zero-blog
 zero-blog copied to clipboard
zero-blog copied to clipboard
用户输入 url 并按下回车(一)
1. 用户输入 url 并按下回车
一般的 URL(统一资源定位符) 可能会包含如下:
- 协议 scheme 如
http,https,等。 - 服务器名称(
域名/子域名)或IP地址。 -
路径或文件。
以下根据 scheme 为 http/https,起始请求文件为 html ,且不考虑部署 CDN 的情况下进行分析。
2. DNS lookup
DNS 域名解析,优先级如下:
本地 hosts -> DNS 代理服务器 -> DNS 服务器
查找方式:
-
递归式,发出封包后只等待正确响应解析结果。 -
迭代式,发出封包后等待下一个查询地址,然后发送封包到返回的查询地址,直至返回正确解析结果。
解析结果即域名对应真实 IP 地址。
3. 建立 TCP/IP 连接,三次握手,开始请求数据帧。
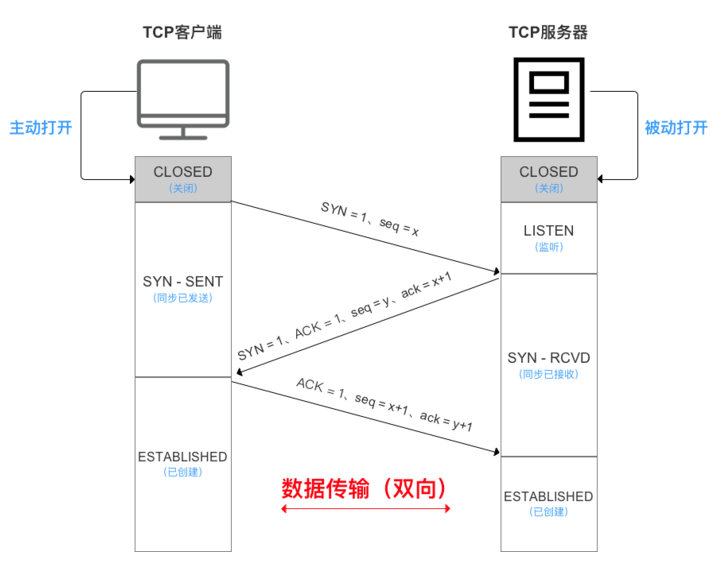
拿到域名对应 IP 后,浏览器准备请求 html 资源文件,如果在本地有相关缓存,根据缓存字段来进行强缓存还是协商缓存(后续会有图片提到)。
一般来说前端项目的 html 资源文件都进行 cache-control: no-cache/no-store ,每次都向服务器请求最新,这时候就发起与目标服务器的链接,假设我们是 http请求,开始三次握手(SYN 包),服务器处理请求返回 html 字节流,4次挥手发送 FIN 包,由此不难看出 TCP 效率很慢,而 TCP 却有很多优点:
-
面向链接:使用 TCP 传输数据前,必须先建立 TCP 链接,传输完成后在释放链接。 -
面向字节流:流入流出的字符序列。 -
全双工通信:建立 TCP 链接后,通信双方都能发送数据。 -
可靠:通过 TCP 链接传送的数据,不丢失,无差错,不重复且按序到达。
为什么需要三次握手
防止服务器端因接受了早已失效的连接请求报文,从而一直等待客户端请求,最终形成死锁,浪费资源。
为什么需要四次挥手?
为了保证通信双方都能通知对方当前需要释放资源,断开连接。
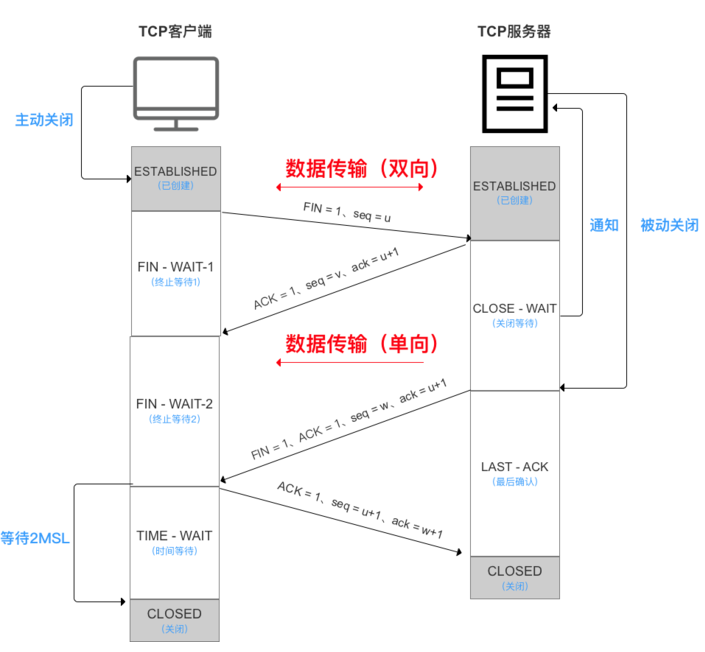
为什么客户端关闭需要等待2MSL时间?
