MONAI
 MONAI copied to clipboard
MONAI copied to clipboard
Auto3D Task Module 1 (DataAnalyzer) for #4743
Description
Implemented a DataAnalyzer class to encapsulate data analysis module. As the beginning part of the auto3d/automl pipeline, the module shall find data and label from user inputs and generate a summary (dictionary) of data stats. The summary includes - file names, list, number of files; - dataset summary (basic information, image dimensions, number of classes, etc.); - individual data information (spacing, image size, number and size of the regions, etc.). The summary can be exported as a YAML file and a dictionary variable for use in Python
Example Usage:
from monai.apps.auto3d.data_analyzer import DataAnalyzer
datalist = {
"testing": [{"image": "image_003.nii.gz"}],
"training": [
{"fold": 0, "image": "image_001.nii.gz", "label": "label_001.nii.gz"},
{"fold": 0, "image": "image_002.nii.gz", "label": "label_002.nii.gz"},
{"fold": 1, "image": "image_001.nii.gz", "label": "label_001.nii.gz"},
{"fold": 1, "image": "image_004.nii.gz", "label": "label_004.nii.gz"},
],
}
dataroot = '/datasets' # the directory where you have the image files (in this example we're using nii.gz)
analyser = DataAnalyzer(datalist, dataroot)
datastat = analyser.get_all_case_stats() # it will also generate a data_stats.yaml that saves the stats
Status
Ready for Review Reference issue https://github.com/Project-MONAI/MONAI/issues/4743.
Types of changes
- [x] Non-breaking change (fix or new feature that would not break existing functionality).
- [x] New tests added to cover the changes.
- [ ] Integration tests passed locally by running
./runtests.sh -f -u --net --coverage. - [x] Quick tests passed locally by running
./runtests.sh --quick --unittests --disttests. - [ ] In-line docstrings updated.
- [ ] Documentation updated, tested
make htmlcommand in thedocs/folder.
thanks, there are some style issues reported, I think some of them are valid ones... https://deepsource.io/gh/Project-MONAI/MONAI/run/96404a6f-933e-4971-b866-f170efb1d4b9/python/
Thanks @wyli . Still ramping up myself on the the MONAI style coding. I will fix those.
Hi @mingxin-zheng @dongyang0122 @wyli ,
I think the current pipeline can only work for 3D segmentation, should we call the module "auto3d_seg" or "auto_seg_3d"?
Thanks.
thanks, there are some style issues reported, I think some of them are valid ones... https://deepsource.io/gh/Project-MONAI/MONAI/run/96404a6f-933e-4971-b866-f170efb1d4b9/python/
Most style issues are fixed now except two pending (https://deepsource.io/gh/Project-MONAI/MONAI/run/0422e6b3-e5b3-4830-9cd3-f460969470b0/python/PYL-W0106)
Demo of the module is added to the tutorial PR. Hope that will help the review @wyli @Nic-Ma @dongyang0122 . Thanks!
https://github.com/mingxin-zheng/tutorials/blob/auto3d-1.0/auto3d/auto3d.ipynb
thanks, I tried the analyzer it's very convenient, please see some comments inline.. is it possible to add some support for the 'image' only inputs? https://github.com/Project-MONAI/MONAI/issues/4824
Thanks! Do you mean only images, no label?
thanks, I tried the analyzer it's very convenient, please see some comments inline.. is it possible to add some support for the 'image' only inputs? #4824
Thanks! Do you mean only images, no label?
Yes, requirements as described in #4824
thanks, I tried the analyzer it's very convenient, please see some comments inline.. is it possible to add some support for the 'image' only inputs? #4824
Thanks! Do you mean only images, no label?
Yes, requirements as described in #4824
I added some implementations in b8d91e41394acae73967001b6b32e040cda81195 to enable an argument "image_only" with a simple unit test to address the feature request in Auto3D. For a more integrated version, let's open another PR to (1) move the data analyzer out of apps and deprecate current dataset summary (2) test the image_only option for all use cases @wyli
I added some implementations in b8d91e4 to enable an argument "image_only" with a simple unit test to address the feature request in Auto3D. For a more integrated version, let's open another PR to (1) move the data analyzer out of apps and deprecate current dataset summary (2) test the image_only option for all use cases @wyli
many thanks, I run:
python -m monai.apps.auto3d DataAnalyzer get_all_case_stats --datalist=my_list.json --image_only=True
it works nicely...
