blog
 blog copied to clipboard
blog copied to clipboard
Bloom Filter 简介
Bloom Filter 是由 Bloom 在 1970 年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求 100% 正确的场合。
它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom Filter 是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter 的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter 不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter 通过极少的错误换取了存储空间的极大节省。
适用场景
- 黑名单
- 爬虫重复URL检测
- 字典纠缠
- 磁盘文件检测
- CDN(squid)代理缓存技术
以爬虫重复 URL 举例:
假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成 “环”。为了避免形成 “环”,就需要知道蜘蛛已经访问过那些 URL。给一个 URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案:
-
将访问过的 URL 保存到数据库。
-
用 HashSet 将访问过的URL保存起来。那只需接近 O(1) 的代价就可以查到一个 URL 是否被访问过了。
-
URL 经过 MD5 或 SHA-1 等单向哈希后再保存到 HashSet 或数据库。
-
Bit-Map方法。建立一个 BitSet,将每个 URL 经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。
以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
-
方法 1 的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
-
方法 2 的缺点:太消耗内存。随着 URL 的增多,占用的内存会越来越多。就算只有 1 亿个 URL,每个 URL 只算 50 个字符,就需要 5GB 内存。
-
方法 3:由于字符串经过MD5处理后的信息摘要长度只有 128Bit,SHA-1 处理后也只有 160Bit,因此方法3比方法2节省了好几倍的内存。128Bit = 16 字节,散列表(hash table) 的存储效率一般只有 50%,因此一个 URL 要占用 32字节,一亿个地址需要占用 3.2 GB,存储几十亿个地址就需要上百 GB ,一般的服务器是存不下的。
-
方法 4 消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的 Hash表冲突的各种解决方法么?若要降低冲突发生的概率到 1%,就要将 BitSet 的长度设置为 URL 个数的 100 倍。
实质上上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要 100% 准确!也就是说少量 URL 实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
方法四的致命缺点是冲突概率高,为了降低冲突的概念,Bloom Filter 使用了 多个哈希函数(Hash Function),而不是一个。
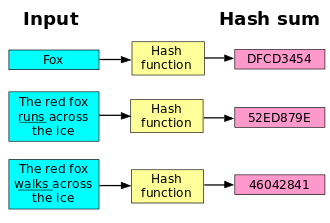
Hash Function(散列函数 又称 散列算法、哈希函数)
在讲到 Bloom Filter 算法 之前,不得不提一下 哈希函数。
哈希函数不是指某种特定的函数,而是一类函数,它有各种各样的实现。
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表(Hash table,也叫哈希表)和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
特性
- 定义里面讲的是哈希函数接收任意长度的输入,但在实际实现中,大家都会指明一个具体可接收的阈值,例如SHA-2最高接受(2^64-1)/8长度的字节字符串。此处需要理解的是哈希函数拥有较为庞大的输入值域,它 接受长度非常长的输入值。
- 产生固定长度的输出值。
- 不可逆性,已知哈希函数fn与x的哈希值无法反向求出x,当然这里的 不可逆是指计算上行不通,正着算很好算,反着算在当前的计算机计算能力条件下做不到。
- 对于特定的哈希函数,只要 输入值不变,那么输出的值也是唯一不变的。
- 哈希函数的 计算时间不应过长,即通过输入值求出输出值的时间不宜过长。
- 无冲突性,即对于输入值x,与哈希函数fn,无法求出一个值y,使得x与y的哈希值相等。但是由于上文我们知道,由于哈希函数实际上代表着一种映射(对应关系),将一个大区间上的数值映射到一个小区间上,它一定是有冲突的,这里的无冲突同样是指 “求冲突在计算上行不通” ,正向地计算很容易,但是反向的计算在当前的计算机能力条件下做不到,但是这种冲突的概率发生了怎么办我们后面再说。
- 即使修改了输入值的一个比特位,也会使得输出值发送巨大的变化。
- 哈希函数产生的映射应当保持均匀,即不要使得映射结果堆积在小区间的某一块区域。
常用hash生成方法
常用的散列函数构造有7种方法:
- 直接定址法
- 数字分析法
- 平方取中法
- 除留余数法
- 相乘取整法
- 伪随机数法
- 折叠法
直接寻址法
取关键字或关键字的某个线性函数值为散列地址。
即Hash(key) = key 或Hash(key) = a * key + b,其中 a,b 为常数。
数字分析法
分析一组数据,比如某班学生的出生年月日发现出生年月日的前几位数字大体相同,这样的话,冲突的几率会很大,但是发现年月日的后几位表示月份和具体日期的数字差别较大,如果用后几位构成散列地址,则冲突的几率会明显降低。因此数字分析法是找出数字的规律,尽可能利用这些数字构造冲突几率低的散列地址。
平方取中法
具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得 (0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)。
相应的散列函数用C实现很简单:
int Hash(int key){ //假设key是4位整数
key *= key;
key /= 100; //先求平方值,后去掉末尾的两位数
return key % 1000; //取中间三位数作为散列地址返回
}
除余法
该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key)=key%m 该方法的关键是选取 m。选取的 m 应使得散列函数值尽可能与关键字的各位相关。m 最好为素数。
【例】若选 m 是关键字的基数的幂次,则就等于是选择关键字的最后若干位数字作为地址,而与高位无关。于是高位不同而低位相同的关键字均互为同义词。
【例】若关键字是十进制整数,其基为10,则当m=100时,159,259,359,…,等均互为同义词。
相乘取整法
该方法包括两个步骤:首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整。即:
该方法最大的优点是选取m不再像除余法那样关键。比如,完全可选择它是2的整数次幂。虽然该方法对任何A的值都适用,但对某些值效果会更好。
该函数的C代码为:
int Hash(int key){
double d=key *A; //不妨设A和m已有定义
return (int)(m*(d-(int)d));//(int)表示强制转换后面的表达式为整数
}
随机数法
选择一个随机函数,取关键字的随机函数值为它的散列地址,即:h(key) = random(key)
其中 random 为伪随机函数,但要保证函数值是在 0 到 m-1 之间。
折叠法
将关键字分割成位数相同的几个部分(最后一部分位数可以不同),然后取这几个部分的叠加和(舍弃进位)作为哈希地址。
关键字位数很多,而且关键字中每一位数字分布大致均匀时,可以采用折叠法。
处理hash冲突
哈希函数是指如何对关键字进行编址的,这里的关键字的范围很广,可视为无限集,如何保证无限集的原数据在编址的时候不会出现重复呢?规则本身无法实现这个目的。
再哈希法
当散列表较满时,冲突增加,插入可能失败。于是建立另外一个大约两倍大的散列表(而且使用新的散列函数),扫描原来散列表,计算每个未删除元素的新的散列值,并将其插入到新表中。
缺点:这是非常昂贵的操作,运行时间O(N),不过再散列不是经常发生,实际效果没那么差。
链地址法
将所有关键字为同义词的记录存储在同一线性链表中。如下:

