Significant performance drops in generated batched matrix multiplication kernels
Hi everyone,
I was testing some batched matrix multiplication kernels using HIP from ROCm 4.5.2, 5.1.0 and 5.1.3 suites. My target hardware is Mi200 i.e., gfx90a. The kernels themselves were generated with a python script. The multiplications took the following form: $A^{56, k} \cdot B^{k, 9}$, where $k \in [56, 55, 54, 53, 52, 51, 50, 49, 48]$. I used the outer product sum approach and unroll all the loops. Here is my obtained results.
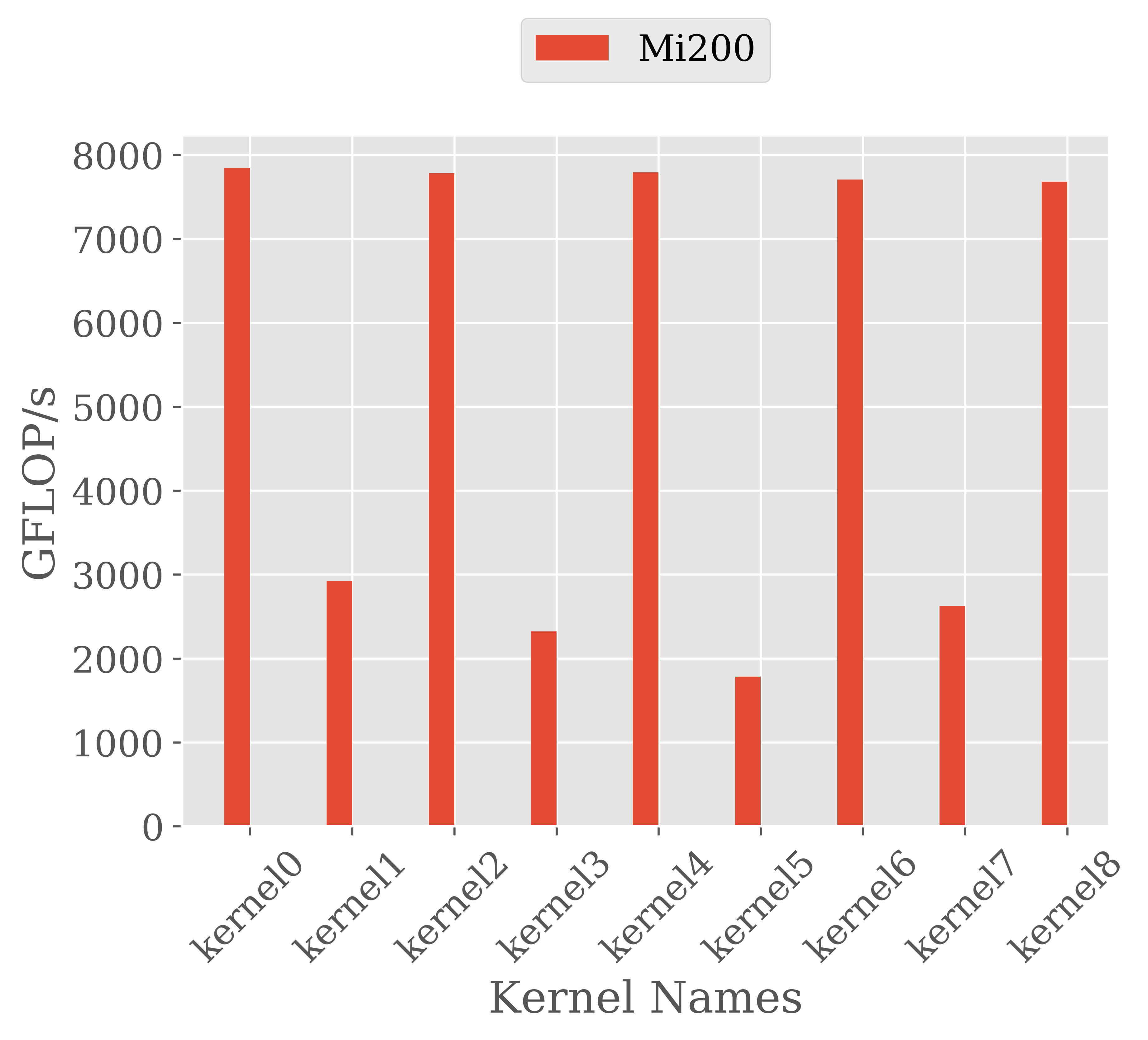
The performance significantly drops when $k \in [55, 53, 51, 49]$. In theory, $k$ is the contraction length which, in my case, determines the bounds of the outer-most loop and thus should not affect performance. However, it influences the total number of instructions.
Here is my source code: kernels.tar.gz
I suspect that something is wrong with the instruction scheduling. Could I ask somebody to have a look? For convenience, I am attaching the intermediate code as well. kernel-hip-amdgcn-amd-amdhsa-gfx90a.s.txt
Thank you in advance!