Hi @mingxin-zheng ,
Could you please help move the module to "MONAI/monai/auto3dseg" according to the internal discussion?
Thanks in advance.
Hi @mingxin-zheng ,
Could you please help move the module to "MONAI/monai/auto3dseg" according to the internal discussion?
Thanks in advance.
Thanks @Nic-Ma . Moved it in commit e38585d24a53f52f8c13a34b3e5d65330e3b40de
Hi @mingxin-zheng ,
Thanks for the update. Please also update the README file: https://github.com/Project-MONAI/MONAI/blob/dev/monai/README.md And signoff the commits to pass the DCO. Others look good to me.
Thanks.
Hi @mingxin-zheng ,
Thanks for the update. Please also update the README file: https://github.com/Project-MONAI/MONAI/blob/dev/monai/README.md And signoff the commits to pass the DCO. Others look good to me.
Thanks.
Updated the readme in commit 5359741362cc40052fc243a236a60b428969d55. Thanks!
Sorry I'm a bit confused here, I think we agreed to have monai.apps.auto3dseg not monai.auto3dseg In the upcoming version. The api flexibility still needs to be improved and that we decide don't do it in the upcoming version.
Below is workflow diagram of the dataAnalyzer, including the internal function inputs & outputs
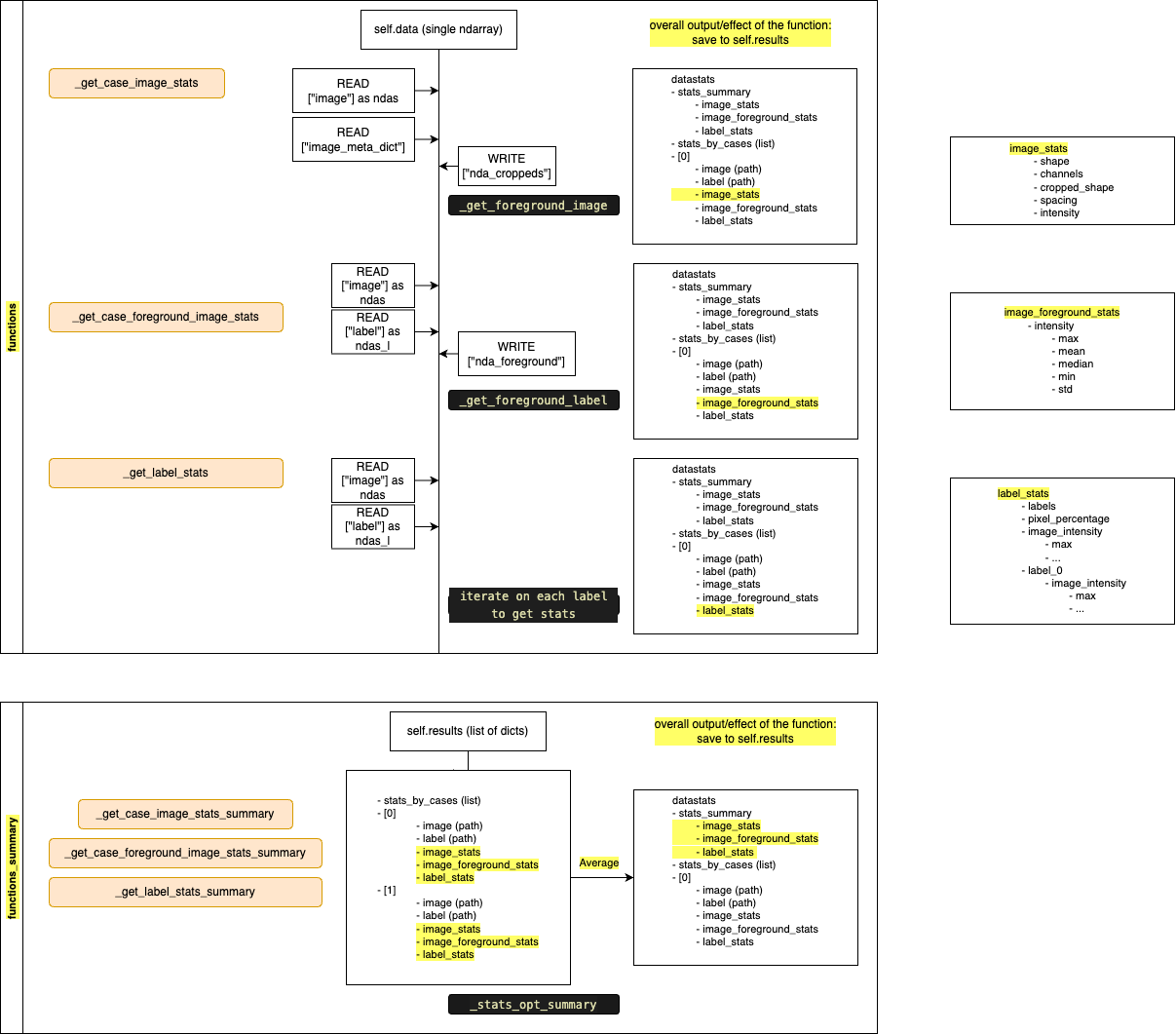
Hi @mingxin-zheng ,
Thanks for the clear XML chart for initial discussion of the design. According to our initial thinking, I put together some draft code, just for the further discussion and reference. Mainly include 3 levels abstraction: (1) AnalyzeEngine (2) Analyzer (3) Operations
# Base class for every analyzer function in the engine, I think it can be subclass of MONAI transform, return the report
class Analyzer(MapTransform, ABC):
# refer to: https://github.com/automl/auto-sklearn/blob/development/scripts/02_retrieve_metadata.py#L123
report_schema: dict = {}
def get_report_schema(self) -> dict:
return self.report_schema
def verify_report(self, report: dict):
# refer to: https://github.com/Project-MONAI/MONAI/blob/dev/monai/bundle/scripts.py#L433
return jsonschema.validate(report, self.get_report_schema())
@abstractmethod
def __call__(self, data: dict) -> dict:
"""Analyze the dict format dataset, return the summary report"""
raise NotImplementedError(f"Subclass {self.__class__.__name__} must implement this method.")
class ImageAnalyzer(Analyzer):
report_schema: dict = {
"type": "object",
"shape": {
"type": "array",
"items": {"type": "number"},
},
"channels": {"type": "integer"},
"crop_shape": {
"type": "array",
"items": {"type": "number"},
},
"spacing": {
