Serving
 Serving copied to clipboard
Serving copied to clipboard
A flexible, high-performance carrier for machine learning models(『飞桨』服务化部署框架)

按 怎样保存用于Paddle Serving的模型 中的示例执行命令,得到了结果,结果如下;请问这个结果是正确的吗, ``` WARNING: Logging before InitGoogleLogging() is written to STDERR I0328 08:56:49.175515 275 naming_service_thread.cpp:202] brpc::policy::ListNamingService("127.0.0.1:9393"): added 1 I0328 08:56:49.247929 275 general_model.cpp:490] [client]logid=0,client_cost=60.714ms,server_cost=49.595ms. [3.24698885e-05 7.93178042e-05 9.62620034e-05 4.12459849e-05 3.98674856e-05...
在0.83版serving的安装目录paddle-serving-server/dag.py的22行定义的self.op_list = [ "GeneralInferOp", "GeneralReaderOp", "GeneralResponseOp", "GeneralTextReaderOp", "GeneralTextResponseOp", "GeneralSingleKVOp", "GeneralDistKVInferOp", "GeneralDistKVOp", "GeneralCopyOp", "GeneralDetectionOp", ] 以前版本定义的是字典格式,由于版本升级,的安装目录paddle-serving-server/pipeline/local_service_handler.py的285行-301行中的函数调用op_maker.create()仍按照字典方式调用引起错误。 修改方法: read_op = op_maker.create('GeneralReaderOp') general_infer_op = op_maker.create('GeneralInferOp') general_response_op = op_maker.create('GeneralResponseOp')
PaddleServingClientExample.java 我模仿了例子中的yolov4方法,预测一张图片, Client client = new Client(); client.setIP("127.0.0.1"); client.setPort("9292"); client.loadClientConfig(model_config_path); String result = client.predict(feed_data, fetch, true, 0); System.out.println(result); 我如何处理这里的result,目前我得到的是这样的数据,我如何转换成图片? outputs { tensor { int64_data: 0 int64_data: 0 int64_data: 0 int64_data:...
第一次使用GPU资源部署PaddleOCR,出现了一些问题,多次尝试无法解决后求助。 - 宿主机是`ubuntu20.04`,只安装了`nvidia`驱动,没有安装`cuda`和`cudnn`。 - 使用官方镜像:`registry.baidubce.com/paddlepaddle/serving:0.8.0-cuda11.2-cudnn8-runtime`。 出现如下问题: 1. 问题一(docker启动时):  2. 问题二(docker启动后,送入图片预测):  在容器中执行`nvidia-smi`  镜像里的安装包  部分dockerfile代码如下: ```dockerfile FROM registry.baidubce.com/paddlepaddle/serving:0.8.0-cuda11.2-cudnn8-runtime as serving ENV TZ=Asia/Shanghai RUN ln -s /usr/local/cuda/lib64/libcublas.so.11 /usr/lib/libcublas.so &&...
版本信息: paddleserving-gpu 版本 0.7.0.post.112 cuda版本11.4 问题描述: 我在使用paddleserving pipline部署时,配置文件配置使用gpu,但服务却没有使用我的gpu,于是我把配置文件改成使用cpu,服务启动资源占用情况和配置为gpu时启动一致。貌似配置文件配置使用设备不起作用? 以下是我的配置: ``` rpc_port: 18091 http_port: 9998 worker_num: 20 build_dag_each_worker: False dag: is_thread_op: False retry: 1 use_profile: False tracer: interval_s: 60 op: pre:...
各位先進跟大佬好 我照着官方教程並使用docker部署模型,遇到一個問題,就是啓動服務放一天預測,發現顯存會異常增長 ### 操作過程 ------------------------- 我用docker-compose建立image並run一個可以使用轉換過的模型進行預測的container ```Dockerfile FROM registry.baidubce.com/paddlepaddle/paddle:2.2.2-gpu-cuda10.2-cudnn7 RUN git clone https://github.com/PaddlePaddle/Serving RUN bash Serving/tools/paddle_env_install.sh RUN cd Serving && pip3 install -r python/requirements.txt RUN pip3 install paddle-serving-client==0.8.2 RUN pip3...
PaddleServingClientExample.java 里面使用的 io.paddle.serving.client.Client 没有setIP,setPort,loadClientConfig函数 jar包是paddle-serving-sdk-java-0.0.1.jar,顺便问一下有没有API地址
自己训练出HigherHRNet模型,成功导出模型,修改test_client.py也成功获得fetch_map,请问得到fetch_map之后如何获得检测结果,有示例吗?
### 使用pipeline 部署OCR模型,client是local predictor正常执行,选rpc报错 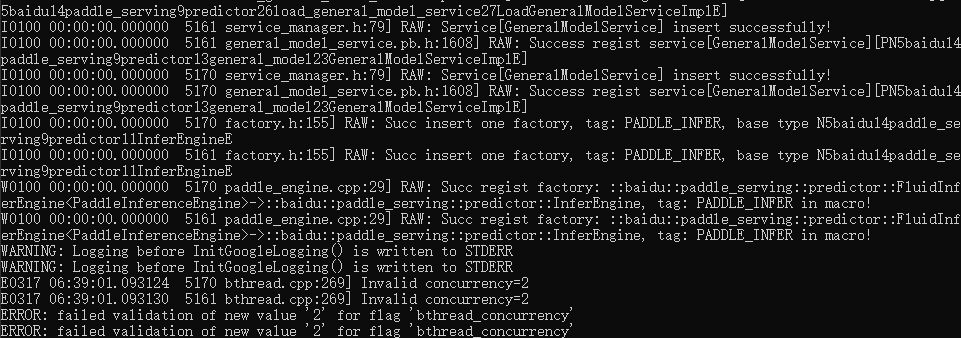 pipeline日志是这样  unknown client type grpc 版本是: -paddlepaddle==2.2.2, cpu -serving==0.7.0 系统环境是Win10上的linux docker
Metadata
Owner
Metadata
A flexible, high-performance carrier for machine learning models(『飞桨』服务化部署框架)