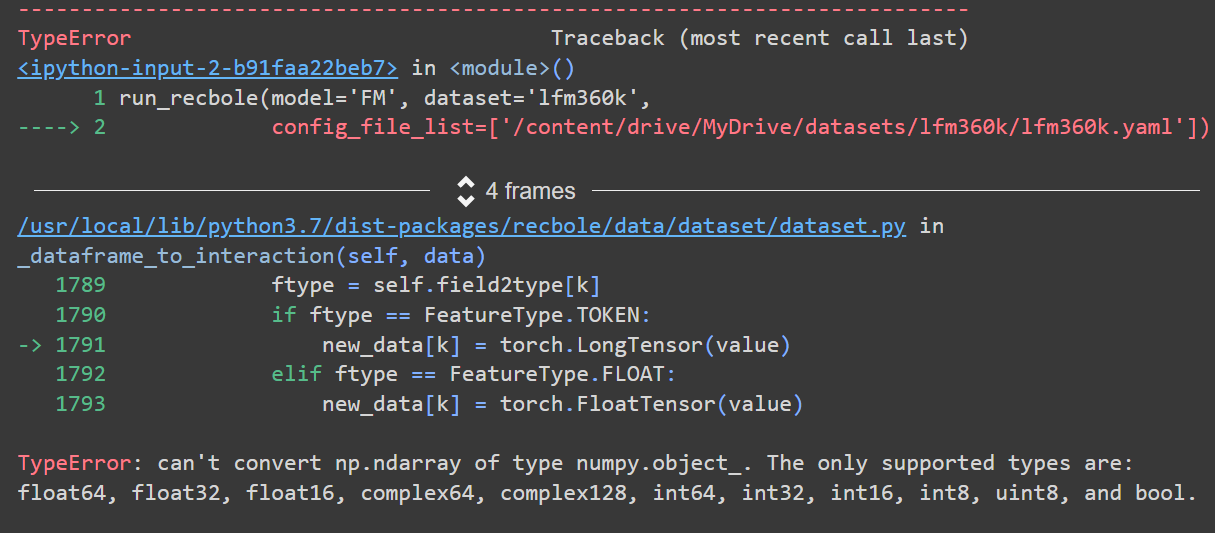
@Wicknight 你好!我把'load_col'修改后Remain Fields显示读取到了对应的加载列,但还是报相同的TypeError
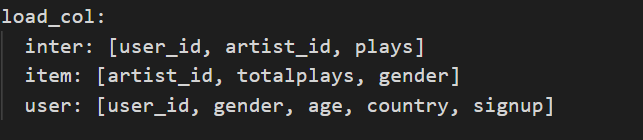
Remain Fields: ['user_id', 'artist_id', 'gender', 'age', 'country', 'signup', 'totalplays', 'label']
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-4-2250f1c77ac5>](https://localhost:8080/#) in <module>()
1 run_recbole(model='FM', dataset='lfm360k',
----> 2 config_file_list=['/content/drive/MyDrive/datasets/lfm360k/lfm360k_fm.yaml'])
4 frames
[/usr/local/lib/python3.7/dist-packages/recbole/quick_start/quick_start.py](https://localhost:8080/#) in run_recbole(model, dataset, config_file_list, config_dict, saved)
43
44 # dataset splitting
---> 45 train_data, valid_data, test_data = data_preparation(config, dataset)
46
47 # model loading and initialization
[/usr/local/lib/python3.7/dist-packages/recbole/data/utils.py](https://localhost:8080/#) in data_preparation(config, dataset)
138 else:
139 model_type = config['MODEL_TYPE']
--> 140 built_datasets = dataset.build()
141
142 train_dataset, valid_dataset, test_dataset = built_datasets
[/usr/local/lib/python3.7/dist-packages/recbole/data/dataset/dataset.py](https://localhost:8080/#) in build(self)
1472 list: List of built :class:`Dataset`.
