关于训练,第三阶段中途测试结果比第二阶段测试效果差是什么原因?
我训练第二阶段测试结果是这样的:
 第三阶段训练测试得到这样的结果:
第三阶段训练测试得到这样的结果:
 这明显比第二阶段差很多,这是什么原因呢?
我分割数据集采用的是(768,432)像素大小图像,并且也是采用的代码合成图的方式:分为fgr、bgr(分割用的其实就是抠像的低分辨率数据集),会不会和这个有关系呢,
抠像小分辨率是(768,432),高分辨率是(3840,2160)以及(1920,1080),他们属于一个数据集,只是分辨率不同
这是我在tensorboard查看的训练真实alpha以及预测alpha展示图:
真实alpha:
这明显比第二阶段差很多,这是什么原因呢?
我分割数据集采用的是(768,432)像素大小图像,并且也是采用的代码合成图的方式:分为fgr、bgr(分割用的其实就是抠像的低分辨率数据集),会不会和这个有关系呢,
抠像小分辨率是(768,432),高分辨率是(3840,2160)以及(1920,1080),他们属于一个数据集,只是分辨率不同
这是我在tensorboard查看的训练真实alpha以及预测alpha展示图:
真实alpha:
 预测的alpha:
预测的alpha:

为什么你的alpha背景是白色前景是黑色?不应该背景黑色前景白色吗?