"type": "array",
"items": {"type": "number"},
},
"intensity": {
"type": "array",
"items": {"type": "number"},
},
}
def __init__(self, keys, allow_missing_keys=False) -> None:
super().__init__(...)
def __call__(self, data: dict) -> dict:
...
class LabelAnalyzer(Analyzer):
report_schema: dict = {...}
def __init__(self, keys, allow_missing_keys=False) -> None:
super().__init__(...)
def __call__(self, data: dict) -> dict:
...
class ForegroundImageAnalyzer(Analyzer):
report_schema: dict = {...}
def __init__(self, keys, allow_missing_keys=False) -> None:
super().__init__(...)
def __call__(self, data: dict) -> dict:
...
class ImageSummaryAnalyzer(Analyzer):
report_schema: dict = {...}
def __init__(self, keys, allow_missing_keys=False) -> None:
super().__init__(...)
def __call__(self, data: dict) -> dict:
...
...
# Base class of operations, operations should be a set of callable APIs and the associated names
class Operations(UserDict):
# actually, no need this function, just to show the use case here!
def update(self, op: dict[str, callable]):
super().update(op)
def evaluate(self, data: Any) -> dict:
return {k: v(data) for k, v in self.data.items()}
class ImageOperations(Operations):
def __init__(self) -> None:
self.data = {
"max": max,
"mean": mean,
"median": median,
"min": min,
"percentile": partial(percentile, q=np.array([0.5, 10, 90, 99.5])),
"stdev": std,
}
class ImageSummmaryOperations(Operations):
def __init__(self) -> None:
self.data = {
"max": max,
"mean": mean,
"median": mean,
"min": min,
"percentile_00_5": mean,
"percentile_99_5": mean,
"percentile_10_0": mean,
"percentile_90_0": mean,
"stdev": mean,
}
# The overall engine to execute analysis for a dataset based on the registered analyzers
class AnalyzeEngine:
def __init__(self, data: dict) -> None:
self.data = data
self.analyzers: dict = {}
def update(self, analyzer: dict[str, callable]):
self.analyzers.update(analyzer)
def __call__(self):
return {k: analyzer(self.data) for k, analyzer in self.analyzers.items() if callable(analyzer)}
# Our specific implementation of the dataset analysis for 3D segmentation
class SegAnalyzeEngine(AnalyzeEngine):
def __init__(self, data: dict) -> None:
transform = Compose([
LoadImaged(keys=keys),
EnsureChannelFirstd(keys=keys), # this creates label to be (1,H,W,D)
Orientationd(keys=keys, axcodes="RAS"),
EnsureTyped(keys=keys, data_type="tensor"),
])
super().__init__(data=transform(data))
super().update({
"image_stats": ImageAnalyzer(keys=...),
"label_stats": LabelAnalyzer(...)