1473 """
-> 1474 self._change_feat_format()
1475
1476 if self.benchmark_filename_list is not None:
[/usr/local/lib/python3.7/dist-packages/recbole/data/dataset/dataset.py](https://localhost:8080/#) in _change_feat_format(self)
979 for feat_name in self.feat_name_list:
980 feat = getattr(self, feat_name)
--> 981 setattr(self, feat_name, self._dataframe_to_interaction(feat))
982
983 def num(self, field):
[/usr/local/lib/python3.7/dist-packages/recbole/data/dataset/dataset.py](https://localhost:8080/#) in _dataframe_to_interaction(self, data)
1789 ftype = self.field2type[k]
1790 if ftype == FeatureType.TOKEN:
-> 1791 new_data[k] = torch.LongTensor(value)
1792 elif ftype == FeatureType.FLOAT:
1793 new_data[k] = torch.FloatTensor(value)
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
@evelyn023 这是由于您的原子文件.user文件和.item文件中使用了相同的特征'gender',并且取值空间明显不同,造成id的映射过程发生混乱,最终产生了这一错误。因此您可以将.item文件中的'gender'列更名为其它非重名名称。
@Wicknight 非常感谢!修改后我的FM模型已经可以跑通了,但是训练过程非常奇怪,training loss在50个epoch内都没有什么变化。我试了 learning rate=0.1/0.01/0.001/0.0001 以及调整 label threshold 都是这样的结果,请问是参数设置的问题还是数据集的问题呢?我刚开始接触推荐模型,感谢您的耐心解答
我的yaml文件是这样的 ''' data_path: /content/drive/MyDrive/datasets dataset: lfm360k
embedding_size: 64
field_separater: "\t" seq__separater: " " USER_ID_FIELD: user_id ITEM_ID_FIELD: artist_id RATING_FIELD: plays TIME_FIELD: None NEG_PREFIX: neg_ LABEL_FIELD: label threshold: plays: 50
load_col: inter: [user_id, artist_id, plays] item: [artist_id, totalplays, artist_gender] user: [user_id, gender, age, country, signup]
user_inter_num_interval: "[3,inf)" item_inter_num_interval: "[3,inf)" val_interval: plays: "[20,inf)"
epochs: 300 train_batch_size: 4096 learning_rate: 0.001 eval_step: 50 stopping_step: 10 training_neg_sample_num: 0
eval_args: split: { 'RS': [ 8, 1, 1 ] } group_by_user: False order: RO eval_batch_size: 10240
metrics: ['Recall', 'NDCG', 'Precision'] topk: 20 valid_metric: Recall@20 '''
@evelyn023 您的数据集文件有一些float类型字段,应该是由于这些字段数据分布有较大差异,导致出现该问题。经试验通过对float类型的特征进行归一化可以解决该问题,即在yaml文件中设置normalize_all: True。有关该参数的解释您可以查阅我们的文档。
@Wicknight 非常感谢!改正后训练过程正常了很多,经过300个epoch后training loss 由80+降到了0.0007,但是evaluation结果却很低,recall@20只有0.0074,几次调整后都不理想。我用同样的数据集训练BPR 300个epoch,recall@20能达到0.22,ItemKNN也能达到0.28,请问这样的结果是否有异常呢?FM考虑到user/item的feature是否应该比general model 准确性更高呢?
@evelyn023 这是由于context model和general model采用了不同的评测模式('eval_args'参数中的'mode'),您可以通过查看您的log文件中的'eval_args'参数来进行检查。context model采用了'labeled'评测模式,general model采用了'full'评测模式,关于评测模式的详细介绍您可以参考我们的官方文档。
@Wicknight 当我设置 eval_args: {mode: 'labeled'} ,Evaluation时出现了 TypeError,用 ‘full mode’ 则不会出现
‘’‘
TypeError Traceback (most recent call last)
5 frames /usr/local/lib/python3.7/dist-packages/recbole/quick_start/quick_start.py in run_recbole(model, dataset, config_file_list, config_dict, saved) 55 # model training 56 best_valid_score, best_valid_result = trainer.fit( ---> 57 train_data, valid_data, saved=saved, show_progress=config['show_progress'] 58 ) 59
/usr/local/lib/python3.7/dist-packages/recbole/trainer/trainer.py in fit(self, train_data, valid_data, verbose, saved, show_progress, callback_fn) 350 if (epoch_idx + 1) % self.eval_step == 0: 351 valid_start_time = time() --> 352 valid_score, valid_result = self._valid_epoch(valid_data, show_progress=show_progress) 353 self.best_valid_score, self.cur_step, stop_flag, update_flag = early_stopping( 354 valid_score,
/usr/local/lib/python3.7/dist-packages/recbole/trainer/trainer.py in _valid_epoch(self, valid_data, show_progress) 207 dict: valid result 208 """ --> 209 valid_result = self.evaluate(valid_data, load_best_model=False, show_progress=show_progress) 210 valid_score = calculate_valid_score(valid_result, self.valid_metric) 211 return valid_score, valid_result
/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs) 25 def decorate_context(*args, **kwargs): 26 with self.clone(): ---> 27 return func(*args, **kwargs) 28 return cast(F, decorate_context) 29
/usr/local/lib/python3.7/dist-packages/recbole/trainer/trainer.py in evaluate(self, eval_data, load_best_model, model_file, show_progress) 473 ) 474 for batch_idx, batched_data in enumerate(iter_data): --> 475 interaction, scores, positive_u, positive_i = eval_func(batched_data) 476 if self.gpu_available and show_progress: 477 iter_data.set_postfix_str(set_color('GPU RAM: ' + get_gpu_usage(self.device), 'yellow'))
/usr/local/lib/python3.7/dist-packages/recbole/trainer/trainer.py in _neg_sample_batch_eval(self, batched_data) 422 elif self.config['eval_type'] == EvaluatorType.RANKING: 423 col_idx = interaction[self.config['ITEM_ID_FIELD']] --> 424 batch_user_num = positive_u[-1] + 1 425 scores = torch.full((batch_user_num, self.tot_item_num), -np.inf, device=self.device) 426 scores[row_idx, col_idx] = origin_scores
TypeError: 'NoneType' object is not subscriptable ’‘’
@evelyn023 您是否修改了其它yaml中的参数?context model默认的评测模式就是labeled,我这边无论是否加入mode: labeled都能够正常运行。
@Wicknight 我发现原因应该是我把 metrics 设成了 ['recall','ndcg'],所以context model是不支持这些metric的是吗?