我训练的背景,而非前景,我把前景预测注释掉了(前面测试过可以得到不错的结果,这里的数据集采用代码外合成,就是没有fgr图像,直接是合成图),后续增加了数据集,我将分割数据集(这里使用抠像高分辨率数据集)以及抠像数据集全部采用代码动态合成的方式加载(依旧没有前景预测),目的增加数据多样性,这样反而得到了不好的效果,我不太能看懂tensorboard里面的loss曲线,因为他不是下降趋势,感觉一直在稳定状态,请您分析一下:
1.前景预测影响有多大,由于我是通过训练背景获取alpha,反转可以得到我想要的前景alpha,这里前景预测就相当于预测我真实数据的背景,后续用不上就去掉了,因为我是在特定纯色场景抠像,前景比背景复杂的多)
2.下面是我的loss图:(这里没有设置阶段四,因为数据集制作原因,阶段四、阶段三使用相同视频数据集,第一阶段loss中途死机,所以有两份)
阶段一:
图像分割损失:
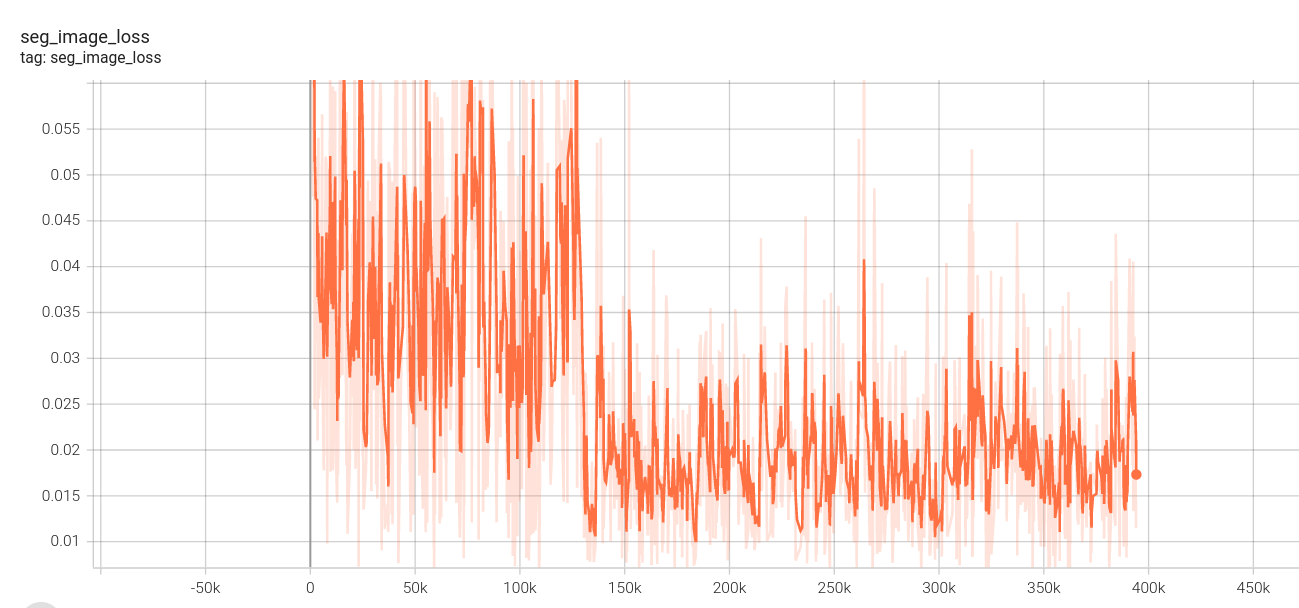
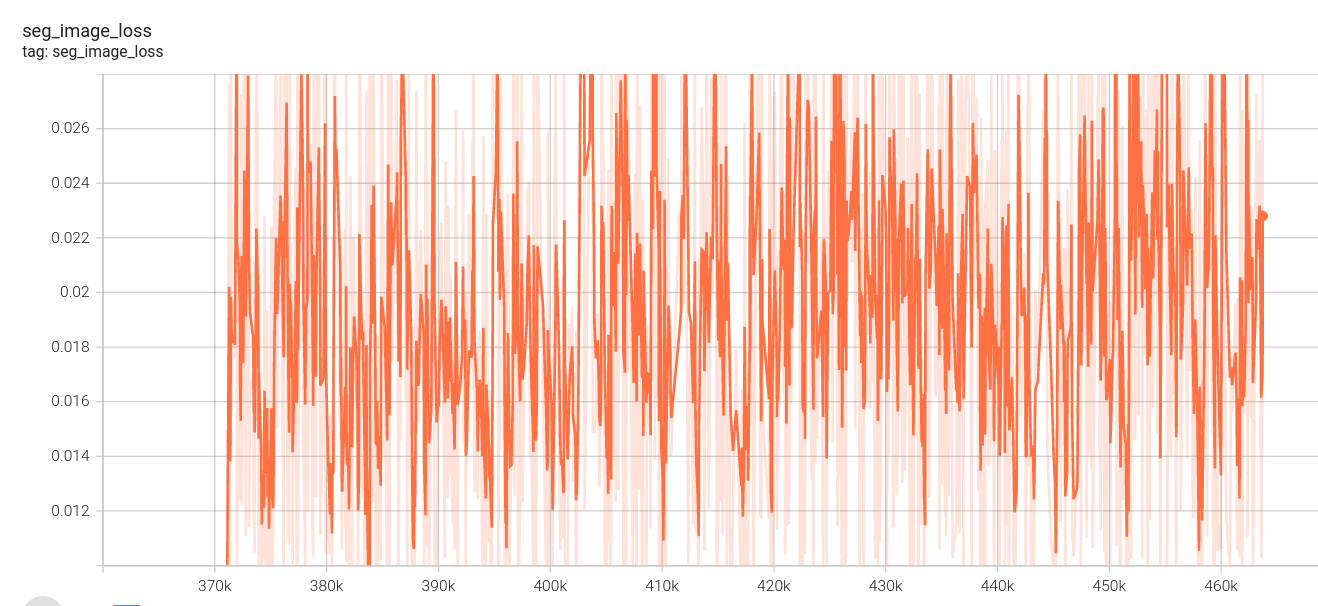
视频分割损失:
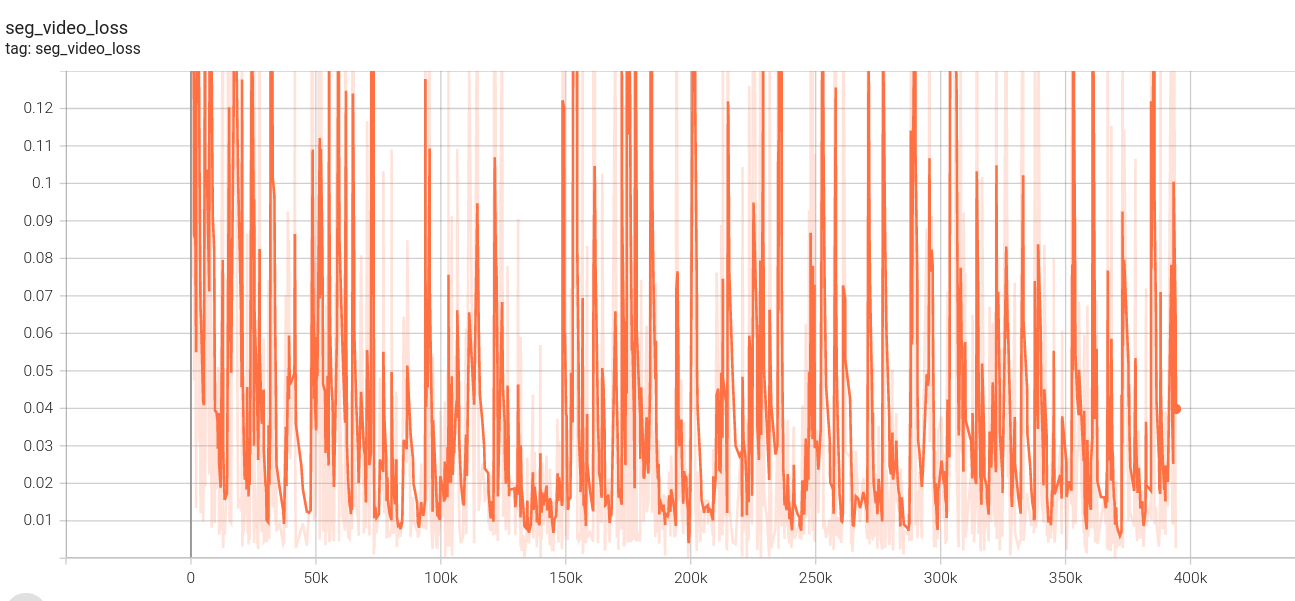
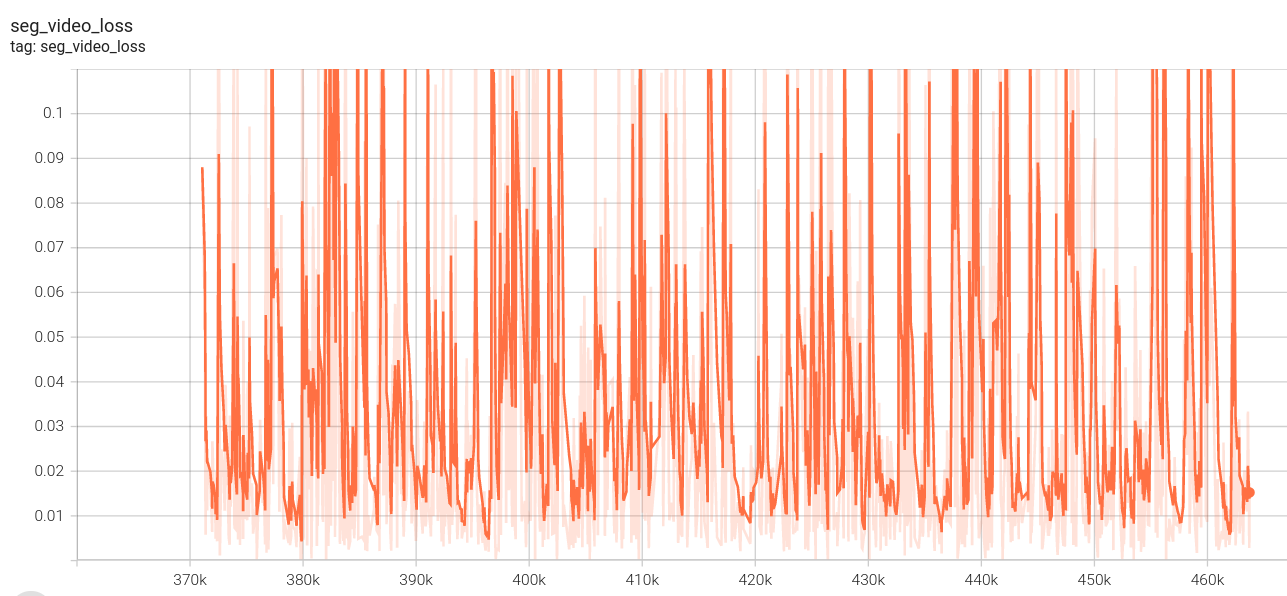
序列损失:
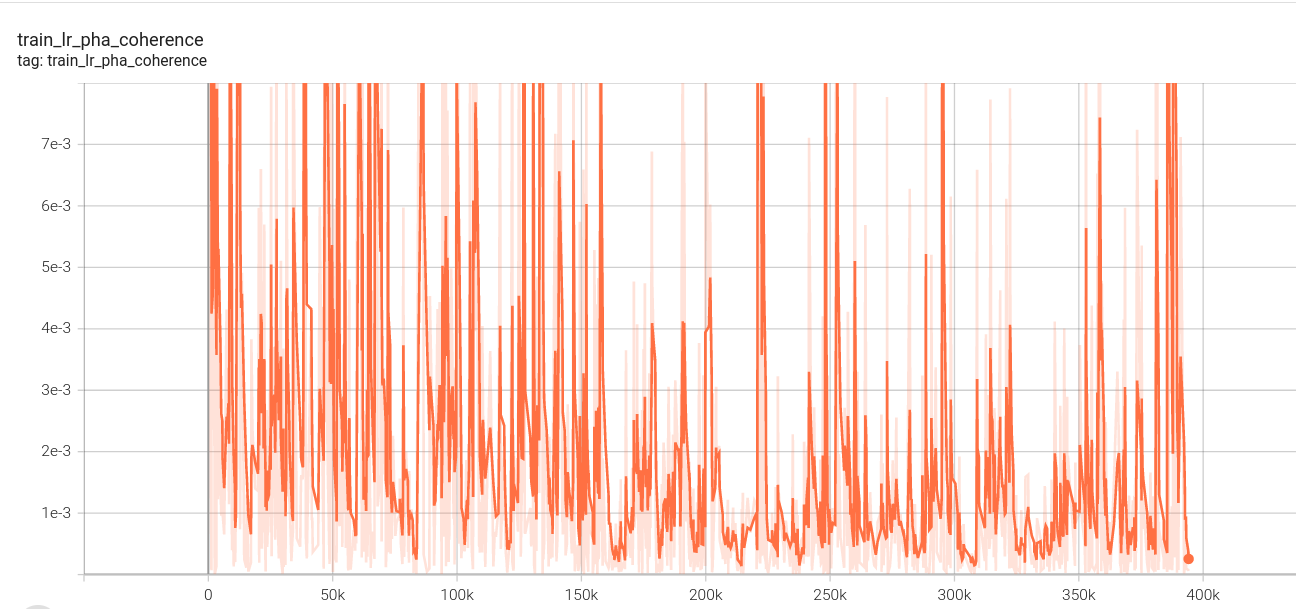
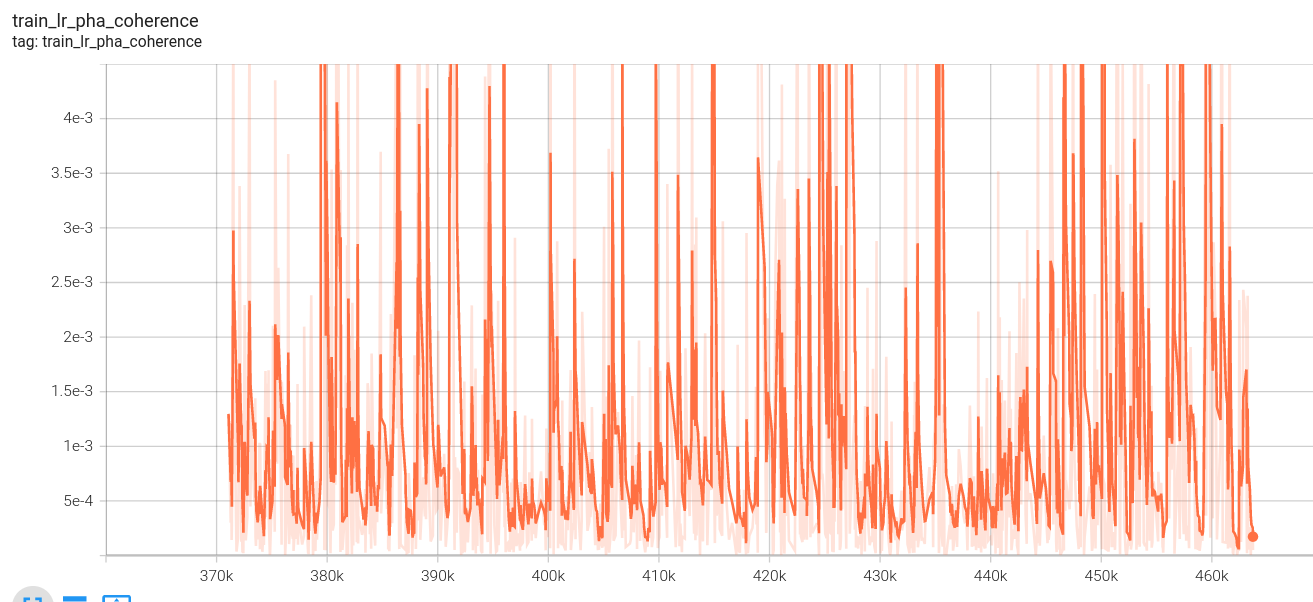
