PaddleOCR
 PaddleOCR copied to clipboard
PaddleOCR copied to clipboard
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and de...
印章弯曲文本识别

  小批量数据使用det_r50_db++_icdar15.yml,进行训练(使用的是ResNet50_dcn_asf_synthtext_pretrained.pdparams预训练模型),loss最终只能降到0.4左右,拿训练集直接进行评估的,recall和precision一直低于0.1,在配置文件部分也加了use_polygon: true该参数,标注格式如下(弯曲部分均采用16点或8点均匀标注,倾斜文本采用4点标注),想问一下如何解决该问题,完全达不到官方教程里光滑识别区域的效果。 
兼容 #7834 修改前的 ocr 函数:当参数 img 为非数组时返回非数组的结果。
场景介绍:增值税发票文本检测 1、首先使用ppocrLabel标注工具对数据进行标注(自动标注后,主要是将一些文字间距较大的字段的标注做修改,多个文本区域进行合并); 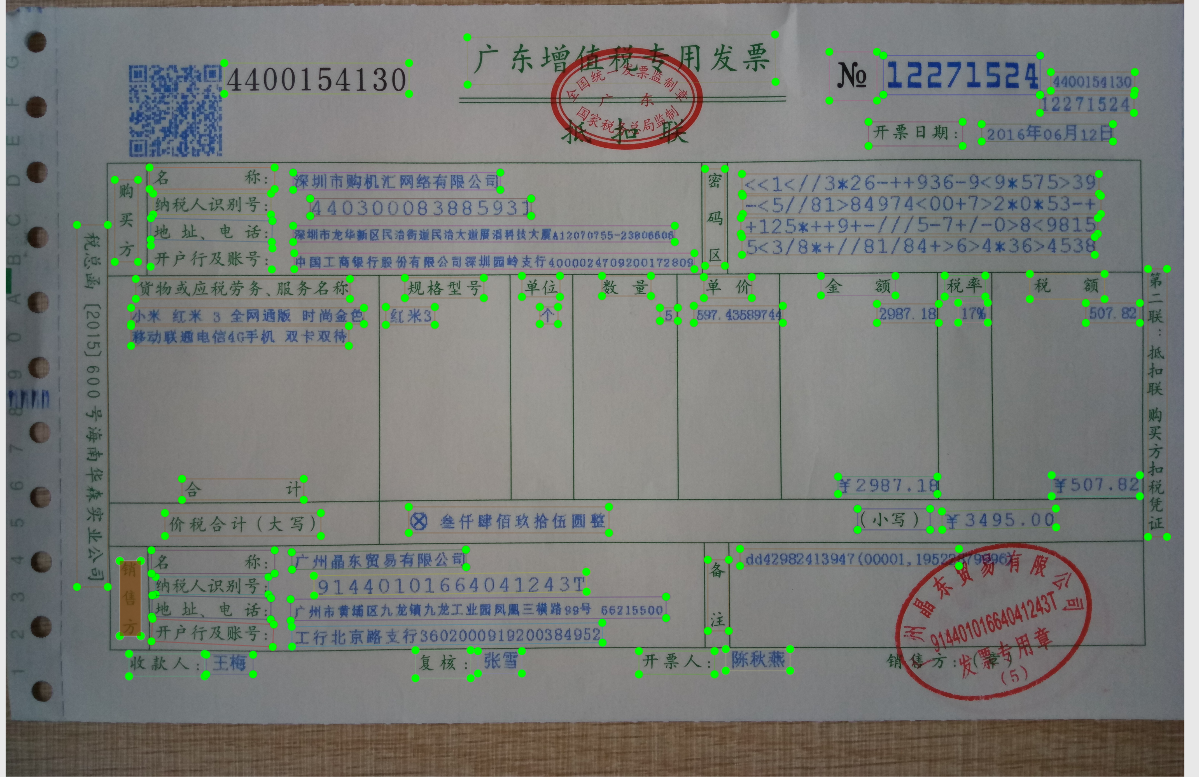 2、基于PPOCRv3轻量检测模型的finetune训练,训练精度非常低 - 系统环境/System Environment:ubuntu18.4,python3.7 - 版本号/Version:Paddle:2.2.0-gpu 使用ch_PP-OCRv3_det_distill_train的student预训练模型进行finetune - 运行指令: python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \ -o Global.pretrained_model=/home/models/pretrained_models/ch_PP-OCRv3_det_distill_train/student \ Global.save_model_dir=/home/models/train_models/det_models/ppv3 - 问题:训练精度随epoch增长逐渐降低   ...
请提供下述完整信息以便快速定位问题/Please provide the following information to quickly locate the problem - 系统环境/System Environment:Ubuntu - 版本号/Version:Paddle: PaddleOCR: 问题相关组件/Related components: - 运行指令/Command Code: - 完整报错/Complete Error Message:I can't extract Text Angle Classification...
请提供下述完整信息以便快速定位问题/Please provide the following information to quickly locate the problem - 系统环境/System Environment: ubuntu 18 - 版本号/Version: Paddle:2.3.0 PaddleOCR: 问题相关组件/Related components: 2.6.0.1 - 运行指令/Command Code: - from paddleocr import PPStructure...
训练V3版本是文字识别模型。 场景是身份证。 当前下载了部分开源的中文识别的数据集有200多万张。自己生成的中文数据集有40万张左右,标注好的真实身份证的图片有10万张左右。 用V3官方提供的中文推理模型测试身份证,有些不清晰的识别效果不好。因此使用了真实图片进行标注。 想使用ch_PP-OCRv3_rec_train/best_accuracy.pdparams 预训练模型进行finetune。 请问::使用官方的这个中文识别训练模型微调 ,应该是用以下那两种方法好呢? 1. 加入我找的这200万张开源中文数据集 ,然后将 ratio_list:设置成真实+生成 和 开源数据 1:1 2. 不需要加入我找的开源数据,直接使用生成的数据和真实数据进行finetune
SVTR配置文件
请问SVTR系列的small base large有配置文件,我看到只提供了tiny的,没有其他三个,如果我export_model时直接用tiny的配置文件导出其他三个模型会提示模型和预训练参数不一致。
车牌这类基本都是没有什么上下文的吧,下一个字符是什么完全不可预测。 像RNN或是SVTR这类真的有必要嘛,看intel做的LPRNet用了个简单的13*1的卷积直接代替了。 有用Paddle实现LPRNet的嘛
请提供下述完整信息以便快速定位问题/Please provide the following information to quickly locate the problem - 系统环境/System Environment:Ubuntu 18.04.5 - 版本号/Version:Paddle:gpu-2.3.0.post112 PaddleOCR:2.6.0.1 - 问题相关组件/Related components: 端到端弯曲印章中文文本识别-  - 运行指令/Command Code:python tools/train.py -c configs/e2e/e2e_r50_vd_pg.yml - 完整报错/Complete...
原有实现中,同名Module(paddleocr)下使用同名的Python主入口脚本(paddleocr.py),使用spawn多进程,在Python3.8触发ModuleNotFoundError的bug,该bug在测试环境(Python3.8.15 Paddle2.2.2 PaddleOCR2.6.0.1)可以稳定复现 CASE代码: ```python from paddleocr.ppstructure.predict_system import StructureSystem import multiprocessing def func( pid, ): print(f"[{pid}] Start") [_ for _ in range(int(1e6))] print(f"[{pid}] Finished") if __name__ == '__main__': with multiprocessing.Manager()...
Metadata
Owner
Metadata
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and de...