@evelyn023 1.一般来说context-aware model主要应用于显式反馈场景来进行CTR预测,即拥有显式的正负标签,此时评测模式选用了'labeled', 但同时评价指标也理应使用'AUC','LogLoss'等value-based的指标,与评测模式保持一致。而general model主要应用于隐式反馈场景来进行完整排名 (full sort) ,此时评测模式是'full',评价指标使用‘ndcg’等ranking-based的指标来与其保持一致。您在这里是使用context model来做CTR预测任务,但却使用了ranking-based指标,并不一致。 2.RecBole 也支持通过与general model一样的完整排名 (full sort) 来评估 context-aware 推荐模型,但此时需要确保 .inter 文件不能加载任何其他上下文信息列,这种情况下模型可以用 Recall 等 ranking-based evaluation metrics 作为评测指标。您可以参考我们的文档中有关Context-aware Recommendation模型参数设置部分的说明。
@Wicknight 是这样的,我的实验目的是想要用训练模型得到每个user的topk recommendation items,但是好像没有可以得到context model的推荐列表的方法
- 同样的数据我用 labeled mode 训练FM auc可以达到0.9,用 full mode 训练的话recall就特别低,是否说明后者模型训练不佳?还是说训练结果是合理的,单纯因为评测指标的选择不合适所以没有办法提高recall?
- 但是我想要用
full-sort-topk获取推荐列表的话就只能用 full mode 吗,有没有其他方法
@evelyn023 1.如果配置没什么问题的话,训练结果应该也没问题,可能只是单纯效果不好。您也可以在其它数据集上来进行实验,观察是否存在这样的现象。 2.就像我之前回复中所说,context model最常用于CTR预测任务,如果您想使用full-sort-topk的话,只能使用full mode.
@Wicknight 我用full mode训练FM,试了好几天怎么训Recall@20还是很低,但同样的配置labeled mode训练auc就可以达到0.9,您方便看下我的配置和训练具体有什么问题吗,非常感谢! lfm360k.zip 里有我的原子文件和yaml文件
@evelyn023 您的yaml文件中并没有设置neg_sampling参数,这不太适用于隐式交互数据下的full评测模式,导致模型效果很差。下面是修改后的版本,也可根据您的需求自行设置neg_sampling参数。
data_path: /content
dataset: lfm360k
embedding_size: 64
normalize_all: True
neg_sampling:
uniform: 1
# Dataset hyper
field_separater: "\t"
seq__separater: " "
USER_ID_FIELD: user_id
ITEM_ID_FIELD: artist_id
RATING_FIELD: plays
TIME_FIELD: None
NEG_PREFIX: neg_
LABEL_FIELD: label
threshold:
plays: 70
load_col:
inter: [user_id, artist_id, plays]
item: [artist_id, totalplays, artist_gender]
# user: [user_id, gender, age, country]
user_inter_num_interval: "[20,inf)"
# Training hyper
epochs: 200
train_batch_size: 4096
learning_rate: 0.0005
eval_step: 20
stopping_step: 10
# Evaluation hyper
eval_args:
group_by: user
split: {'LS': 'valid_and_test'}
order: RO
mode: full
eval_batch_size: 102400
metrics: ['Recall', 'NDCG']
topk: 20
valid_metric: Recall@20