...
})
Please feel free to share your ideas. Once the design in this PR is in a good shape, let's involve more members to review and discuss.
Thanks in advance.
I think the Analyzer logic could be part of the transform? this will benefit from the multiprocessing data loader, e,g:
transform = Compose([
LoadImaged(keys=keys),
EnsureChannelFirstd(keys=keys), # this creates label to be (1,H,W,D)
Orientationd(keys=keys, axcodes="RAS"),
EnsureTyped(keys=keys, data_type="tensor"),
ImageSummaryAnalyzer(keys=keys),
])
summary_across_cases([per_case_stat for per_case_stat in dataloader(batch_size=1, num_workers=4, transform)])
we could also consider a map-reduce style design given that the implementation has self.functions and self.functions_summary, but I'm not sure if it's good for code readability...
Hi @wyli ,
Thanks for your feedback.
I think we have several registered analyzers the AnalyzeEngine, not only ImageSummaryAnalyzer(keys=keys), and the output is report dicts instead the original data dict, so we can't chain them together with transforms.
Anyway, maybe I misunderstand your idea, open for further discussion.
Thanks.
I think the Analyzer logic could be part of the transform? this will benefit from the multiprocessing data loader, e,g:
transform = Compose([ LoadImaged(keys=keys), EnsureChannelFirstd(keys=keys), # this creates label to be (1,H,W,D) Orientationd(keys=keys, axcodes="RAS"), EnsureTyped(keys=keys, data_type="tensor"), ImageSummaryAnalyzer(keys=keys), ]) summary_across_cases([per_case_stat for per_case_stat in dataloader(batch_size=1, num_workers=4, transform)])we could also consider a map-reduce style design given that the implementation has
self.functionsandself.functions_summary, but I'm not sure if it's good for code readability...
Thanks @Nic-Ma . The logic is pretty close to what we had sorted out but there are a few issues. I have the three layers (Operation, Analyzer and AnalyzeEngine) plus a ReportSchema which replaces the dict with ConfigParser.
I think the Analyzer logic could be part of the transform? this will benefit from the multiprocessing data loader, e,g:
transform = Compose([ LoadImaged(keys=keys), EnsureChannelFirstd(keys=keys), # this creates label to be (1,H,W,D) Orientationd(keys=keys, axcodes="RAS"), EnsureTyped(keys=keys, data_type="tensor"), ImageSummaryAnalyzer(keys=keys), ]) summary_across_cases([per_case_stat for per_case_stat in dataloader(batch_size=1, num_workers=4, transform)])we could also consider a map-reduce style design given that the implementation has
self.functionsandself.functions_summary, but I'm not sure if it's good for code readability...
Thanks @wyli for the comment. I though about this and another critical issue is that some analyzer works not only on the data from dataloader, but could also works on list type object such as the output from previous analyzer in the pipeline. I may need to think more about this but it seems difficult at the moment
Sure, my main idea is that if the operations are applied independently to each input item in a dataset, these could be done in the transform of a dataloader, this will benefit from the multiprocessing/thread loader. Essentially to accelerate this for loop: https://github.com/Project-MONAI/MONAI/blob/22080cb34905c839e8a29d33489cbf43210256f1/monai/apps/auto3dseg/data_analyzer.py#L719
It's fine if for each item the analyser transfor's output is a structured report. In the summary stage we can make summary over the structures.
Thanks for the quick update.
I would suggest to split the stats_collector.py into several python files and a utils.py file, you can refer to the monai/bundle module structure:
https://github.com/Project-MONAI/MONAI/tree/dev/monai/bundle
Thanks.
The code is under refactoring, and the status switch back to WIP
Thanks for the quick update. I would suggest to split the
stats_collector.pyinto several python files and autils.pyfile, you can refer to themonai/bundlemodule structure: https://github.com/Project-MONAI/MONAI/tree/dev/monai/bundleThanks.
Thanks for the suggestion. I broke it down into smaller scripts in fix 6b2f99dd82edf25244de56ecd72bd6bc5a1c395c and subsequent commits
Update: refractoring is near its end. Doc-strings / type def / units tests for the new classes are pending