确保服务器关闭连接,释放资源前不会存在失效的请求报文。
其他相关原理(发送窗口,接受窗口,慢启动,加法增大,sshrefresh,拥挤窗口等) https://www.jianshu.com/p/65605622234b
4. 请求 HTML,进行词法分析
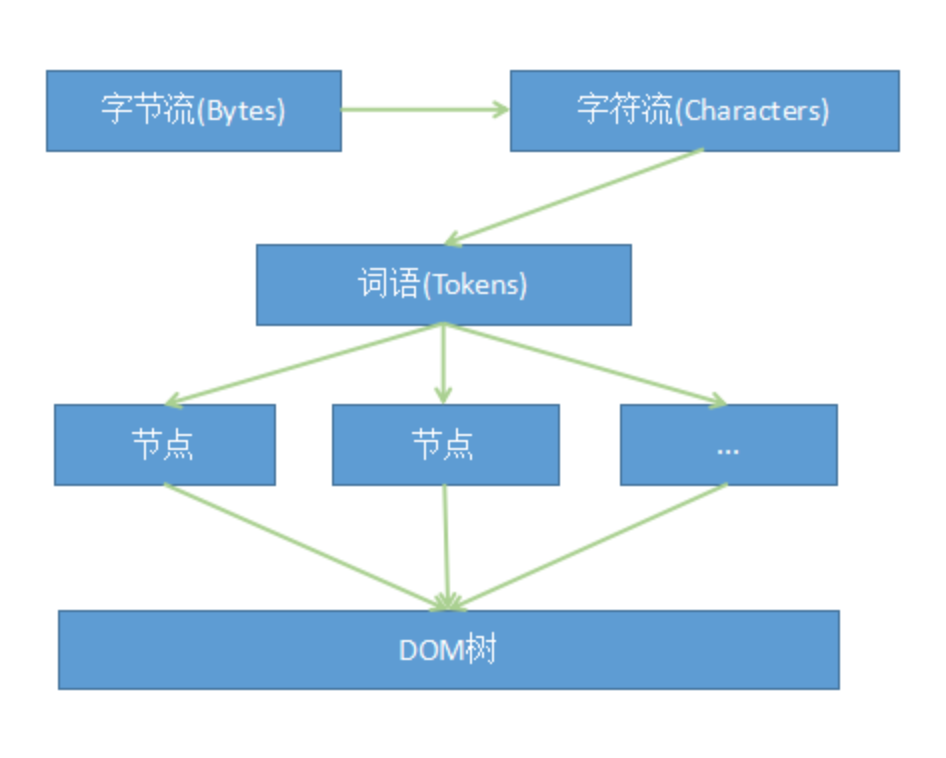
浏览器将返回的 html 文件数据帧,传入浏览器自带的 HTML 解释器,会有如下转换过程:
字节流 -> 字符流 -> 词法分析生成 token -> 语法分析构建 DOM 节点 -> DOM 树,并挂载 DOM 事件机制。
解释期间,以 webkit 为例:
-
当遇到
script或者link变迁,或者图片等需要请求远端资源的标签,便又发出建立TCP/IP连接请求,效率是比较低的,占用服务器资源较大。 -
会构造
frame,后构造document,前者是有Frame类实例化,后者是由HTMLDocument实例化来,他的父级也是Document类,里面还有XMLDocument类,来解析XML老的写法,frame包含document。
在构建 token 的期间,使用到的是 HTMLTokenizer 这个类,这个中有个 nextToken 方法,并内置了状态机,我们输入一段字符串,只要循环调用此方法,便会返回字符串中所有包含的 token,每次调用 nextToken 方法都会检查当前状态并做相应处理。
token 的词语类别大致分为
- DOCTYPE
- StartTag
- EndTag
- Comment
- Character
- EndOfFile 等
生成的 token 又会 经过 XSSauditor 类经过一层处理,防止部分不合法字符的注入。
token 生成完,浏览器开始构建 DOM 节点。
多次 TCP/IP 的建立,自然不难就看出 http 2.0 和 http 1 的差距,下面 是 http 2.0 和 http 1 的差别:
- 多路复用
多路复用 HTTP2虽然只有一条TCP连接,但是在逻辑上分成了很多stream。 HTTP2把要传输的信息分割成一个个二进制帧,首部信息会被封装到HEADER Frame,相应的request body就放到DATA Frame,一个帧你可以看成路上的一辆车,只要给这些车编号,让1号车都走1号门出,2号车都走2号门出,就把不同的http请求或者响应区分开来了。但是,这里要求同一个请求或者响应的帧必须是有有序的,要保证FIFO的,但是不同的请求或者响应帧可以互相穿插。这就是HTTP2的多路复用,充分利用了网络带宽,提高了并发度。
- 单一长连接
