PaddleNLP
 PaddleNLP copied to clipboard
PaddleNLP copied to clipboard
关于readme中应用场景A:文本挖掘/解析模板生成与匹配 的问题
对于文本使用wordtag进行信息抽取后,如 生成readme中的 [作品类_实体][肯定词|是][人物类_实体][场景事件|执导][作品类_概念|电影]
对于这样的模板,我们应该如何进行对句子的匹配呢?readme中没有放实际的例子。
对于wordtag_ie中的set_schema,必须要有实体间的关系,但我们并不需要关系,word_tag也不会抽取关系。
我们如何在不涉及关系的前提下,对句子进行模板匹配,如[作品类_实体][肯定词|是][人物类_实体][场景事件|执导][作品类_概念|电影]
谢谢您

https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_to_knowledge 在这里 在readme 应用场景A 中
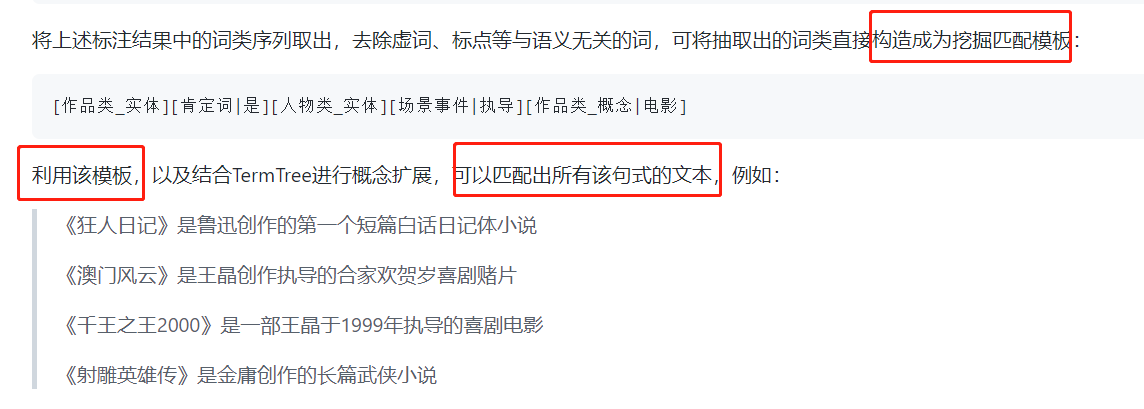
这里说利用该模板,可以匹配除所有该句式的文本。具体的方式没有给,是需要自己写吗
这个模板匹配需要自己写一下,相对来说比较简单,因为wordtag能抽取出来实体,只要通过简单判断实体是否匹配就行
ner = Taskflow('ner')
result = ner('xxxxx')
is_match = True
for type, template_type in zip(result, template)
if type != template_type:
is_match = False
break
This issue is stale because it has been open for 60 days with no activity. 当前issue 60天内无活动,被标记为stale。
This issue was closed because it has been inactive for 14 days since being marked as stale. 当前issue 被标记为stale已有14天,即将关闭。