l1损失:
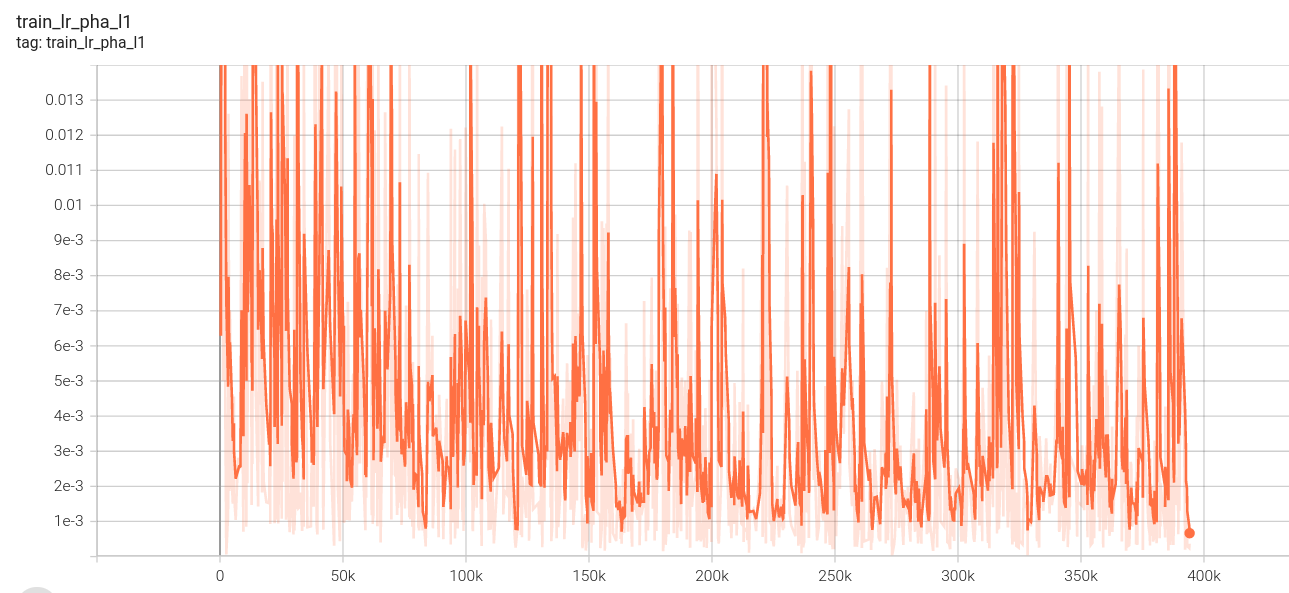
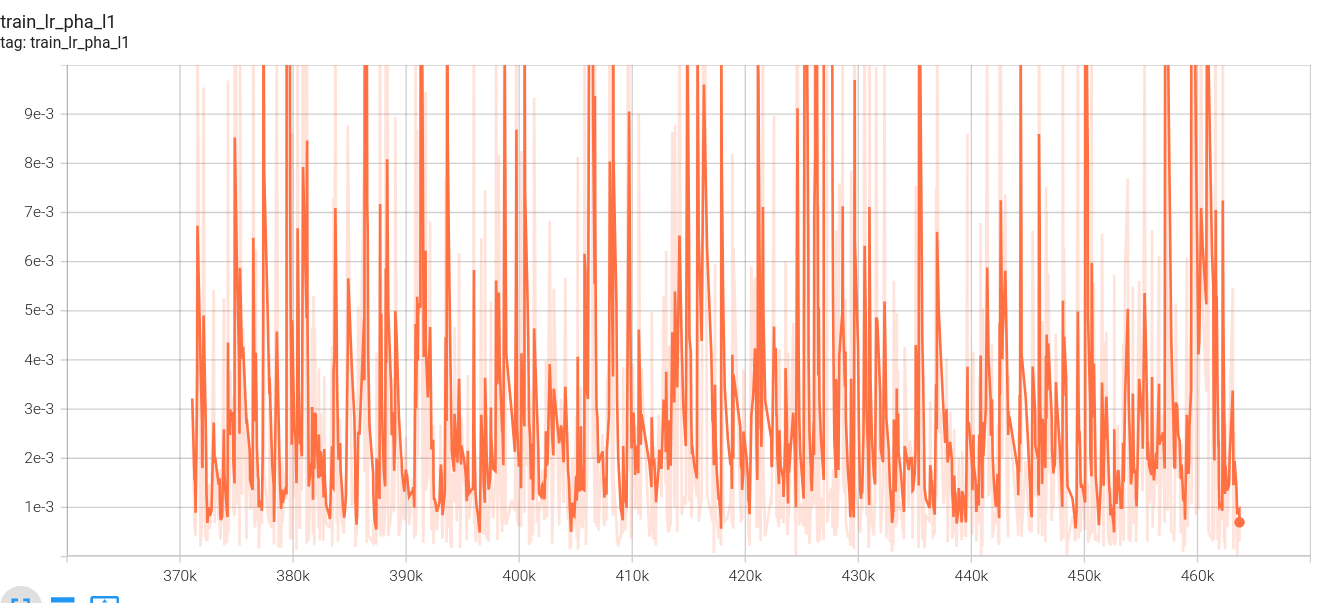
金字塔损失:
总损失:
阶段二:
图像分割损失:
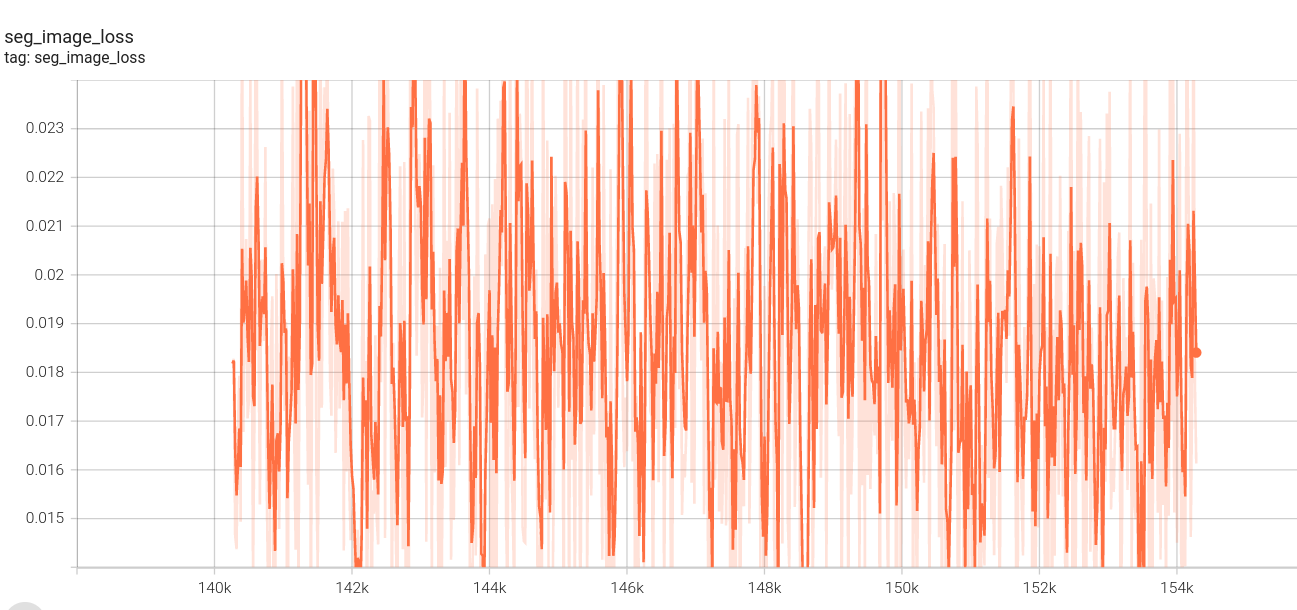
视频分割损失:
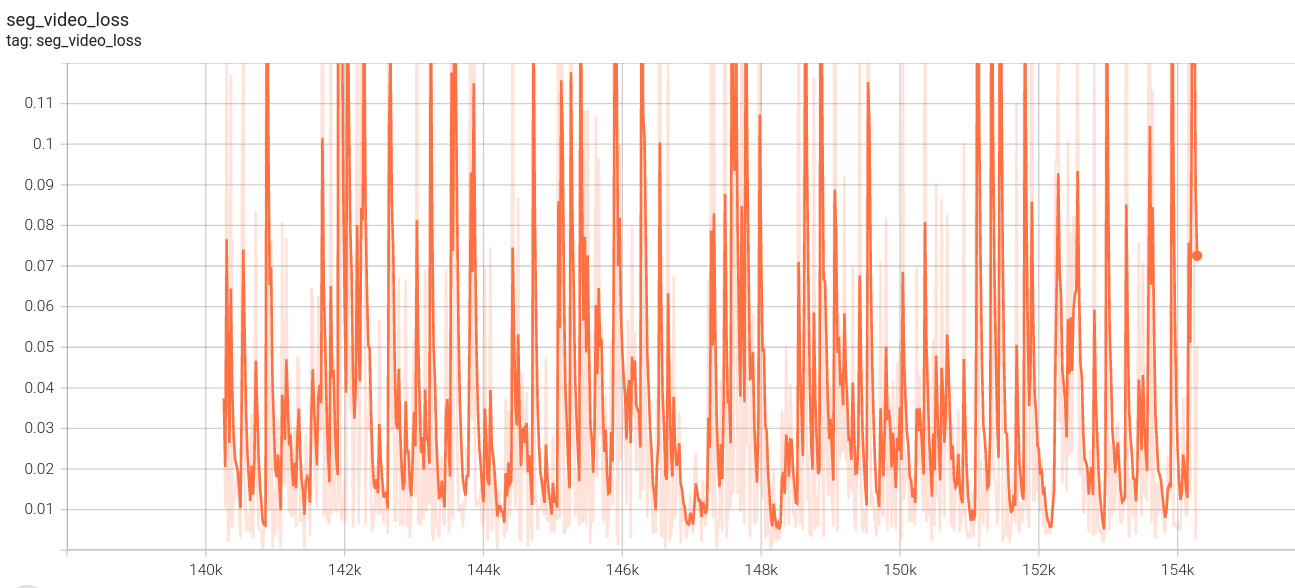
序列损失:
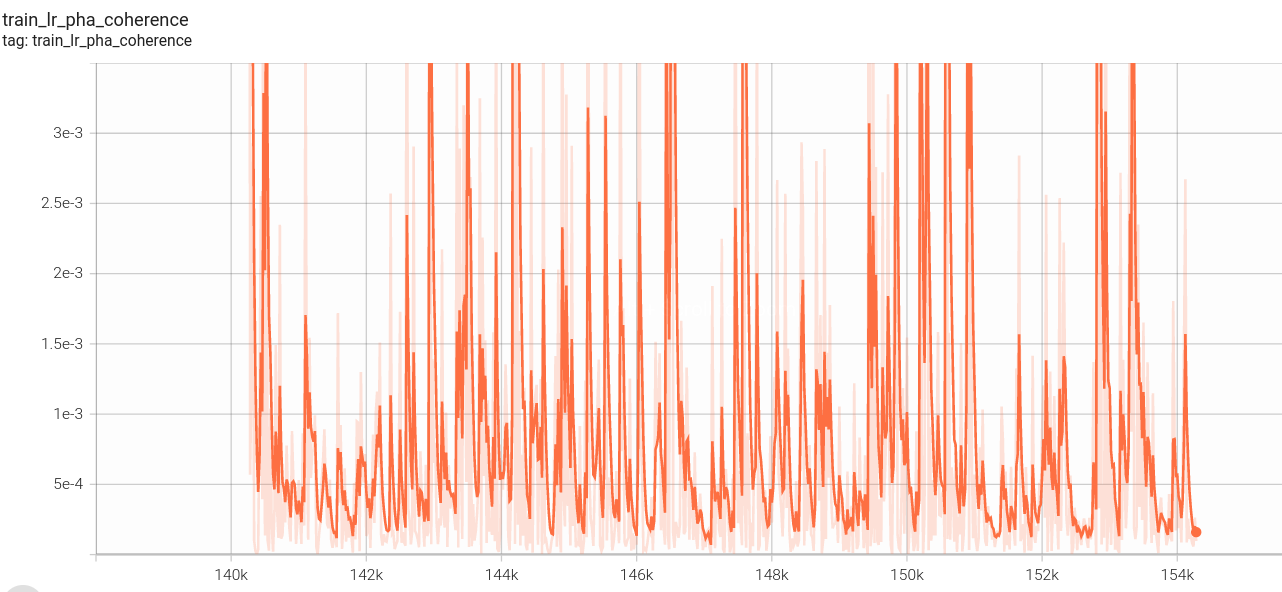
l1损失:
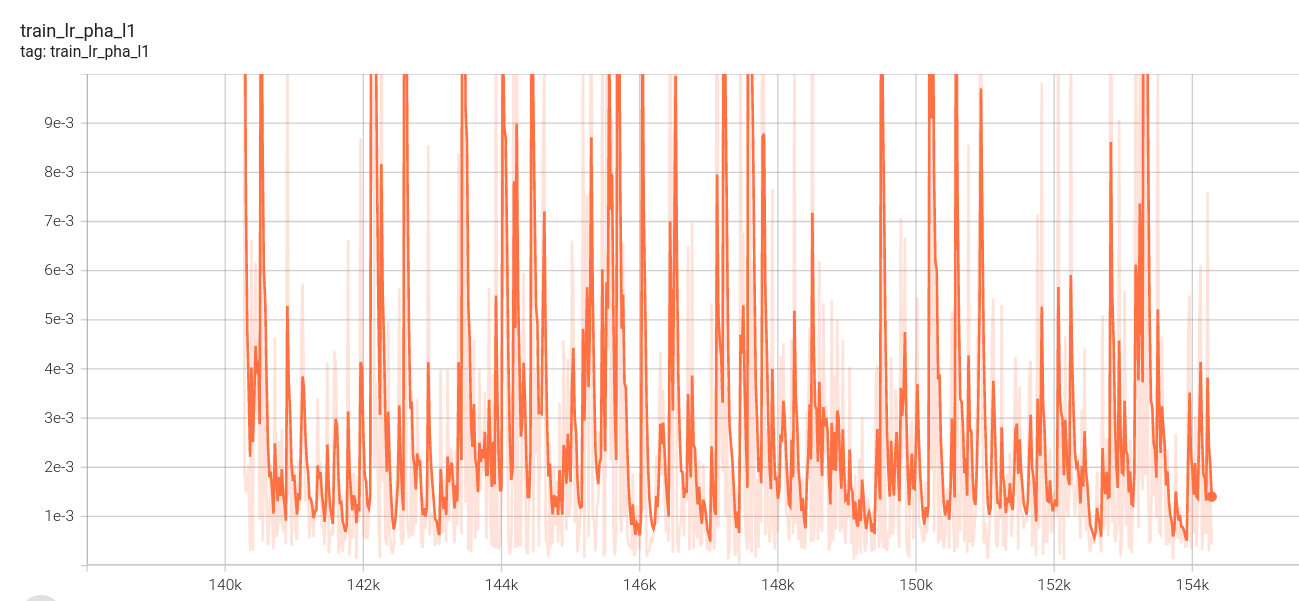
