PaddleDetection
 PaddleDetection copied to clipboard
PaddleDetection copied to clipboard
训练PaddleDetection仓库的ppyolo网络,loss=nan
bug描述 Describe the Bug
基于Paddle develop分支 - PaddleDetection develop分支, 以及Paddle release2.3分支 - PaddleDetection release2.4分支,跑ppyolo网络,无论是4卡还是8卡,均会有50%的概率出现 loss=nan。环境和超参数修改如下:
原生参数8卡参数为(base_lr: 0.01,batch_size: 24)
- 出现loss=nan的8卡参数和脚本
参数为(base_lr: 0.005,batch_size: 12),学习率和batch减半,训练脚本如下:
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml
git diff 如下:
diff --git a/configs/ppyolo/_base_/optimizer_1x.yml b/configs/ppyolo/_base_/optimizer_1x.yml
index 8e6301e..a419c52 100644
--- a/configs/ppyolo/_base_/optimizer_1x.yml
+++ b/configs/ppyolo/_base_/optimizer_1x.yml
@@ -1,7 +1,7 @@
-epoch: 405
+epoch: 50
LearningRate:
- base_lr: 0.01
+ base_lr: 0.005
schedulers:
- !PiecewiseDecay
gamma: 0.1
diff --git a/configs/ppyolo/_base_/ppyolo_reader.yml b/configs/ppyolo/_base_/ppyolo_reader.yml
index 1698539..2814cfa 100644
--- a/configs/ppyolo/_base_/ppyolo_reader.yml
+++ b/configs/ppyolo/_base_/ppyolo_reader.yml
@@ -17,7 +17,7 @@ TrainReader:
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
- Gt2YoloTarget: {anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]], anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], downsample_ratios: [32, 16, 8]}
- batch_size: 24
+ batch_size: 12
shuffle: true
drop_last: true
mixup_epoch: 25000
- 出现loss=nan的4卡参数和脚本
参数为(base_lr: 0.0025,batch_size: 12),学习率和batch减半,训练脚本如下:
python -m paddle.distributed.launch --gpus 0,1,2,3 tools/train.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml
git diff 如下:
diff --git a/configs/ppyolo/_base_/optimizer_1x.yml b/configs/ppyolo/_base_/optimizer_1x.yml
index 8e6301e32..f96dff742 100644
--- a/configs/ppyolo/_base_/optimizer_1x.yml
+++ b/configs/ppyolo/_base_/optimizer_1x.yml
@@ -1,7 +1,7 @@
-epoch: 405
+epoch: 15
LearningRate:
- base_lr: 0.01
+ base_lr: 0.0025
schedulers:
- !PiecewiseDecay
gamma: 0.1
diff --git a/configs/ppyolo/_base_/ppyolo_reader.yml b/configs/ppyolo/_base_/ppyolo_reader.yml
index 1698539af..2814cfa9f 100644
--- a/configs/ppyolo/_base_/ppyolo_reader.yml
+++ b/configs/ppyolo/_base_/ppyolo_reader.yml
@@ -17,7 +17,7 @@ TrainReader:
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
- Gt2YoloTarget: {anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]], anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], downsample_ratios: [32, 16, 8]}
- batch_size: 24
+ batch_size: 12
shuffle: true
drop_last: true
mixup_epoch: 25000
报错信息如下:
[09/20 20:33:24] ppdet.engine INFO: Epoch: [4] [1960/2443] learning_rate: 0.002500 loss_xy: 4.929123 loss_wh: 6.653260 loss_iou: 17.435518 loss_iou_aware: 3.315290 loss_obj: 37.247818 loss_cls: 20.935398 loss: 89.923317 eta: 6:41:38 batch_cost: 0.9275 data_cost: 0.0547 ips: 12.9386 images/s
[09/20 20:33:44] ppdet.engine INFO: Epoch: [4] [1980/2443] learning_rate: 0.002500 loss_xy: 5.024055 loss_wh: 6.127202 loss_iou: 17.634968 loss_iou_aware: 3.545506 loss_obj: 38.444519 loss_cls: 22.425531 loss: 97.338821 eta: 6:41:19 batch_cost: 0.9750 data_cost: 0.0003 ips: 12.3075 images/s
