PaddleSeg
 PaddleSeg copied to clipboard
PaddleSeg copied to clipboard
Published
20 hours ago •
 PaddlePaddle
PaddlePaddle
vision transformer中输入图像的维度问题 [General Issue]
paddleseg2.5 paddlePaddle 2.1.0 Linux Python3.7 cuda11.2
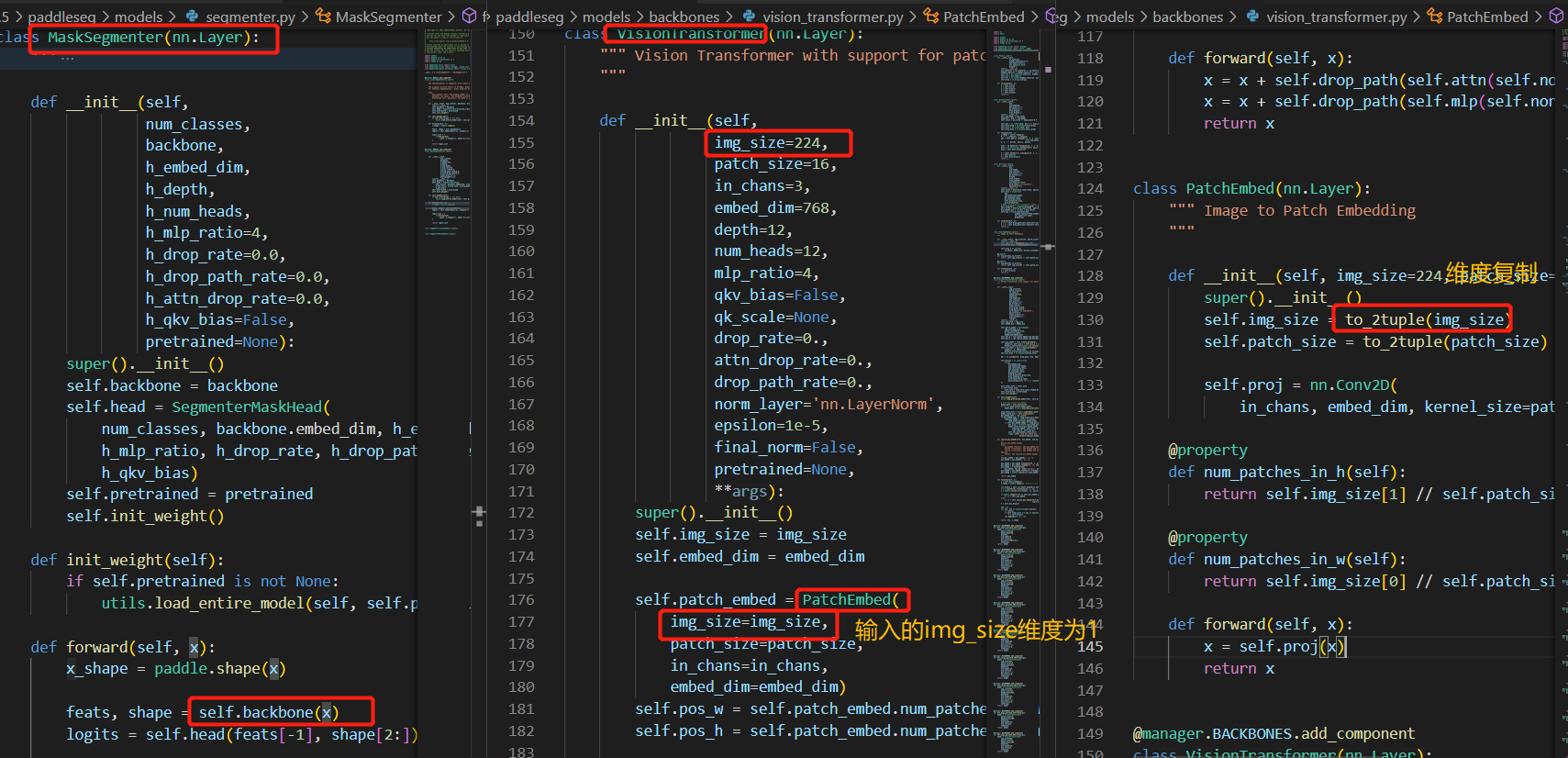
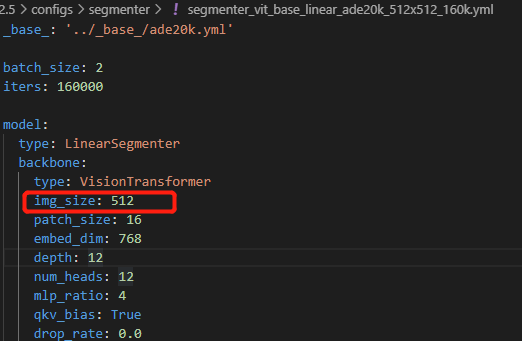
用VisionTransformer作为backbone,输入的图像宽高必须相等吗?
This issue has been automatically marked as stale because it has not had recent activity. It will be closed in 7 days if no further activity occurs. Thank you for your contributions.