单一长连接在HTTP/2中,客户端向某个域名的服务器请求页面的过程中,只会创建一条TCP连接,即使这页面可能包含上百个资源。 单一的连接应该是HTTP2的主要优势,单一的连接能减少TCP握手带来的时延 。HTTP2中用一条单一的长连接,避免了创建多个TCP连接带来的网络开销,提高了吞吐量。
- 头部压缩和二进制格式
http1.x一直都是plain text,对此我只能想到一个优点,便于阅读和debug。但是,现在很多都走https,SSL也把plain text变成了二进制,那这个优点也没了。于是HTTP2搞了个HPACK压缩来压缩头部,减少报文大小(调试这样的协议将需要curl这样的工具,要进一步地分析网络数据流需要类似Wireshark的http2解析器)。
- 服务端推动Sever Push
这个功能通常被称作“缓存推送”。主要的思想是:当一个客户端请求资源X,而服务器知道它很可能也需要资源Z的情况下,服务器可以在客户端发送请求前,主动将资源Z推送给客户端。这个功能帮助客户端将Z放进缓存以备将来之需。
由此可以看出 http 2.0 更适合静态资源的请求与传输。
5. 开始构建 DOM 树
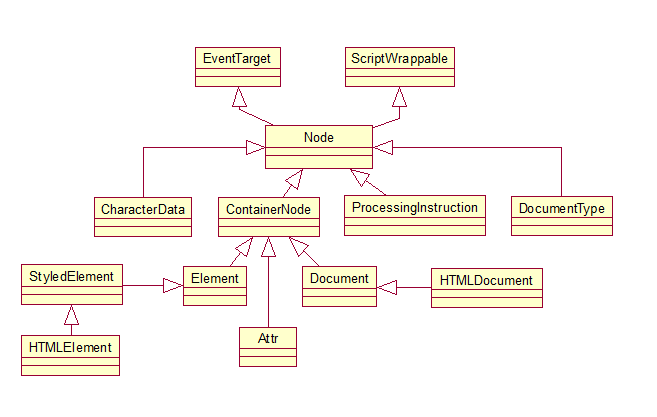
当我们拿到经过 xss 处理的 token 后,便可以开始构建 DOM 树,这时候会借助一个工具栈来进行,会把解析出来的 token 按照解析顺序放入栈中,入栈的 token 节点会先实例化成 DOM 节点,这时候会根据 token 类型,实例化一些基类,如 webkit 中 DOM 节点均继承 Node 基类,DOM 节点均有 Node 类中的 ContainerNode 类来制作,他会根据 token 类型(元素,属性,文本,文档等),来赋予节点对应的属性和方法,其中元素节点较为复杂,他们还会继承 HTMLElement 一个基类之外,还会根据特殊 token 来实例化特殊的类,如 HTMLImageElement,HTMLInputElement 等。
DOM 节点构造完成之后,DOM 节点之间的索引随着 DOM 节点的构造也一并关联起来,(通过栈),当传入对应 EndTag 的 token 便执行出栈操作,直到最后的 html 闭合标签 token 传入,整个 DOM 树便构建完成,可以看出构建 DOM 树也是一个深度优先的过程。
这里也可以看出,平级节点不可能同时出现在构造栈中。
以下是全部节点类型:
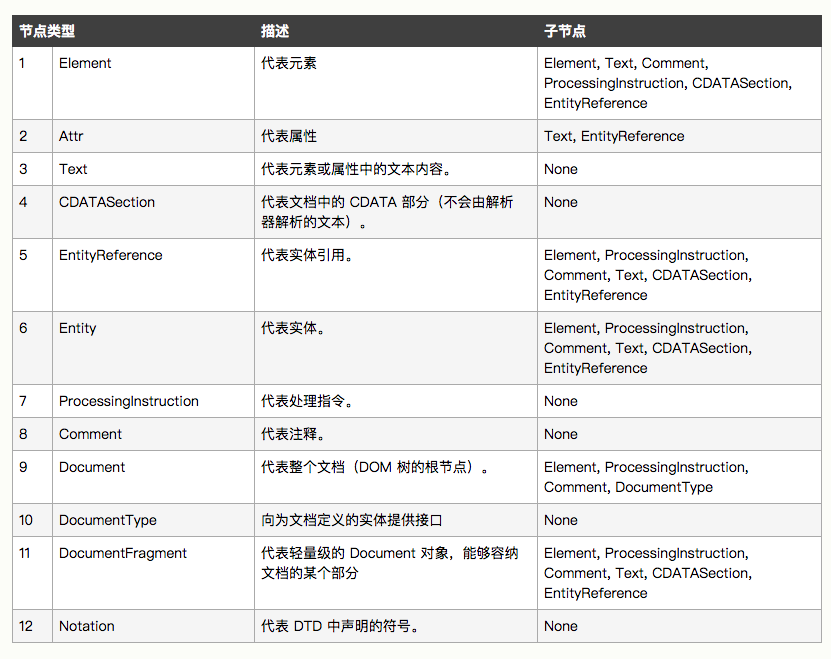
值得注意的是,DocumentFragment 也是一种文档类型,我们可以再常用的优化手段中看到他,目的是减少 DOM 操作次数。