金字塔损失:
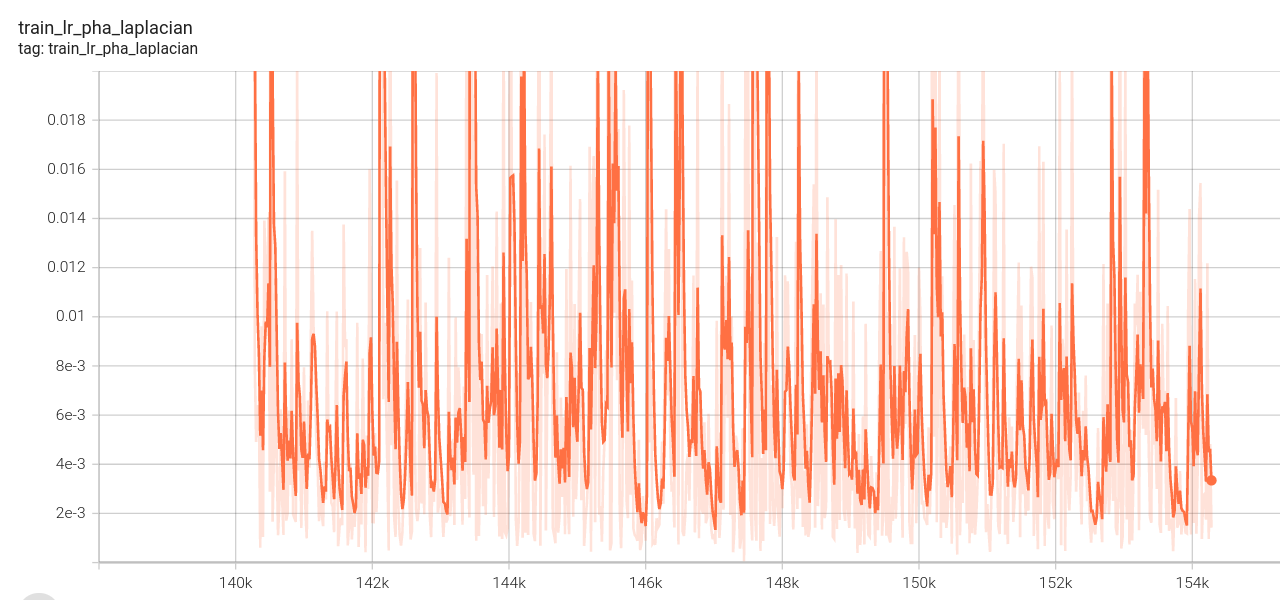
总损失:
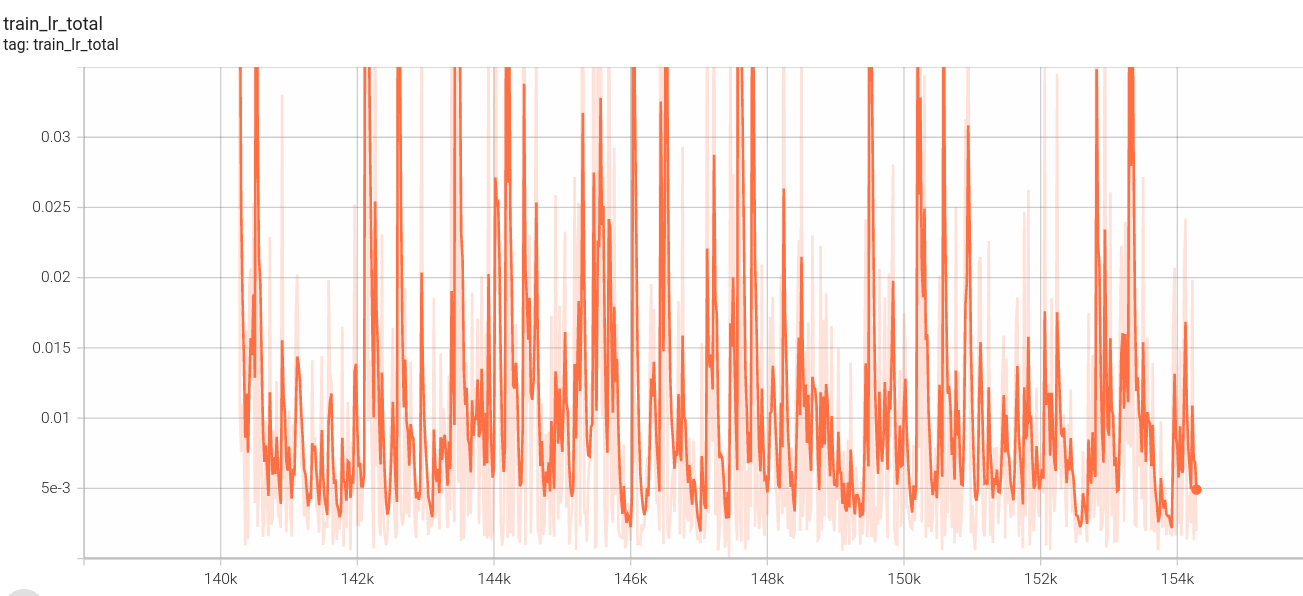
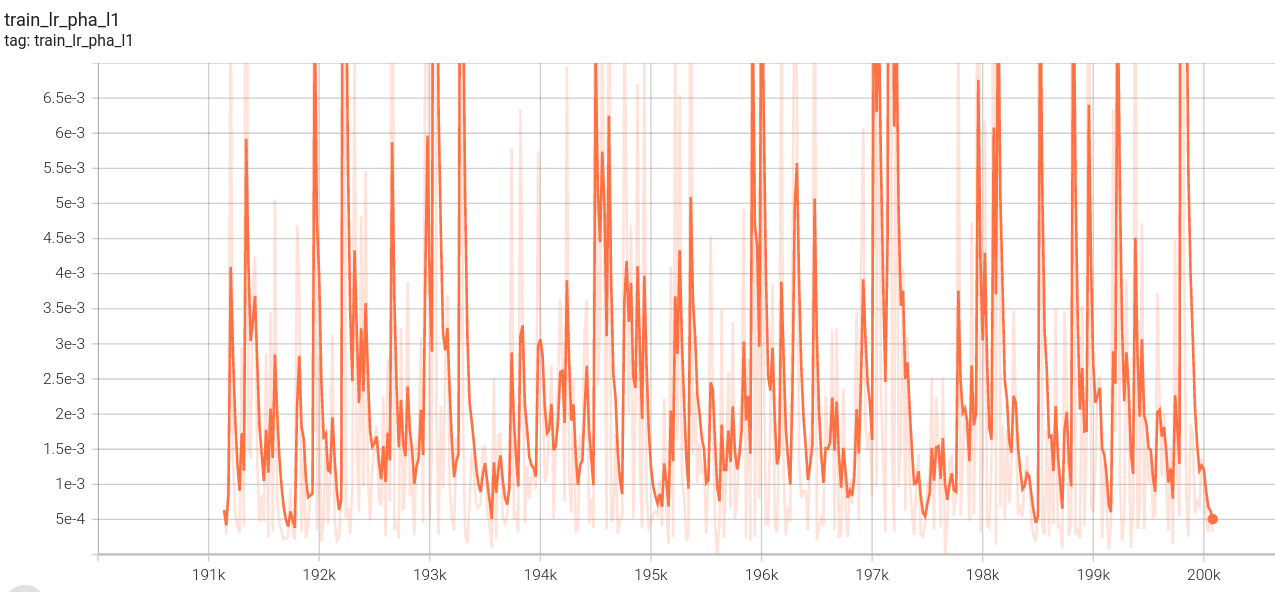
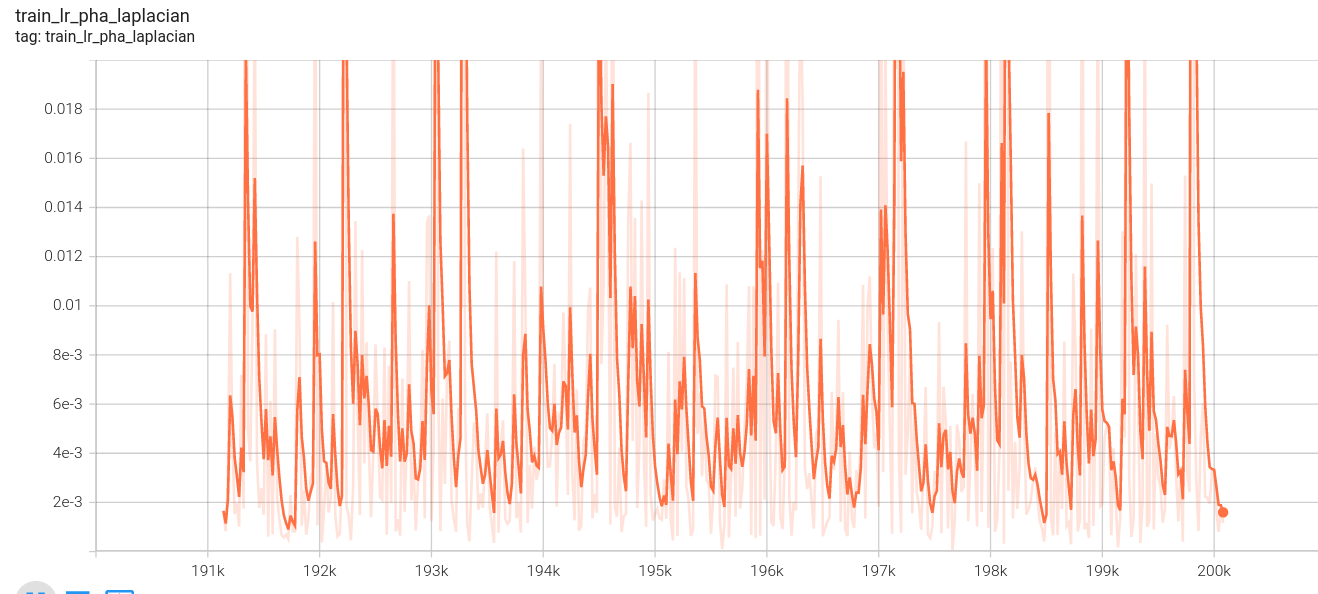
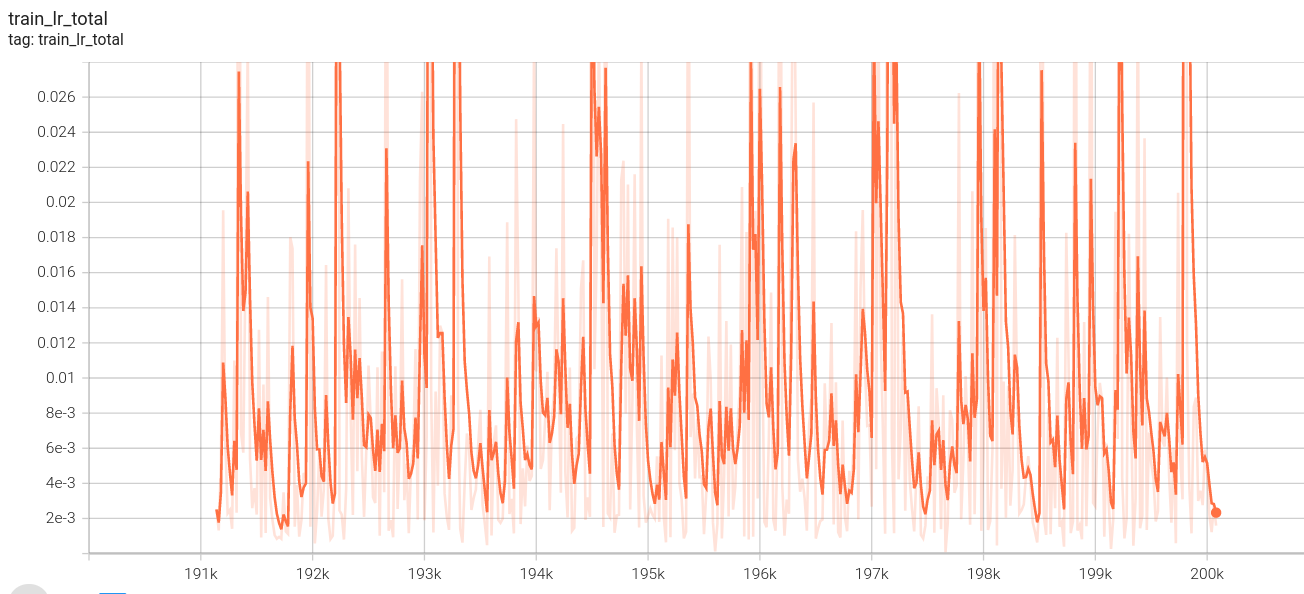
阶段三:
图像分割损失:
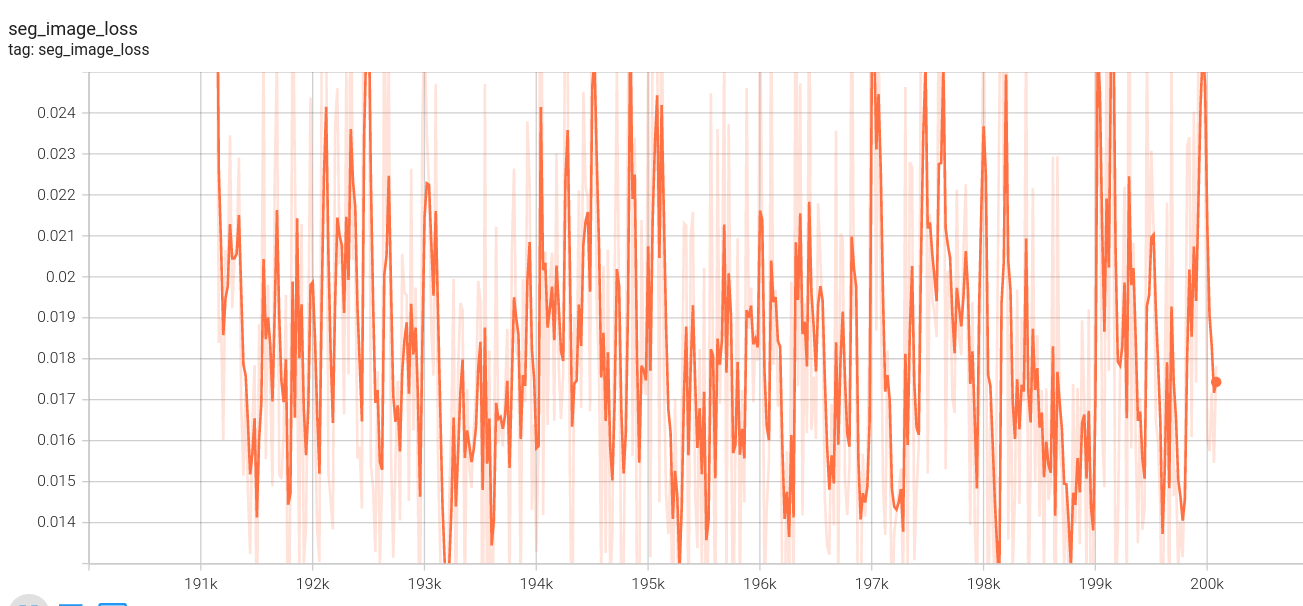
视频分割损失:
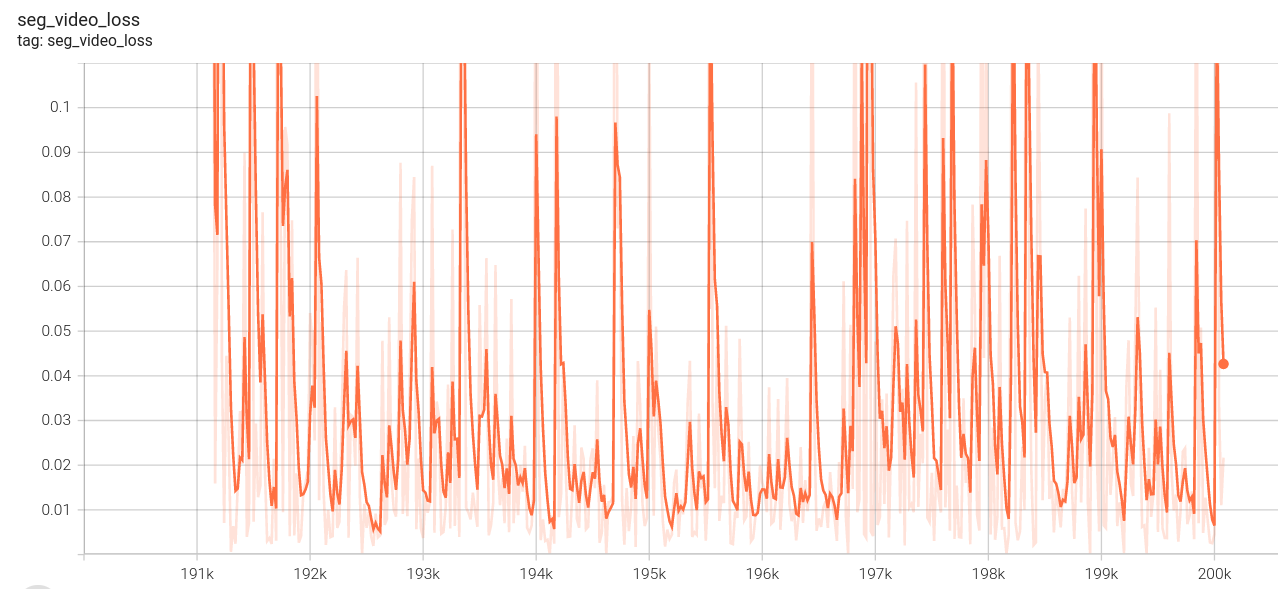
低分辨率序列损失:
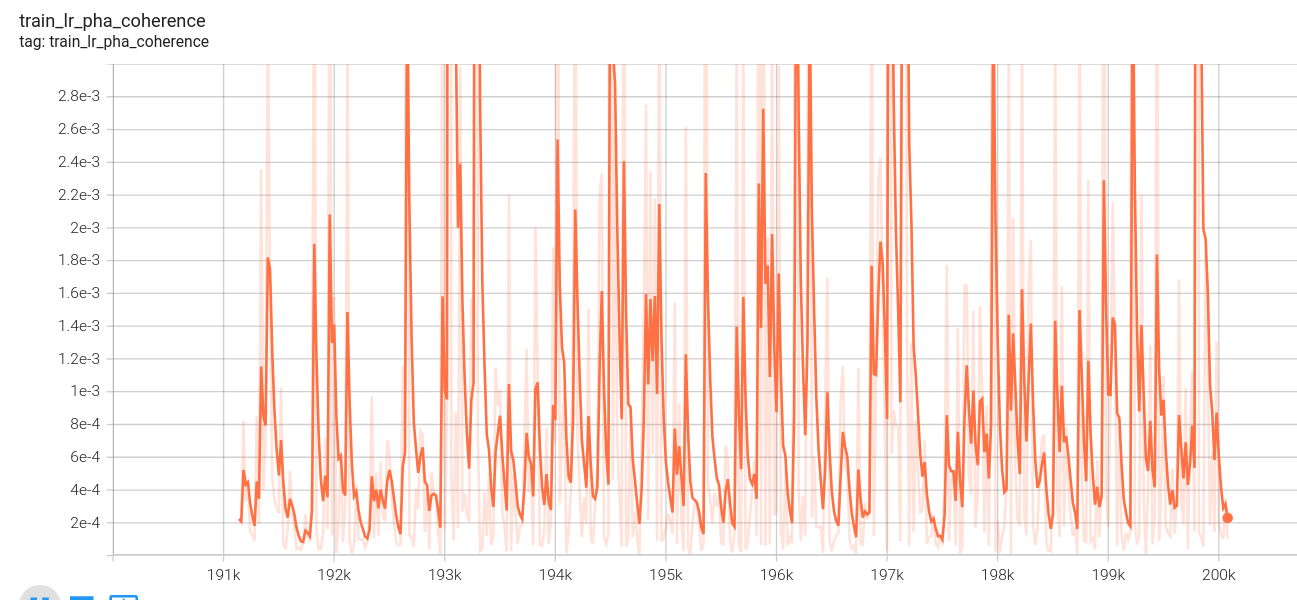
低分辨率l1损失:
低分辨率金字塔损失:
低分辨率总损失:
高分辨率序列损失:
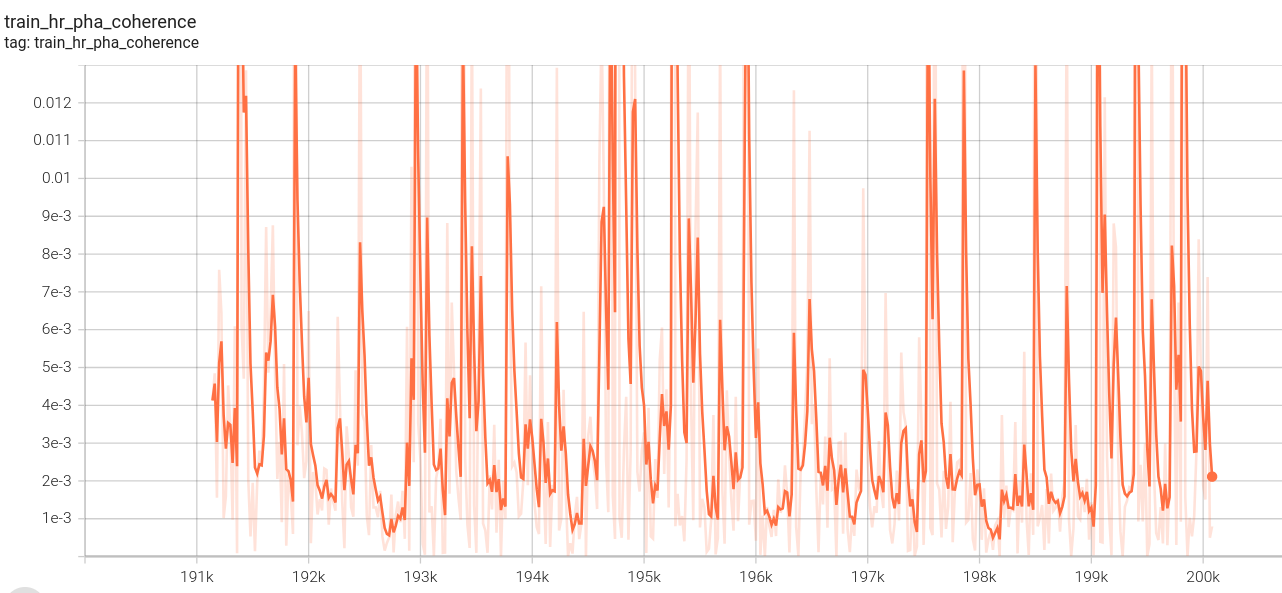
高分辨率l1损失:
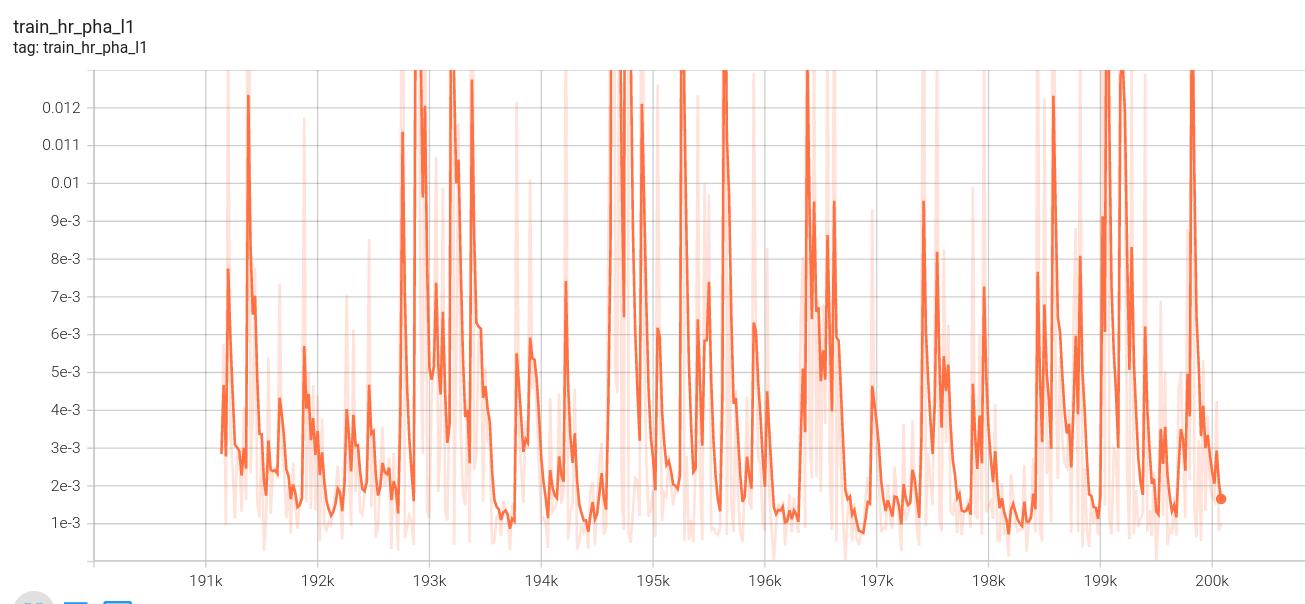
高分辨率金字塔损失:
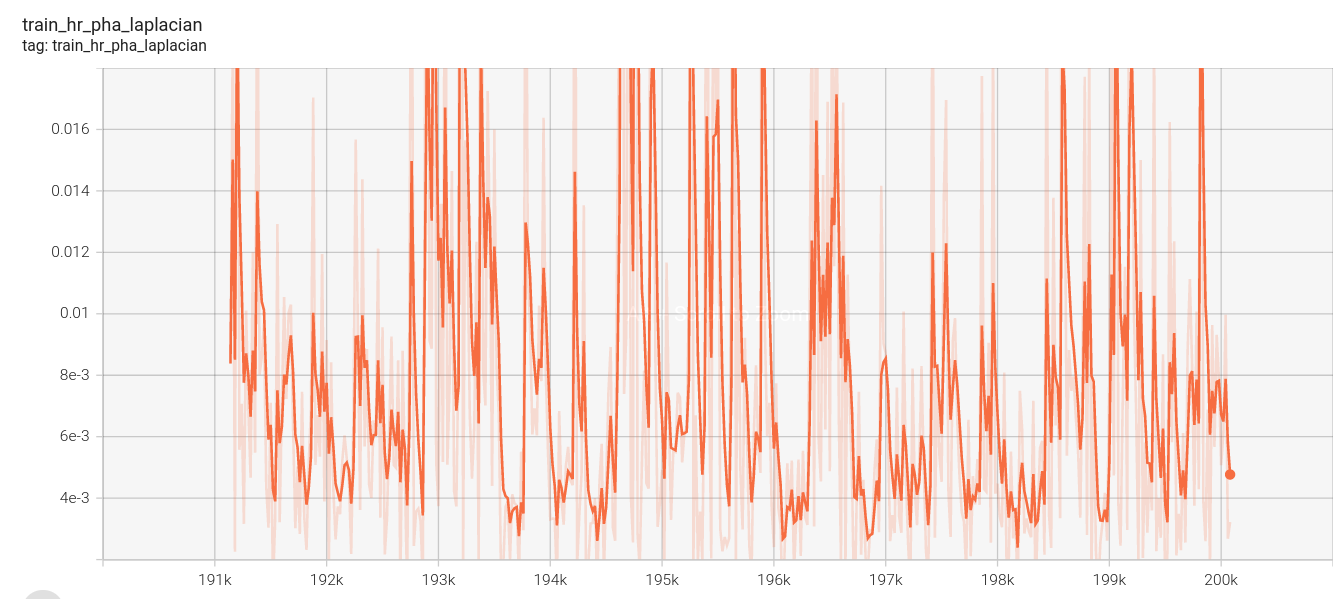
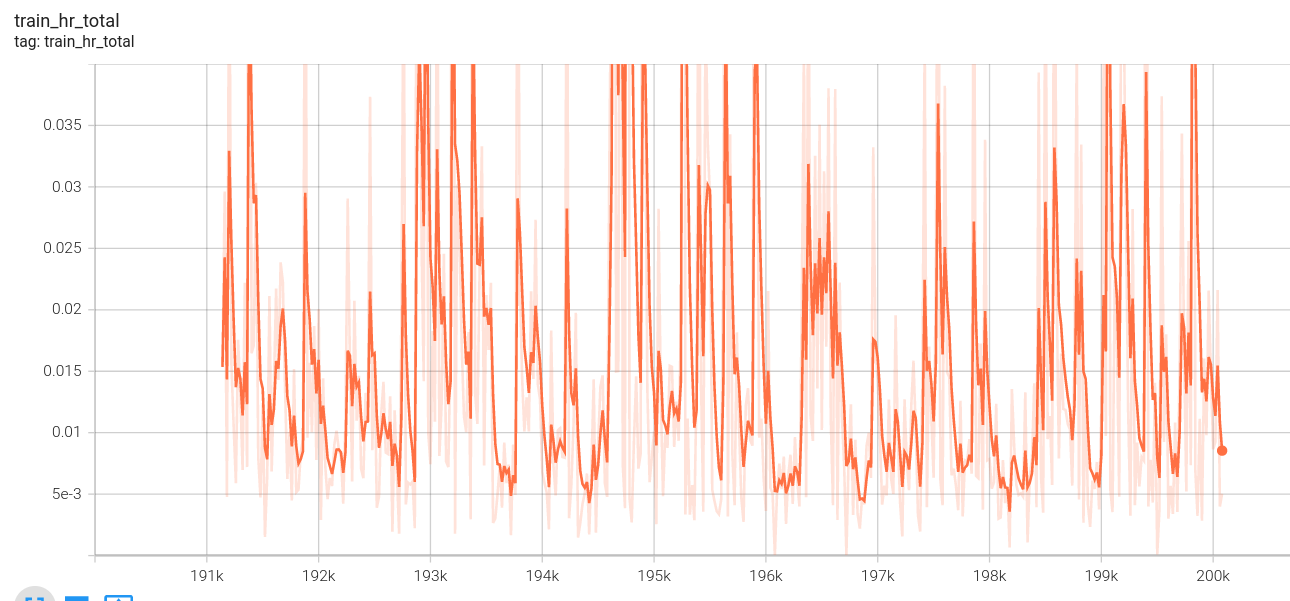
高分辨率总损失:
请问他有个背景数据集没有公开怎么能训练呀 Image Backgrounds Train set: We crawled 8000 suitable images from Google and Flicker. We will not publish these images.
请问他有个背景数据集没有公开怎么能训练呀 Image Backgrounds Train set: We crawled 8000 suitable images from Google and Flicker. We will not publish these images.
可以自己找一些背景图片,根据给定的一些关键词。