PaddleNLP
 PaddleNLP copied to clipboard
PaddleNLP copied to clipboard
👑 Easy-to-use and powerful NLP and LLM library with 🤗 Awesome model zoo, supporting wide-range of NLP tasks from research to industrial applications, including 🗂Text Classification, 🔍 Neural Searc...

版本、环境信息 1)PaddleNLP和PaddlePaddle版本:PaddleNLP 2.3.4,paddlepaddle-gpu 2.3.1.post116 2)系统环境:Windows10企业版,python38,cuda11.6,cudnn8.4 复现信息: *********** dataloader的数据类型为int64:'input_ids': Tensor(shape=[32, 90], dtype=int64, place=Place(gpu:0), stop_gradient=True 训练评估、裁剪、量化分别执行,其中训练和裁剪顺利执行 单独执行量化的时候有两种情况:paddle.static.InputSpec的dtype设置为int32时可顺利完成量化,其他则不行,配置如下 : input_spec = [ paddle.static.InputSpec(shape=[None, None], dtype="int64"), # input_ids paddle.static.InputSpec(shape=[None, None], dtype="int64") # segment_ids ]...
### PR types New features ### PR changes Models ### Description add tinybert unittest
欢迎您反馈PaddleNLP使用问题,非常感谢您对PaddleNLP的贡献!: - 版本、环境信息 1)PaddleNLP和PaddlePaddle版本:PaddleNLP,PaddlePaddle 使用的是docker直接部署:docker pull paddlecloud/paddlenlp:develop-cpu-latest 2)系统环境:系统类型:Linux,Python 3.7.13 启动训练脚本命令:python -m paddle.distributed.launch train.py --device cpu --dataset_dir ./data **问题:启动训练后,只能用CPU其中的一个核心进行训练,怎么使用多核心?** 系统CPU占用情况: 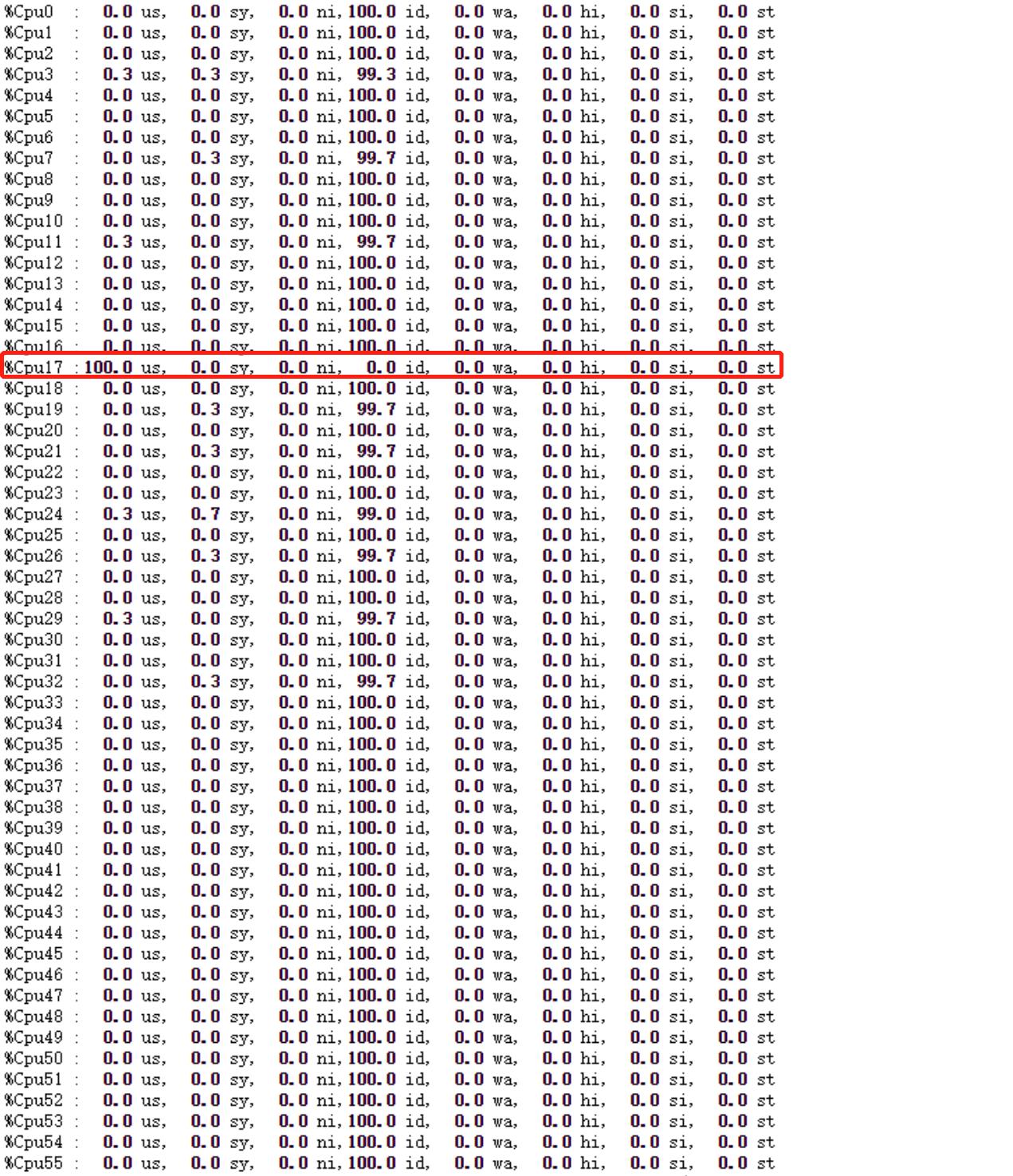
### PR types unittest ### PR changes Models ### Description Add unittest for RoBERTa
### PR types + New features ### PR changes + Models ### Description + Add text semantic matching for Taskflow
