UIE 定制模型一键预测中Taskflow中batch_size参数没有作用
 这里的Taskflow中加入batch_size参数是没有作用的,抽取三条文本,batch_size=1和batch_size=3的效率是一样的,还测试了其他情况,都证明batch_size参数没有作用,gpu的利用率都是80%左右,gpu的显存利用率都是20%左右,请问这是为什么呢?
这里的Taskflow中加入batch_size参数是没有作用的,抽取三条文本,batch_size=1和batch_size=3的效率是一样的,还测试了其他情况,都证明batch_size参数没有作用,gpu的利用率都是80%左右,gpu的显存利用率都是20%左右,请问这是为什么呢?
利用率比较高,提升batch_size可能没有明显加速。可以试试能否用多进程spawn的方式来进一步提升利用率
好的好的,这边还有一个问题,UIE实体识别中每次取一个类别作为prompt与原文本拼接作为模型的输入,如果批量预测,batch_size=n, 是不是就同时加载n个模型进入内存进行任务提取呢?
批量预测的时候载入的还是单个模型,会根据schema的数量使用单个模型预测多次
这样的话batch_size肯定不会提高效率,实体识别中每次取一个类别作为prompt与原文本拼接作为模型的输入,所以schema中有多个实体类别时会预测多次,也就是说,预测的时候使用相同的数据集,Taskflow的batch_size参数无论设置多少,因为单个模型一次只能预测一个schema和一条文本,预测的效率都是相同的?
批量预测的时候载入的还是单个模型,会根据schema的数量使用单个模型预测多次
批量预测的时候,模型一次输入是批量的还是单条的呢?如果是批量的,硬件资源够的情况下,消耗的时间会比单条的多很多吗?还是几乎一样?
批量预测的时候输入是多条文本拼相同的prompt,可以参考下这里单阶段与多阶段预测的实现
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/deploy/python/uie_predictor.py
对应_single_stage_predict和_multi_stage_predict
批量预测时间消耗会多些,单阶段下的时间差异可以参考这里
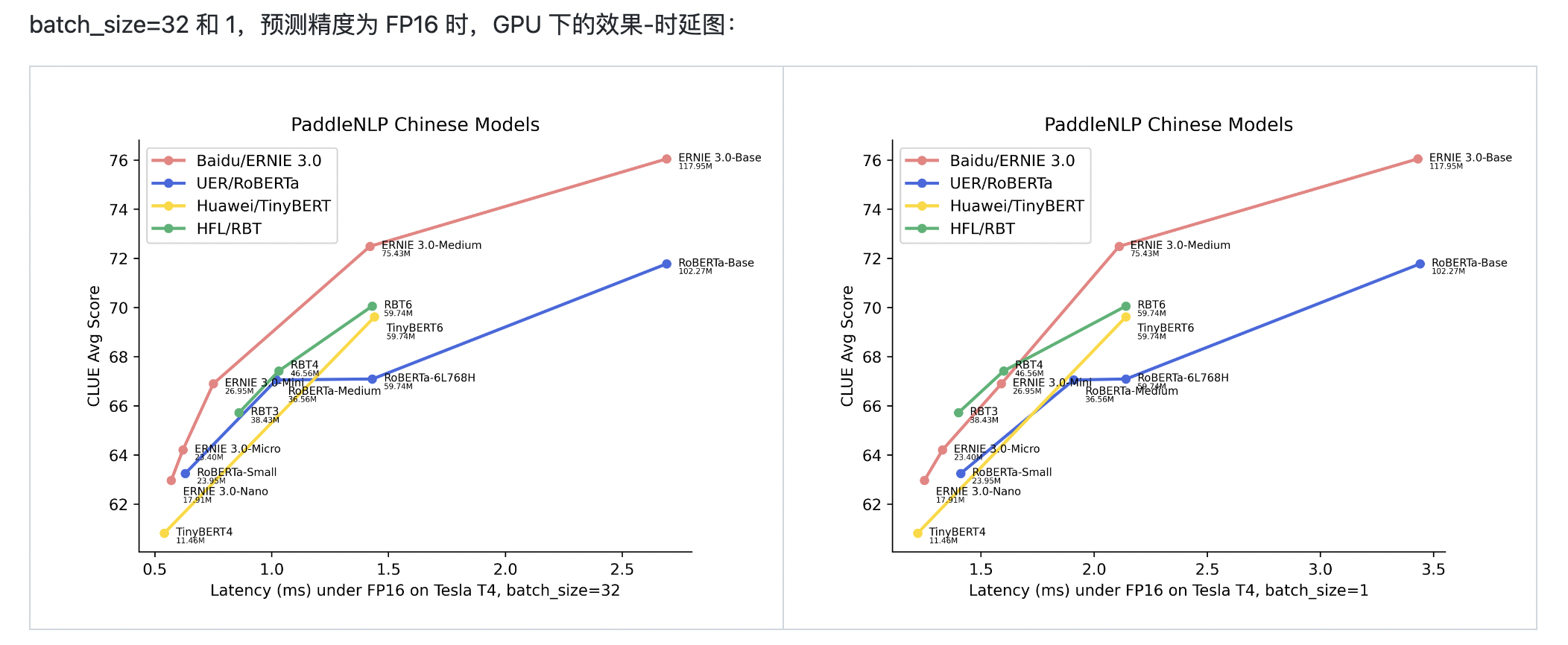
批量预测的时候输入是多条文本拼相同的prompt,可以参考下这里单阶段与多阶段预测的实现 https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/deploy/python/uie_predictor.py 对应_single_stage_predict和_multi_stage_predict 批量预测时间消耗会多些,单阶段下的时间差异可以参考这里
非常感谢您的解答,我现在的困惑是,UIE实体识别Taskflow中的batch_size参数对相同数量的任务处理能不能提高效率?意思就是硬件资源足够的情况下,n条文本,m个schema,batch_size=1和batch_size=8消耗的时间几乎是一样的吗?还是batch_size=8消耗的时间多或少?
这个我测过 batch_size=2和batch_size=32 64基本时间没差距,就是GPU内存使用率的问题。cpu拉过来的数据到GPU都是瞬间算完,影响预测时间主要卡在cpu到GPU这个过程
This issue is stale because it has been open for 60 days with no activity. 当前issue 60天内无活动,被标记为stale。
This issue was closed because it has been inactive for 14 days since being marked as stale. 当前issue 被标记为stale已有14天,即将关闭。