建立一个公共溢出区(比较常见于实际操作中)
假设哈希函数的值域为 [0,m-1] ,则设向量 HashTable[0..m-1] 为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。
经过以上方法,基本可以解决掉hash算法冲突的问题。
还有许多用于散列表的方法,比如散列函数不好或装填因子过大,都会使堆积现象加剧。为了减少堆积的发生,不能像线性探查法那样探查一个顺序的地址序列(相当于顺序查找),而应使探查序列跳跃式地散列在整个散列表中。衍生出二次探查法,双重散列表法。
衍生阅读:HashMap 的实现原理
Bloom Filter 算法
Bloom Filter算法如下:
创建一个 m 位 BitSet,先将所有位初始化为 0,然后选择 k 个不同的哈希函数。第 i 个哈希函数对字符串str 哈希的结果记为 h(i,str),且h(i,str)的范围是 0 到 m-1 。

初始化时,Bloom Filter是一个包含 m 位的位数组,每一位都置为 0
加入元素过程
下面是每个元素处理的过程,首先是将元素str “记录” 到 BitSet 中的过程:
对于元素 str,分别计算 h(1,str),h(2,str)…… h(k,str)。然后将 BitSet 的第h(1,str)、h(2,str)…… h(k,str)位设为1。原先为1的保持为1,为 0 设置为 1。

Bloom Filter 加入字符串过程,将字符串映射到 BitSet 中 K 个二进制位了
检查元素串是否属于集合的过程
对于元素 str,分别计算对 str 进行 k 次哈希函数,h(1,str),h(2,str)…… h(k,str)。如果BitSet的第h(1,str)、h(2,str)…… h(k,str)位都是 1 ,则可以认为 str 是集合中的元素。

Bloom Filter加入检测是否包含过程;y1 不属于,y2 属于(存在 false positive 情况)
伪代码
public class BloomFilter{
private bit[] bitSet = new bit[N];
public void add(Object element){
int[] hashValues = getHashValues(element);
for(int i : hashValues){
bitSet[i] = 1;
}
}
public boolean contains(Object element){
int[] hashValues = getHashValues(element);
for(int i : hashValues){
if(bitSet[i] != 1) return false;
}
return true;
}
}
那么问题来了,Bloom Filter 的错误率如何估算?哈希函数个数如何计算?位数组的初始大小如何计算?
计算过程参考
既然 Bloom Filter 要靠多个哈希函数将集合映射到位数组中,那么应该选择几个哈希函数才能使元素查询时的错误率降到最低呢?这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到 0 的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的 0 就多。
哈希函数个数 k、位数组大小 m、加入元素数量 n 的关系可以参考 Bloom Filters - the math。该文献证明了对于给定的 m、n,当 k = ln(2)* m/n 时出错的概率是最小的。

错误率公式
一般在 位数组给到 集合的 10 倍时,k 选 7 个 hash 函数,错误率在 0.00819 左右;其他倍数、和错误率的对应关系可以参考 Bloom Filters - the math 给的对应表格。

总结
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter 在时间空间这两个因素之外又引入了另一个因素:错误率。在使用 Bloom Filter 判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter 通过允许少量的错误来节省大量的存储空间。
Bloom Filter 的实现过程已经非常简单了,唯一的计算在于伪随机散列函数的计算上;google guava 里面的 bloom 过滤器源码里面提到如何用更少的 Hashing 计算实现同样效果,具体见 Adam Kirsch and Michael的论文 Less Hashing, Same Performance:Building a Better Bloom Filter
参考
- Bloom Filter 概念和原理
- 哈希碰撞与生日攻击
- BloomFilter原理,实现及优化
- Python3网络爬虫开发实战
- Bloom Filters - the math
- Hash Functions and Block Ciphers