使用paddle2.3.1.post112/cuda11.2/3090显卡/paddlenlp2.3.4/Linux/python3.7环境复现SBert的时候,固定随机种子 paddle.seed(100) random.seed(100) np.random.seed(100) 并且使用FLAGS_cudnn_deterministic = True结果仍然不能复现,每次训练的acc指标都不能loss也不同; 同torch版本对比,在同一个数据集上(paws_x),同一个Bert预训练权重 bert-wwm-ext-chinese下: torch则可以复现,并且torch的acc为0.75(torch不设置随机种子的时候结果也是瞎飞),paddle的acc0.55-0.62之间随机出现; 请问是环境版本问题还是paddle框架问题还是我代码问题?怎么解决?
欢迎您反馈PaddleNLP使用问题,非常感谢您对PaddleNLP的贡献! 在留下您的问题时,辛苦您同步提供如下信息: - 版本、环境信息 1)PaddleNLP和PaddlePaddle版本: paddlenlp 2.3.4 paddlepaddle-gpu 2.3.0.post112 2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本 Linux CentOS7 python 3.9.7 有点怀疑模型参数可能哪里没有初始化好 PaddleNLP/examples/sentiment_analysis/skep/predict_sentence.py
 
 文档中https://paddlenlp.readthedocs.io/zh/latest/trainer.html?highlight=TrainingArguments#trainingarguments 说明可以不指定,应该是哪里赋值出了问题
按照这个文档 https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md#53-%E4%BA%8B%E4%BB%B6%E6%8A%BD%E5%8F%96 的描述,事件抽取需要标注实体类别以及关系,那么一些开源的数据是不是就无法使用了?比如下面这条数据: {"id": 7285, "text": "约翰逊(图:BBC)星岛环球网消息:【海外网4月6日|战疫全时区】据英国天空新闻网5日报道,英国首相约翰逊住院接受新冠病毒测试,10天前即3月27日他在社交媒体上发文称,自己新冠病毒检测结果呈阳性,正在自我隔离", "labels": [{"trigger": ["接受", 55], "object": ["英国首相约翰逊", 46], "subject": ["新冠病毒测试", 57], "time": "", "location": ""}], "distant_trigger": ["隔离", "测试", "接受", "检测"]} 这样的数据可以作为UIE的训练数据么?如果可以的话该怎么修改呢?
Metadata
Owner
Metadata
👑 Easy-to-use and powerful NLP and LLM library with 🤗 Awesome model zoo, supporting wide-range of NLP tasks from research to industrial applications, including 🗂Text Classification, 🔍 Neural Searc...