[09/20 20:34:05] ppdet.engine INFO: Epoch: [4] [2000/2443] learning_rate: 0.002500 loss_xy: 4.801731 loss_wh: 6.628194 loss_iou: 17.139820 loss_iou_aware: 3.319241 loss_obj: 38.700241 loss_cls: 22.693611 loss: 93.608757 eta: 6:40:59 batch_cost: 0.9674 data_cost: 0.0006 ips: 12.4038 images/s
[09/20 20:34:26] ppdet.engine INFO: Epoch: [4] [2020/2443] learning_rate: 0.002500 loss_xy: 4.418971 loss_wh: 5.848875 loss_iou: 15.264145 loss_iou_aware: 2.959143 loss_obj: 34.033241 loss_cls: 18.832973 loss: 79.911163 eta: 6:40:41 batch_cost: 0.9842 data_cost: 0.0003 ips: 12.1927 images/s
[09/20 20:34:46] ppdet.engine INFO: Epoch: [4] [2040/2443] learning_rate: 0.002500 loss_xy: 4.705611 loss_wh: 5.466923 loss_iou: 15.579102 loss_iou_aware: 3.252701 loss_obj: 36.642715 loss_cls: 22.718971 loss: 90.127289 eta: 6:40:20 batch_cost: 0.9489 data_cost: 0.0003 ips: 12.6465 images/s
[09/20 20:35:05] ppdet.engine INFO: Epoch: [4] [2060/2443] learning_rate: 0.002500 loss_xy: nan loss_wh: nan loss_iou: nan loss_iou_aware: nan loss_obj: nan loss_cls: nan loss: nan eta: 6:39:59 batch_cost: 0.9237 data_cost: 0.2108 ips: 12.9917 images/s
[09/20 20:35:26] ppdet.engine INFO: Epoch: [4] [2080/2443] learning_rate: 0.002500 loss_xy: nan loss_wh: nan loss_iou: nan loss_iou_aware: nan loss_obj: nan loss_cls: nan loss: nan eta: 6:39:41 batch_cost: 0.9857 data_cost: 0.2855 ips: 12.1743 images/s
其他补充信息 Additional Supplementary Information
No response
您好,我们已经收到了您的问题,会安排技术人员尽快解答您的问题,请耐心等待。请您再次检查是否提供了清晰的问题描述、复现代码、环境&版本、报错信息等。同时,您也可以通过查看官网API文档、常见问题、历史Issue、AI社区来寻求解答。祝您生活愉快~
Hi! We've received your issue and please be patient to get responded. We will arrange technicians to answer your questions as soon as possible. Please make sure that you have posted enough message to demo your request. You may also check out the API,FAQ,Github Issue and AI community to get the answer.Have a nice day!
paddle版本可以试试稍低一点比如paddle2.2.2。推荐原配置训练,如果资源不够bs开不到默认,的确是按默认总bs线型比例调整lr,但也可以试试其他lr,尽量往小点调。 最新PP-YOLOE系列是PP-YOLOE+,精度速度均有大幅度提升,欢迎使用 https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/configs/ppyoloe 检测问题也可到PaddleDetection提问,https://github.com/PaddlePaddle/PaddleDetection/issues
我在PaddleDetection仓库中open issue中发现,只要涉及到修改学习率,好多都会报 loss nan的问题。比如这些都是ppyolo系列出现的loss_nan的问题: https://github.com/PaddlePaddle/PaddleDetection/issues/6093 https://github.com/PaddlePaddle/PaddleDetection/issues/3006 https://github.com/PaddlePaddle/PaddleDetection/issues/2944
@qipengh 1. 修改batch_size或者卡数,需要调整学习率,具体计算公式为
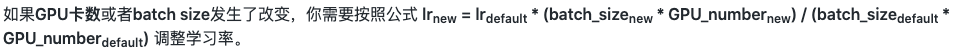 2. 如果你正常修改了学习率依然报错,可以考虑在optimizer中 https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/configs/ppyolo/base/optimizer_1x.yml#L15
添加一行
2. 如果你正常修改了学习率依然报错,可以考虑在optimizer中 https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/configs/ppyolo/base/optimizer_1x.yml#L15
添加一行
clip_grad_by_norm: 35.
类似 https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/configs/ppyolo/base/optimizer_365e.yml#L14
@wangxinxin08 ,我在A100 8卡机器上,环境:Paddle develop分支 - PaddleDetection develop分支,Cuda-11.2,基于原生参数(不改学习率和batch)from_scratch 训练,发现会有将近 50 % 的概率会报 loss = nan。可否麻烦你们复现下?
添加了这个参数clip_grad_by_norm: 35.后,压测暂时还没发现什么问题。
@qipengh clip_grad_by_norm就是解决出nan的办法,ppyolo有时候会出nan,我们在ppyolov2中默认使用clip_grad_by_norm,ppyolo之后也会把这个参数默认加上